上披露有關 Hopper GPU 和 Grace CPU 的新細節
« 新聞稿 »
NVIDIA 將分享有關 Grace CPU、Hopper GPU、NVLink Switch 的新細節, Hot Chips 上的 Jetson Orin 模塊
最新的芯片設計反映了 NVIDIA 在 AI、邊緣和高性能計算方面的平台創新的廣度和深度。
在兩天的四次會談中,NVIDIA 資深人士工程師將描述網絡邊緣的現代數據中心和系統的加速計算創新。
在虛擬熱芯片活動(處理器和系統架構師的年度聚會)上發表講話,他們將披露性能數據以及 NVIDIA 的第一個服務器 CPU、Hopper GPU、最新版本的 NVSwitch 互連芯片和 NVIDIA Jetson Orin 系統級模塊 (SoM) 的其他技術細節。
這些演示文稿提供了新的見解s 關於 NVIDIA 平台將如何達到性能、效率、規模和安全性的新水平。
具體而言,會談展示了一種設計理念,即在 GPU、CPU 的整個芯片、系統和軟件堆棧中進行創新DPU 充當對等處理器。他們共同創建了一個平台,該平台已經在雲服務提供商、超級計算中心、企業數據中心和自治系統中運行人工智能、數據分析和高性能計算工作。
在 NVIDIA 的第一個服務器 CPU 內部
數據中心需要靈活的 CPU、GPU 和其他加速器集群來共享大量內存池,以提供當今工作負載所需的節能性能。
為了滿足這一需求,Jonathon Evans,一位傑出的工程師和 15-在 NVIDIA 工作了一年的資深人士,將介紹 NVIDIA NVLink-C2C。它以每秒 900 GB 的速度連接 CPU 和 GPU,其能效是現有 PCIe Gen 5 標準的 5 倍,這要歸功於每比特僅消耗 1.3 皮焦耳的數據傳輸。
NVLink-C2C 將兩個 CPU 芯片連接到創建具有 144 個 Arm Neoverse 內核的 NVIDIA Grace CPU。這是一款專為解決世界上最大的計算問題而設計的處理器。
為了實現最高效率,Grace CPU 使用 LPDDR5X 內存。它支持每秒 TB 的內存帶寬,同時將整個綜合體的功耗保持在 500 瓦。
一個鏈接,多種用途
NVLink-C2C 還鏈接 Grace CPU 和 Hopper GPU芯片作為 NVIDIA Grace Hopper 超級芯片中的內存共享對等體,為 AI 訓練等需要性能的工作提供最大的加速。
任何人都可以使用 NVLink-C2C 構建自定義小芯片,以連貫地連接到 NVIDIA GPU、CPU 、DPU 和 SoC,擴展了這一新型集成產品。該互連將分別支持 Arm 和 x86 處理器使用的 AMBA CHI 和 CXL 協議。
Grace 和 Grace Hopper 的首個內存基準測試。
為了在系統級別進行擴展,新的 NVIDIA NVSwitch 連接了多個服務器集成到一台 AI 超級計算機中。它使用 NVLink,以每秒 900 GB 的速度運行的互連,是 PCIe Gen 5 帶寬的 7 倍以上。
NVSwitch 讓用戶可以將 32 個 NVIDIA DGX H100 系統鏈接到 AI 超級計算機中,從而提供 exaflop 的峰值 AI 性能.
Alexander Ishii 和 Ryan Wells 都是 NVIDIA 的資深工程師,他們將描述該交換機如何讓用戶構建具有多達 256 個 GPU 的系統,以處理要求苛刻的工作負載,例如訓練具有超過 1 萬億個參數的 AI 模型。
該開關包括使用 NVIDIA Scalable Hierarchical Aggregation Reduction Protocol 加速數據傳輸的引擎。 SHARP 是一種在 NVIDIA Quantum InfiniBand 網絡上首次亮相的網絡內計算功能。它可以使通信密集型 AI 應用程序的數據吞吐量翻倍。
NVSwitch 系統支持 exaflop 級 AI 超級計算機。
在公司工作 14 年的高級傑出工程師 Jack Choquette 將詳細介紹 NVIDIA H100 Tensor Core GPU,又名 Hopper。
除了使用新的互連擴展至前所未有的高度之外,它還包含許多可提高加速器性能、效率和安全性的高級功能。
Hopper 的新 Transformer 引擎和升級後的 Tensor Core 與上一代使用世界上最大的神經網絡模型的 AI 推理相比,速度提高了 30 倍。它採用世界上第一個 HBM3 內存系統來提供高達 3 TB 的內存帶寬,這是 NVIDIA 有史以來最大的世代增長。
在其他新功能中:
Hopper 增加了對多租戶的虛擬化支持,多用戶配置。新的 DPX 指令加快了選擇映射、DNA 和蛋白質分析應用程序的重複循環。 Hopper 支持通過機密計算增強安全性。
Choquette 是其職業生涯早期 Nintendo64 遊戲機的主要芯片設計師之一,他還將介紹 Hopper 的一些進步背後的並行計算技術。
Michael在公司任職 17 年的架構經理 Ditty 將為邊緣 AI、機器人和高級自主機器的引擎 NVIDIA Jetson AGX Orin 提供新的性能規格。
它集成了 12 個 Arm Cortex-A78 內核和 NVIDIA Ampere 架構 GPU,可在 AI 推理作業上提供高達每秒 275 萬億次操作。與上一代產品相比,性能提高了 8 倍,能效提高了 2.3 倍。
最新的生產模塊包含高達 32 GB 的內存,並且是可縮小到袖珍型 5W 的兼容系列的一部分Jetson Nano 開發者工具包。
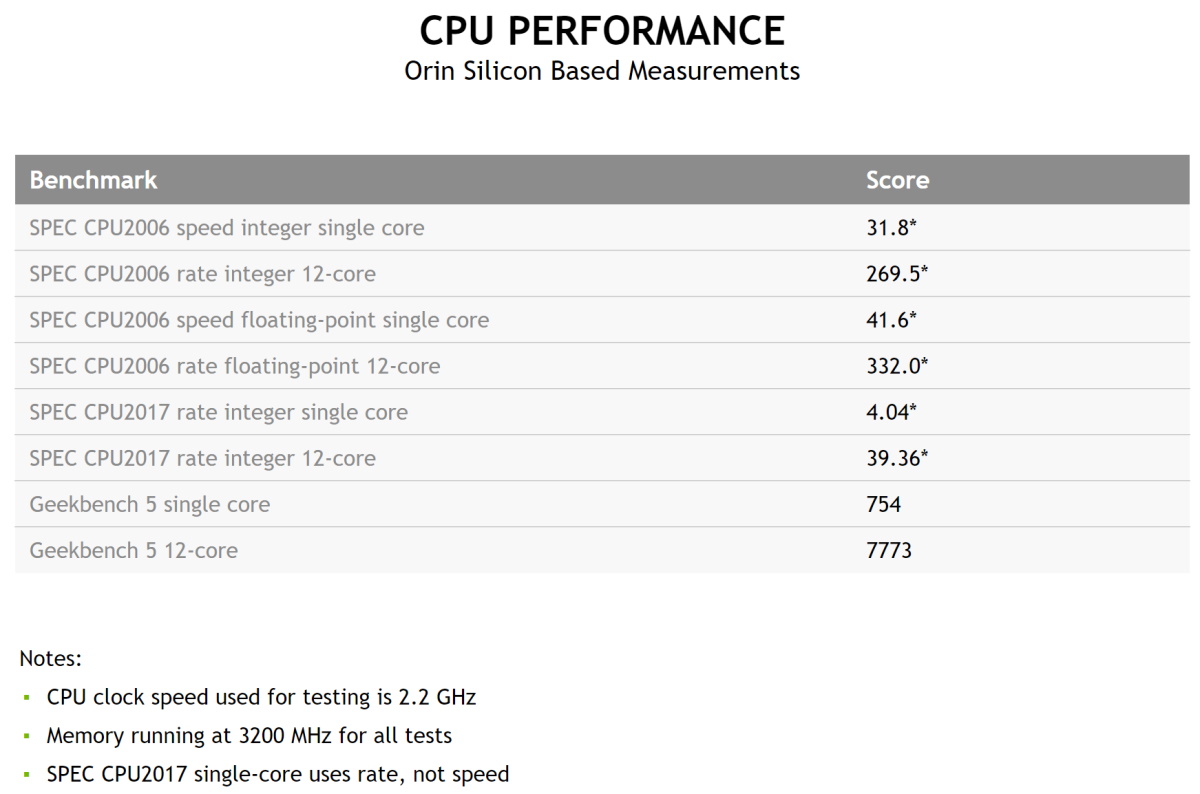
NVIDIA Orin 的性能基準測試
所有新芯片都支持 NVIDIA 軟件堆棧,可加速 700 多個應用程序並被 250 萬開發人員使用。
基於 CUDA 編程模型,它包括數十個面向汽車 (DRIVE) 和醫療保健 (Clara) 等垂直市場的 NVIDIA SDK,以及推薦系統 (Merlin) 和對話式 AI (Riva) 等技術。
NVIDIA AI 平台是可從各大雲服務和系統製造商處獲得。
來源:NVIDIA
« 新聞稿結束輕鬆 »


{kind=link}
{kind=link}
{kind=link}
{kind=link}