
NVIDIA macht möglicherweise seine schnellste GPU, den Ampere A100, mit doppelter Speicherkapazität und rekordverdächtiger Speicherbandbreite noch schneller. Dies wird durch NVIDIAs eigene Auflistung bestätigt, die von Videocardz.
NVIDIAs schnellste GPU, der Ampere A100, wird schneller mit doppeltem Speicher und höherer HBM2e-Bandbreite
Der vorhandene NVIDIA A100 HPC-Beschleuniger wurde letztes Jahr im Juni eingeführt und es sieht so aus, als ob das grüne Team plant, ihm ein umfangreiches Spezifikations-Upgrade zu verpassen. Der Chip basiert auf NVIDIAs größter Ampere-GPU, dem A100, der 826 mm2 misst und wahnsinnige 54 Milliarden Transistoren beherbergt. NVIDIA gibt seinen HPC-Beschleunigern in der Mitte des Zyklus einen Spezifikationsschub, was bedeutet, dass wir auf der GTC 2022 von den Beschleunigern der nächsten Generation hören werden.
In Bezug auf die Spezifikationen, an der Kernkonfiguration ändert der A100 PCIe GPU-Beschleuniger nicht viel. Die GA100 GPU behält die Spezifikationen bei, die wir bei der 400-W-Variante mit 6912 CUDA-Kernen, die in 108 SM-Einheiten angeordnet sind, 432 Tensor-Kernen und 80 GB HBM2e-Speicher mit einer höheren Bandbreite von 2,0 TB/s im Vergleich zu 1,55 TB/s auf die 40-GB-Variante.

Ein Bild des NVIDIA GA100-Chips.
Die A100 SMX-Variante ist bereits mit 80 GB Speicher ausgestattet, verfügt aber nicht über die schnelleren HBM2e-Dies wie diese kommende A100 PCIe-Variante. Dies ist auch die größte Speicherkapazität, die jemals auf einer PCIe-basierten Grafikkarte bereitgestellt wurde. Erwarten Sie jedoch nicht, dass Consumer-Grafikkarten in absehbarer Zeit so hohe Kapazitäten aufweisen. Interessant ist, dass die Nennleistung unverändert bleibt, was bedeutet, dass wir nach Chips mit höherer Dichte suchen, die für Hochleistungsanwendungsfälle gebind sind.
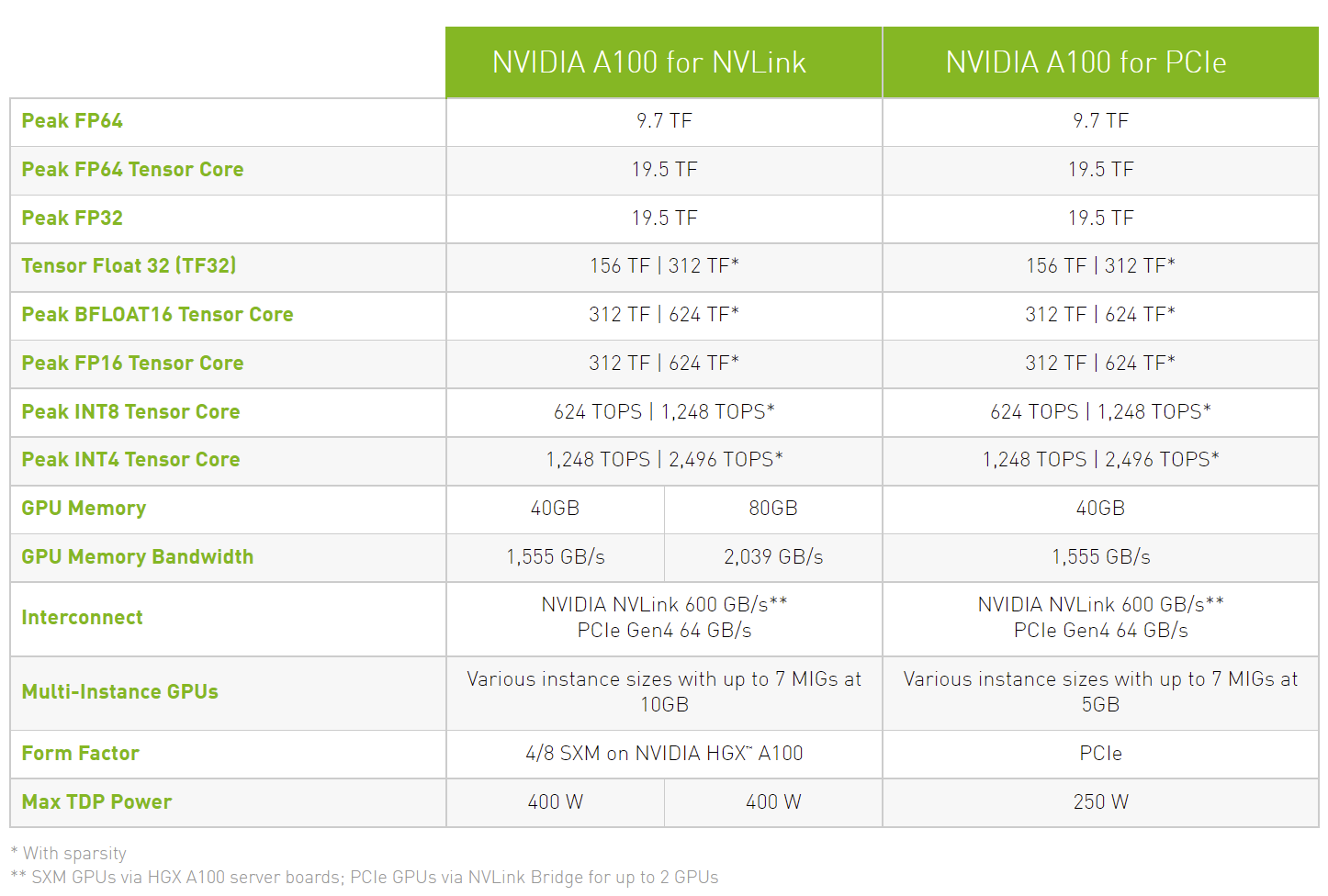
Spezifikationen der A100 PCIe 80-GB-Grafikkarte wie auf der NVIDIA-Webseite aufgeführt. (Bildnachweis: Videocardz)
Die FP64-Leistung wird weiterhin mit 9,7/19,5 TFLOPs bewertet, die FP32-Leistung wird mit 19,5/156/312 TFLOPs (Sparsity) bewertet, die FP16-Leistung wird mit 312/624 TFLOPs (Sparsity) bewertet und die INT8 wird mit 624/bewertet. 1248 TOPs (Sparsity). NVIDIA plant die Veröffentlichung seines neuesten HPC-Beschleunigers nächste Woche und wir können auch mit Preisen von über 20.000 US-Dollar rechnen, wenn man bedenkt, dass die 40-GB-A100-Variante für rund 15.000 US-Dollar verkauft wird.
NVIDIA Ampere GA100 GPU-basierte Tesla A100 Spezifikationen:
| NVIDIA Tesla Grafikkarte | Tesla K40 (PCI-Express) |
Tesla M40 (PCI-Express) |
Tesla P100 (PCI-Express) |
Tesla P100 (SXM2) | Tesla V100 (SXM2) | Tesla V100S (PCIe) | NVIDIA A100 (SXM4) | NVIDIA A100 (PCIe4) |
|---|---|---|---|---|---|---|---|---|
| GPU | GK110 (Kepler) | GM200 (Maxwell) | GP100 (Pascal) | GP100 (Pascal) | GV100 (Volta) | GV100 (Volta) | GA100 (Ampere) | GA100 (Ampere) |
| Prozessknoten | 28nm | 28nm | 16nm | 16nm | 12nm | 12nm | 7nm | 7nm |
| Transistoren | 7,1 Milliarden | 8 Milliarden | 15,3 Milliarden | 15,3 Milliarden | 21,1 Milliarden | 21,1 Milliarden | 54,2 Milliarden | 54,2 Milliarden |
| GPU-Matrizengröße | 551 mm2 | 601 mm2 | 610 mm2 | 610 mm2 | 815mm2 | 815mm2 | 826mm2 | 826mm2 |
| SMs | 15 | 24 | 56 | 56 | 80 | 80 | 108 | 108 |
| TPCs | 15 | 24 | 28 | 28 | 40 | 40 | 54 | 54 |
| FP32 CUDA-Kerne pro SM | 192 | 128 | 64 | 64 | 64 | 64 | 64 | 64 |
| FP64 CUDA Cores/SM | 64 | 4 | 32 | 32 | 32 | 32 | 32 | 32 |
| FP32 CUDA-Kerne | 2880 | 3072 | 3584 | 3584 | 5120 | 5120 | 6912 | 6912 |
| FP64 CUDA-Kerne | 960 | 96 | 1792 | 1792 | 2560 | 2560 | 3456 | 3456 |
| Tensorkerne | N/A | N/A | N/A | N/A | 640 | 640 | 432 | 432 |
| Textureinheiten | 240 | 192 | 224 | 224 | 320 | 320 | 432 | 432 |
| Boost Clock | 875 MHz | 1114 MHz | 1329 MHz | 1480 MHz | 1530 MHz | 1601 MHz | 1410 MHz | 1410 MHz |
| TOPs (DNN/AI) | N/A | N/A | N/A | N/A | 125 TOPs | 130 TOPs | 1248 TOPs 2496 TOPs mit Sparsity |
1248 TOPs 2496 TOPs mit Sparsity |
| FP16 Compute | N/A | N/A | 18,7 TFLOPs | 21,2 TFLOPs | 30.4 TFLOPs | 32.8 TFLOPs | 312 TFLOPs 624 TFLOPs mit Sparsity |
312 TFLOPs 624 TFLOPs mit Sparsity |
| FP32 Compute | 5.04 TFLOPs | 6.8 TFLOPs | 10.0 TFLOPs | 10.6 TFLOPs | 15,7 TFLOPs | 16,4 TFLOPs | 156 TFLOPs (19,5 TFLOPs Standard) |
156 TFLOPs (19,5 TFLOPs Standard) |
| FP64 Compute | 1.68 TFLOPs | 0,2 TFLOPs | 4,7 TFLOPs | 5,30 TFLOPs | 7,80 TFLOPs | 8,2 TFLOPs | 19,5 TFLOPs (9,7 TFLOPs Standard) |
19,5 TFLOPs (9,7 TFLOPs Standard) |
| Speicherschnittstelle | 384-Bit-GDDR5 | 384-Bit-GDDR5 | 4096-Bit-HBM2 | 4096-Bit-HBM2 | 4096-Bit-HBM2 | 4096-Bit-HBM2 | 6144-bit HBM2e | 6144-bit HBM2e |
| Speichergröße | 12 GB GDDR5 @ 288 GB/s | 24 GB GDDR5 bei 288 GB/s | 16 GB HBM2 bei 732 GB/s 12 GB HBM2 @ 549 GB/s |
16 GB HBM2 @ 732 GB/s | 16 GB HBM2 @ 900 GB/s | 16 GB HBM2 @ 1134 GB/s | 40 GB HBM2 @ 1,6 TB/s | Bis zu 80 GB HBM2 @ 1,6 TB/s |
| L2-Cache-Größe | 1536 KB | 3072 KB | 4096 KB | 4096 KB | 6144 KB | 6144 KB | 40960 KB | 40960 KB |
| TDP | 235W | 250W | 250W | 300W | 300W | 250W | 400W | 250W |
