.fb-comments,.fb-comments span,.fb-comments span iframe[style]{min-width:100%!important;width:100%!important} 由 Maxim Tabachnyk 發布, 資深軟件工程師和 Stoyan Nikolov,Google Research 高級工程經理
代碼的日益複雜性對軟件工程的生產力提出了關鍵挑戰。 代碼完成一直是一個重要的工具,它有助於減輕 集成開發環境 (IDE)。按照慣例,代碼補全建議是使用基於規則的 語義引擎 (SE) 實現的,這些引擎通常具有訪問權限到完整的存儲庫並了解其語義結構。最近的研究表明,大型語言模型(例如,Codex 和 PaLM)可以實現更長、更複雜的代碼建議,並因此出現了有用的產品(例如,Copilot)。但是,除了 感知生產力和接受的建議,保持開放。
今天我們描述了我們如何將 ML 和 SE 結合起來開發一種新穎的基於 Transformer 的混合語義 ML 代碼完成,現在可供 Google 內部開發人員使用。我們討論如何通過以下方式組合 ML 和 SE:(1)使用 ML 重新排列 SE 單標記建議,(2)使用 ML 應用單行和多行完成並使用 SE 檢查正確性,或(3)使用單和通過 ML 對單標記語義建議進行多行延續。我們將 10k+ 名 Google 員工(使用 8 種編程語言在三個月內)的混合語義 ML 代碼完成與對照組進行比較,發現編碼迭代時間(構建和測試之間的時間)減少了 6%,上下文切換減少了 7%(即,離開 IDE)當暴露於單行 ML 完成時。這些結果表明,ML 和 SE 的結合可以提高開發人員的生產力。目前,3% 的新代碼(以字符為單位)現在是通過接受 ML 完成建議生成的。
Transformers for Completion
一種常見的代碼完成方法是訓練 Transformer 模型,它使用 self-attention 用於語言理解的機制,以實現代碼理解和完成預測。我們處理類似於語言的代碼,用子詞標記和 SentencePiece 詞彙表表示,並使用編碼器-解碼器在 TPU 上運行的變形金剛模型以進行完成預測。輸入是光標周圍的代碼(~1000-2000 個標記),輸出是一組完成當前行或多行的建議。序列是通過解碼器上的光束搜索(或樹探索)生成的。
在 Google 的 monorepo 訓練期間,我們屏蔽掉了一行的剩餘部分和一些後續行,以模仿正在積極開發的代碼。我們在八種語言(C++、Java、Python、Go、Typescript、Proto、Kotlin 和 Dart)上訓練了一個模型,並觀察到所有語言的性能改進或相同,無需專用模型。此外,我們發現約 0.5B 參數的模型大小可以很好地權衡高預測精度、低延遲和資源成本。該模型極大地受益於 monorepo 的質量,該質量由指南和審查強制執行。對於多行建議,我們迭代地應用具有學習閾值的單行模型來決定是否開始預測下一行的完成情況。

使用 ML 重新排列單個令牌建議
當用戶在 IDE 中鍵入時,ML 模型和 SE 同時在後端交互地請求代碼完成。 SE 通常只預測單個令牌。我們使用的 ML 模型預測多個標記直到行尾,但我們只考慮第一個標記來匹配來自 SE 的預測。我們確定了 SE 建議中也包含的前三個 ML 建議,並將它們的排名提升到了首位。然後,重新排序的結果會在 IDE 中顯示為用戶的建議。
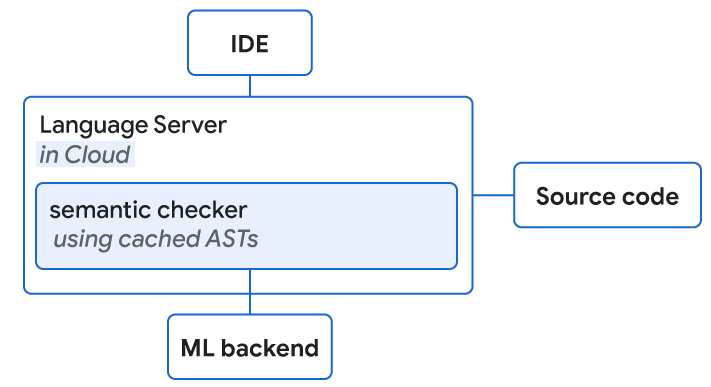
實際上,我們的 SE 在雲中運行,提供開發人員熟悉的語言服務(例如語義完成、診斷等),因此我們將 SE 配置在相同的位置上運行作為執行 ML 推理的 TPU。 SE 基於一個內部庫,該庫提供類似編譯器的低延遲特性。由於設計設置,請求是並行完成的,而 ML 通常可以更快地提供服務(中位數約為 40 毫秒),我們不會為完成添加任何延遲。我們觀察到實際使用中的質量顯著提高。對於 28% 的接受完成,完成的排名由於提升而更高,在 0.4% 的情況下更差。此外,我們發現用戶在接受完成建議之前輸入的字符數減少了 10% 以上。
檢查單行/多行 ML 完成的語義正確性
在推理時,ML 模型通常不知道其輸入窗口之外的代碼,並且在訓練期間看到的代碼可能會錯過最近的代碼在積極更改的存儲庫中完成所需的添加。這導致了 ML 驅動的代碼完成的一個常見缺點,即模型可能會建議看起來正確但無法編譯的代碼。根據內部用戶體驗研究,隨著時間的推移,此問題會導致用戶信任度下降,同時降低生產力收益。
我們使用 SE 在給定的延遲預算內執行快速語義正確性檢查(端到端完成<100ms)並使用緩存的抽象語法樹以實現“完整”的結構理解。典型的語義檢查包括引用解析(即,該對像是否存在)、方法調用檢查(例如,確認使用正確數量的參數調用方法)和可分配性檢查(確認類型是否符合預期)。
例如,對於編碼語言 Go,~8 % 的建議在語義檢查之前包含編譯錯誤。然而,語義檢查的應用過濾掉了 80% 的不可編譯的建議。在加入該功能的前六週,單行完成的接受率提高了 1.9 倍,這可能是由於用戶信任度的提高。作為比較,對於我們沒有添加語義檢查的語言,我們只看到接受度增加了 1.3 倍。
結果
在 1 萬多名 Google 內部開發人員使用他們的 IDE 中的完成設置時,我們測得用戶接受率為 25-34%。我們確定基於轉換器的混合語義 ML 代碼完成完成了超過 3% 的代碼,同時將 Google 員工的編碼迭代時間減少了 6%(在 90% 的置信度下)。轉變的大小對應於觀察到的轉換特徵(例如,關鍵框架)的典型影響,這些特徵通常只影響一個子群體,而 ML 有可能推廣到大多數主要語言和工程師。
在探索 API 的同時提供長補全
我們還將語義補全與全行補全緊密集成。當出現帶有語義單標記完成的下拉菜單時,我們會顯示從 ML 模型返回的單行完成。後者代表作為下拉焦點的項目的延續。例如,如果用戶查看 API 的可能方法,則內聯完整行完成顯示完整的方法調用還包含調用的所有參數。


結論和未來的工作
我們展示瞭如何結合使用基於規則的語義引擎和大型語言模型來顯著提高開發人員的工作效率和更好的代碼完成度。作為下一步,我們希望通過在推理時向 ML 模型提供額外信息來進一步利用 SE。一個例子是在 ML 和 SE 之間來回進行長預測,其中 SE 迭代檢查正確性並為 ML 模型提供所有可能的延續。在添加由 ML 提供支持的新功能時,我們要注意超越“智能”結果,但要確保對生產力產生積極影響。
致謝
這項研究是 Google Core 和 Google Research, Brain Team 兩年合作的成果。特別感謝 Marc Rasi、Yurun Shen、Vlad Pchelin、Charles Sutton、Varun Godbole、Jacob Austin、Danny Tarlow、Benjamin Lee、Satish Chandra、Ksenia Korovina、Stanislav Pyatykh、Cristopher Claeys、Petros Maniatis、Evgeny Gryaznov、Pavel Sychev、Chris Gorgolewski , Kristof Molnar, Alberto Elizondo, Ambar Murillo, Dominik Schulz, David Tattersall, Rishabh Singh, Manzil Zaheer, Ted Ying, Juanjo Carin, Alexander Froemmgen 和 Marcus Revaj。
評價這篇文章
分享是關愛!
Related Posts


IT Info
PS VR2 在兩個月內售出 60 萬台
根據索尼互動娛樂公司 CEO Jim Ryan 最近發布的一份 PDF 文件顯示,索尼的 PS VR2 耳機實際上做得很好,顯示了耳機發布後的銷售情況
IT Info
Opera 使用自己的瀏覽器 AI 與 Microsoft Edge 較量
人工智能正在接管世界,網絡也不例外。微軟和谷歌已經用 AI 為他們的瀏覽器提供動力,現在 Opera......