.fb-comments,.fb-comments span,.fb-comments span iframe[style]{min-width:100%!important;width:100%!important} 
Nina Strehl dengan menggunakan Unsplash
K-closest neighbor (KNN) adalah semacam algoritme penguasaan perangkat penemuan yang diawasi dan dapat diterapkan untuk kedua tanggung jawab regresi dan klasifikasi tersebut.
Algoritme pemahaman mesin yang diawasi bergantung pada detail input berlabel yang dipelajari oleh algoritme dan memanfaatkan keahlian yang dipelajarinya untuk menghasilkan output yang tepat saat data tidak berlabel dimasukkan.
Penggunaan KNN adalah membuat prediksi pada fakta pemeriksaan yang ditetapkan sebagian besar berdasarkan sifat (informasi berlabel) dari informasi pelatihan. Sistem yang digunakan untuk membuat prediksi ini adalah dengan menghitung jarak antara informasi cek dan informasi instruksi, dengan asumsi bahwa sifat atau karakteristik yang sangat mirip dari detail fakta ada dalam jarak yang dekat.
Ini memungkinkan kita untuk mengenali dan menetapkan kelompok informasi baru sambil memikirkan fitur-fiturnya tergantung pada faktor fakta yang terungkap dari pengetahuan pembinaan. Karakteristik tempat informasi baru ini akan dipelajari oleh algoritma KNN dan terutama berdasarkan kedekatannya dengan titik data lain, akan dikategorikan.
KNN adalah algoritma yang baik untuk digunakan, terutama untuk pekerjaan klasifikasi. Klasifikasi adalah aktivitas umum yang ditemukan oleh banyak Pakar Pengetahuan dan insinyur Penemuan Perangkat. Ini memecahkan sejumlah besar tantangan lingkungan yang serius.
Oleh karena itu, algoritma seperti KNN adalah pilihan algoritma yang bagus dan akurat untuk digunakan untuk klasifikasi pola dan versi regresi. KNN telah diakui untuk tidak membuat asumsi tentang fakta, utama untuk akurasi yang lebih besar daripada algoritma klasifikasi lainnya. Algoritme ini juga mudah dipraktikkan dan dapat diinterpretasikan.
‘K’dalam KNN adalah parameter yang mengacu pada variasi tetangga terdekat, tepatnya di mana nilai-K terutama menghasilkan lingkungan alami untuk detail detail untuk memahami kesamaannya tergantung pada kedekatan. Memanfaatkan K-manfaat, kami menghitung jarak antara melihat faktor pengetahuan dan faktor berlabel berpendidikan untuk mengkategorikan poin informasi baru.
Nilai-K adalah bilangan bulat konstruktif yang umumnya lebih kecil nilainya dengan saran bahwa itu menjadi jumlah yang ganjil. Ketika K-worth kompak, biaya kesalahan berkurang, dengan bias rendah tetapi varians unggul yang pelanggan potensial untuk overfitting desain.
KNN adalah sebagian besar algoritma berbasis panjang, dengan yang paling umum solusi yang diterapkan tersisa:
Euclidean dan Manhattan untuk data kontinu Panjang Hamming untuk detail kategoris
Panjang Euclidean adalah jarak matematis di antara dua titik dalam tempat Euclidean saja dengan memanfaatkan durasi garis antara dua faktor. Ini adalah metrik panjang yang paling dikenal dan banyak orang akan mengingatnya dari fakultas dari Teorema Pythagoras.
Jarak Manhattan adalah panjang matematis dari dua detail, yang merupakan jumlah dari selisih mutlak koordinat Cartesiannya. Dalam istilah yang sangat sederhana, gerakan jalan yang berkaitan dengan jarak hanya dapat dinilai dari atas, bawah, dan samping.
Jarak hamming membandingkan dua string data biner dan kemudian membandingkan dua input string ini untuk menemukan variasi angka unik di setiap tempat individu dari string.
Ini adalah ukuran standar yang perlu Anda pilih untuk algoritme KNN
Muat di dataset Anda Pilih k-price. Anda harus memutuskan nomor ganjil untuk menghindari seri. Temukan panjang yang melibatkan titik informasi baru dan faktor fakta terdidik yang ada di sekitarnya. Menetapkan tahap fakta baru ke K tetangga terdekat
neighbours adalah kesepakatan dari modul sklearn yang Anda gunakan untuk tanggung jawab klasifikasi tetangga terdekat. Ini dapat digunakan untuk dua pemahaman yang tidak diawasi dan yang diawasi.
Awalnya, Anda perlu mengimpor perpustakaan ini:
import numpy as np
 import matplotlib.pyplot as plt
 import pandas as pd
Ini adalah kesepakatan sklearn neighbor:
sklearn.neighbors.KNeighborsClassifier
Ini adalah parameter yang dapat digunakan:
course sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, *, weights=”uniform”, algorithm=’auto’, leaf_sizing=30, p=2, metric=”minkowski”, metric_params=None, n_employment=None)
Metrik jarak yang digunakan di sini dalam kasus yang dimaksud adalah minkowski, namun seperti yang disebutkan di atas, ada banyak metrik jarak yang dapat Anda gunakan.
Jika Anda ingin mengetahui lebih banyak tentang parameter ini, klik link.
Muat di Iris Dataset
Impor perpustakaan ini:
import numpy as np
 import matplotlib.pyplot as plt
 import pandas as pd
Import Iris dataset:
# url for Iris dataset
 url=”https://archive.ics.uci.edu/ml/equipment-mastering-databases/iris/iris.knowledge”
 
 # Tetapkan nama kolom ke kumpulan data
 names=[‘sepal-length’,’sepal-width’,’petal-length’,’petal-width’,’Class’]
 
 # Belajar di kumpulan data
 df=pd.study_csv(url, nama=nama)
Seperti inilah pencarian kumpulan data dengan menjalankan df.head():
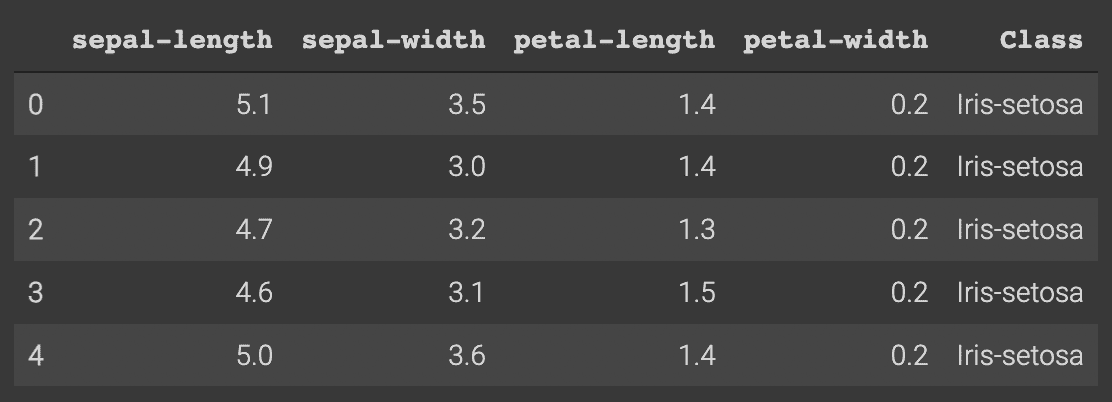
Praproses Dataset
Tahap selanjutnya adalah membagi dataset berdasarkan karakteristik dan labelnya. Kolom kursus dianggap keluar label dan disebut sebagai y, di mana 4 kolom pertama adalah karakteristik dan akan disebut sebagai X
X=dataset.iloc[:,:-1].values
 y=dataset.iloc[:, 4].values
Persiapan/Pemecahan ujian
Memanfaatkan pemisahan kereta/ujian pada kumpulan data kami akan membantu kami untuk lebih memahami seberapa efektif kinerja algoritme kami pada yang tidak terlihat informasi/periode pengujian. Ini juga dapat membantu meminimalkan overfitting dari transpiring.
dari sklearn.product_variety import coach_examination_break up
 X_educate, X_exam, y_educate, y_exam=teaching_examination_break up(X, y, exam_measurement=.20)
Penskalaan Aspek
Penskalaan elemen adalah penskalaan yang signifikan langkah sebelum mengeksekusi produk Anda untuk mulai mendapatkan prediksi. Ini akan melibatkan penskalaan kembali kemampuan dalam batas tipikal sehingga tidak ada informasi tentang setiap titik info yang hilang. Tanpa ini, desain Anda mungkin bisa membuat prediksi yang tidak tepat.
dari sklearn.preprocessing import StandardScaler
 scaler=StandardScaler()
 scaler.in shape(X_prepare)
 
 X_prepare=scaler.change(X_prepare)
 X_exam=scaler.remodel( X_examination)
Buat Prediksi Anda
Di sinilah kita akan menggunakan kesepakatan tetangga dari modul sklearn. Seperti yang Anda lihat, kami telah memilih jumlah tetangga (nilai K) sebagai 5.
dari sklearn.neighbors import KNeighborsClassifier
 classifier=KNeighborsClassifier(n_neighbors=5)
 classifier.fit(X_train, y_train )
Sekarang kami ingin membuat prediksi pada kumpulan data ujian:
y_pred=classifier.predict(X_exam)
Mengevaluasi Algoritme Anda
Metrik paling normal yang digunakan untuk menganalisis algoritme Anda adalah matriks kebingungan, presisi, ingat dan peringkat f1.
dari sklearn.metrics mengimpor laporan_klasifikasi, confusion_matrix
 print(confusion_matrix(y_examination, y_pred))
 print(classification_report(y_exam, y_pred))
Ini adalah outputnya:
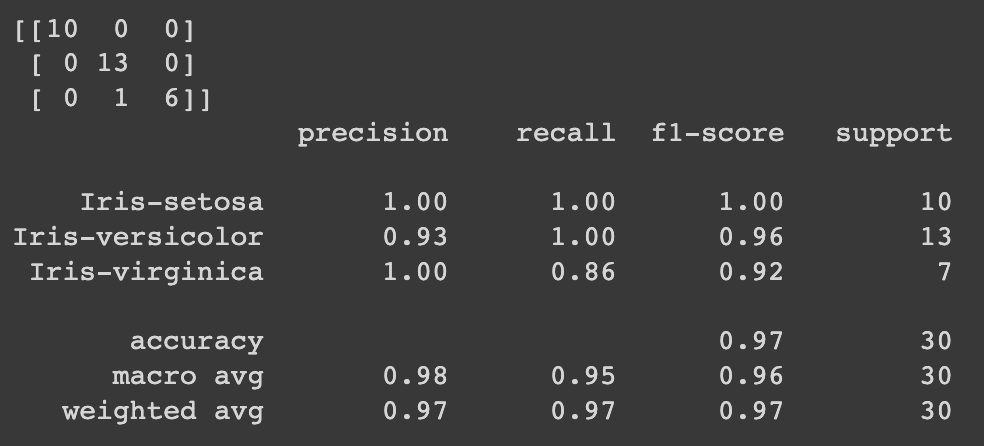
Jadi, tampaknya kami menyadari bahwa KNN adalah algoritme unggul yang digunakan untuk tugas klasifikasi dan bahwa bundel tetangga di Scikit-mengerti dapat membuat semuanya jauh lebih mudah. Ini cukup mudah dan cepat untuk diterapkan dengan keserbagunaan untuk pilihan atribut/jarak. Ini memiliki kemampuan untuk menangani skenario multi-kursus dan dapat dengan mahir menghasilkan output yang tepat.
Tetapi ada beberapa poin yang perlu Anda pertimbangkan ketika akan datang ke KNN. Mencari tahu k-worth bisa jadi rumit, karena itu bisa menjadi perubahan antara membuat overfitting atau tidak. Ini juga bisa menjadi masalah coba-coba saat menentukan metrik jarak mana yang harus Anda gunakan. KNN juga memiliki nilai komputasi yang signifikan saat kami menghitung jarak di antara tempat informasi baru dan faktor data instruksi. Saat ini dijelaskan, algoritma KNN melambat karena variasi contoh dan variabel akan meningkat
Meskipun ini adalah salah satu algoritma klasifikasi tertua dan digunakan dengan baik di luar sana, Anda harus mempertimbangkan penipu dengan sempurna.
Nisha Arya adalah seorang Ilmuwan Data dan Penulis Teknologi Lepas. Dia sangat tertarik dalam memberikan informasi atau tutorial panggilan Ilmu Informasi dan informasi yang berpusat pada ide di sekitar Ilmu Detail. Dia juga perlu melihat strategi khas Kecerdasan Buatan yang dapat menguntungkan umur panjang kehidupan manusia sehari-hari. Seorang pelajar yang bersemangat, berusaha untuk memperluas kesadaran teknologi dan kemampuan menulisnya, sambil melayani untuk membimbing orang lain.
Beri nilai postingan ini
Berbagi itu peduli!

