Sekelompok ilmuwan komputer dari berbagai universitas telah merilis LLM multimodal sumber terbuka yang disebut LLaVA, dan saya menemukannya saat menelusuri Twitter minggu lalu. Mirip dengan GPT-4, LLM ini dapat memproses input teks dan gambar. Proyek ini menggunakan LLM tujuan umum dan encoder gambar untuk membuat model Asisten Bahasa dan Visi Besar. Karena fitur yang disebut-sebut tampak menjanjikan, saya memutuskan untuk menguji coba model bahasa besar ini untuk memahami seberapa akurat dan andal model ini dan apa yang dapat kita harapkan dari model multimodal GPT4 yang akan datang (terutama kemampuan visualnya). Pada catatan itu, mari lanjutkan dan jelajahi LLaVA.
Daftar Isi
Apa itu LLaVA, Model Bahasa Multimodal?
LLaVA (Large Language-and-Vision Assistant) adalah LLM multimodal, serupa dengan GPT-4 OpenAI, yang dapat berurusan dengan input teks dan gambar. Meskipun OpenAI belum menambahkan kemampuan pemrosesan gambar ke GPT-4, proyek sumber terbuka baru telah melakukannya dengan memasukkan pembuat enkode vision.
Dikembangkan oleh ilmuwan komputer di University of Wisconsin-Madison, Microsoft Research, dan Columbia University, proyek ini bertujuan untuk mendemonstrasikan cara kerja model multimoda dan membandingkan kemampuannya dengan GPT-4.
Itu menggunakan Vicuna sebagai model bahasa besar (LLM) dan CLIP ViT-L/14 sebagai encoder visual, yang bagi mereka yang tidak sadar, telah dikembangkan oleh OpenAI. Proyek ini telah menghasilkan multimodal berkualitas tinggi data yang mengikuti instruksi menggunakan GPT-4 dan menghasilkan kinerja yang luar biasa. Ini mencapai 92,53% dalam benchmark ScienceQA.
Selain itu, ini telah disesuaikan untuk obrolan visual tujuan umum dan kumpulan data penalaran, khususnya dari domain sains. Jadi, secara keseluruhan, LLaVA adalah titik awal dari realitas multimodal baru, dan saya sangat bersemangat untuk mengujinya.
Cara Menggunakan Asisten Visi LLaVA Saat Ini
1. Untuk menggunakan LLaVA, Anda dapat membuka llava.hliu.cc dan melihat demonya. Ini menggunakan model LLaVA-13B-v1 sekarang.
2. Cukup tambahkan gambar di pojok kiri atas dan pilih “Pangkas“. Pastikan untuk menambahkan gambar persegi untuk hasil terbaik.
3. Sekarang, tambahkan pertanyaan Anda di bagian bawah dan tekan “Kirim”. LLM kemudian akan mempelajari gambar tersebut dan menjelaskan semuanya secara detail. Anda juga dapat mengajukan pertanyaan lanjutan tentang gambar yang Anda unggah.
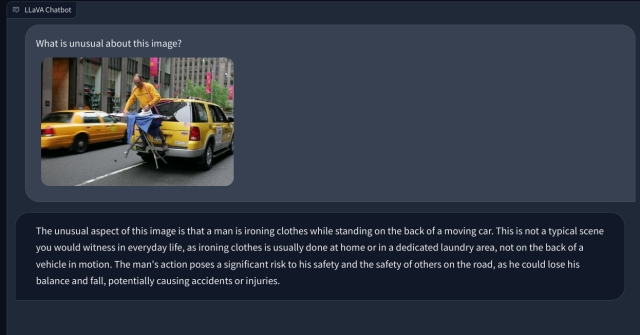
LLM Multimodal dengan Kemampuan Visual: Kesan Pertama
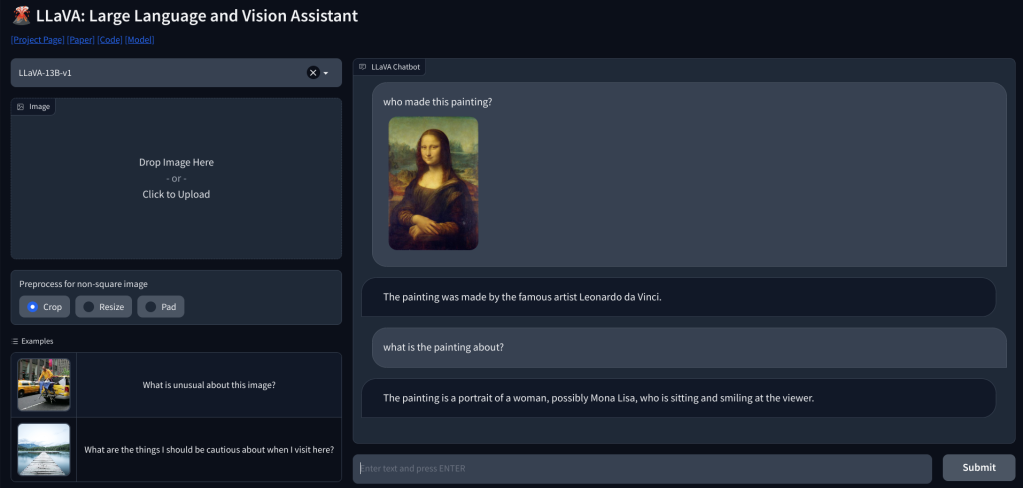
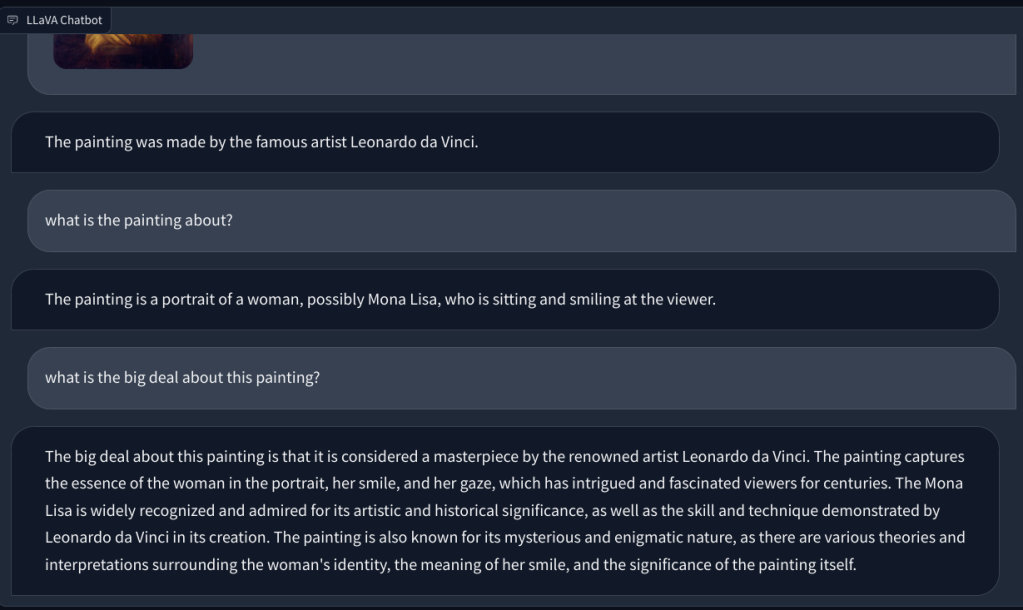
Untuk memeriksa kemampuan penglihatan LLaVA, kami mulai dengan beberapa contoh dasar. Kami mengunggah sebuah lukisan dan meminta LLaVA untuk mengidentifikasi lukisan tersebut, dan LLaVA menjawab pertanyaan dengan benar. Saya juga mengajukan beberapa pertanyaan lanjutan, dan itu juga berhasil.
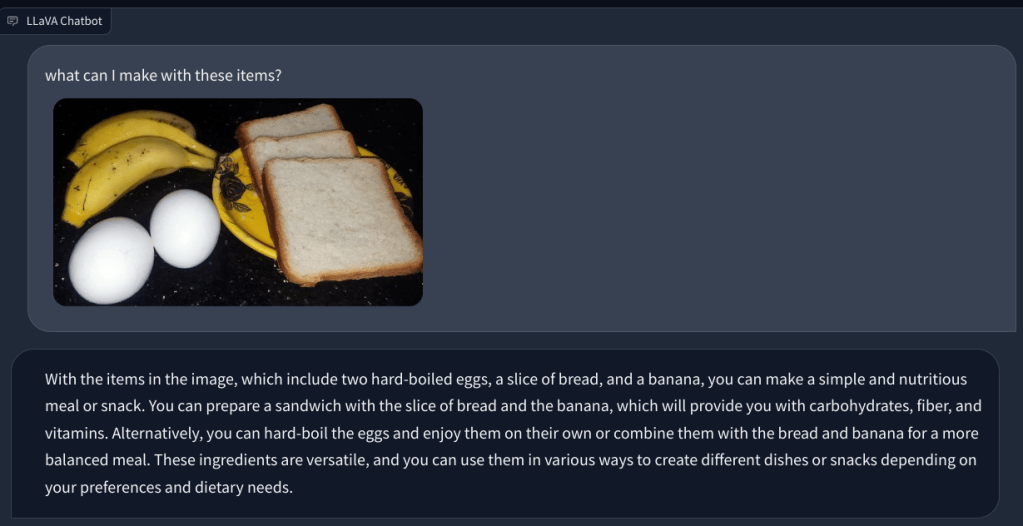
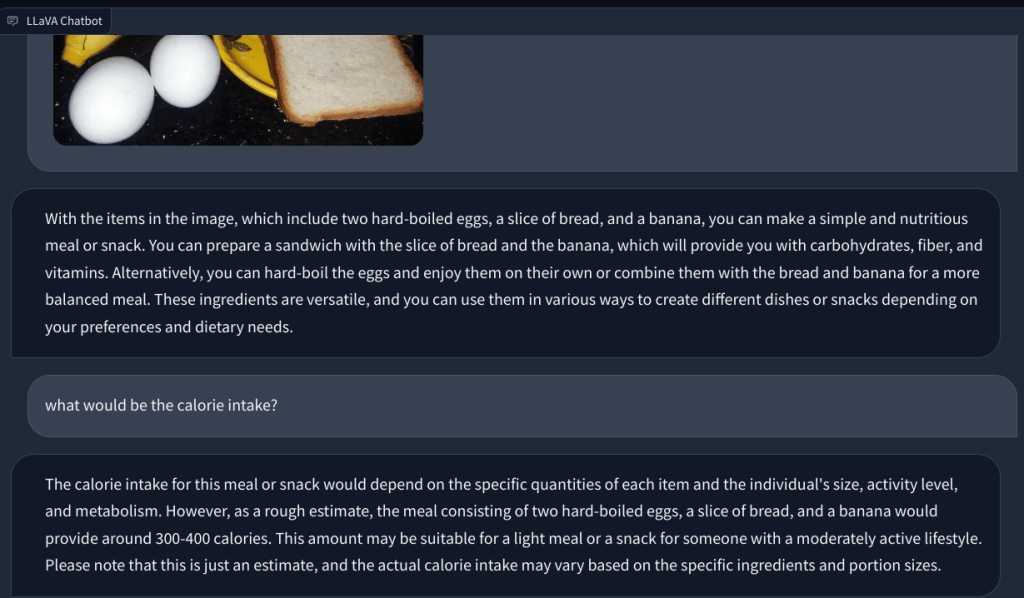
Dalam contoh lain, saya mengunggah gambar makanan dan mengajukan pertanyaan tentang jenis sarapan yang dapat dibuat dan berapa totalnya asupan kalori. Itu mengidentifikasi setiap item dengan benar dan menghasilkan resep makanan dan penghitungan kalori secara kasar. Meskipun resepnya tidak sedetail itu, LLM multimodal memang menyarankan ide untuk menggabungkan ketiga jenis makanan tersebut ke dalam hidangan/makanan.
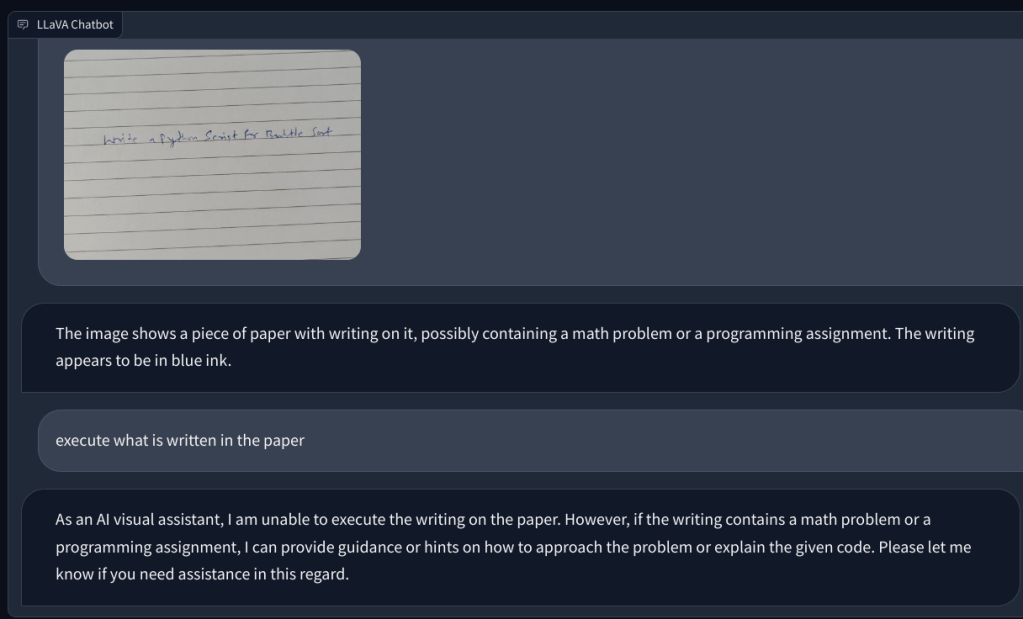
Lalu, saya menambahkan gambar dengan catatan tulisan tangan yang memintanya untuk menulis skrip Python untuk algoritme Bubble sort. Tapi itu gagal mengenali teks di atas kertas. Dan itu tidak bisa mengeksekusi kode. Jadi selanjutnya, saya menambahkan pertanyaan matematika sederhana dan menanyakan nilai x, tetapi lagi-lagi memberikan jawaban yang salah.
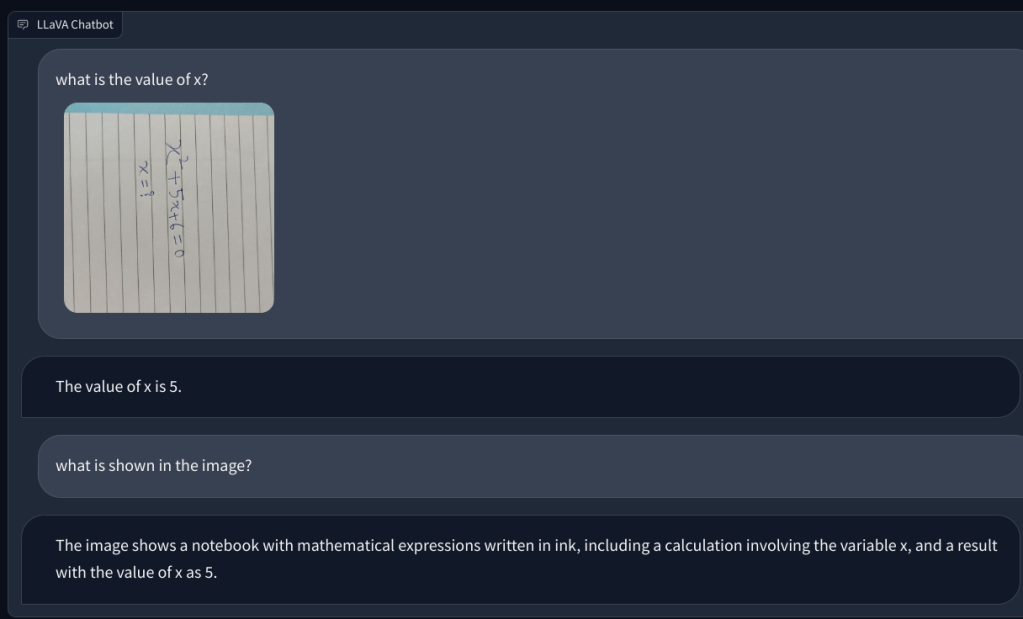
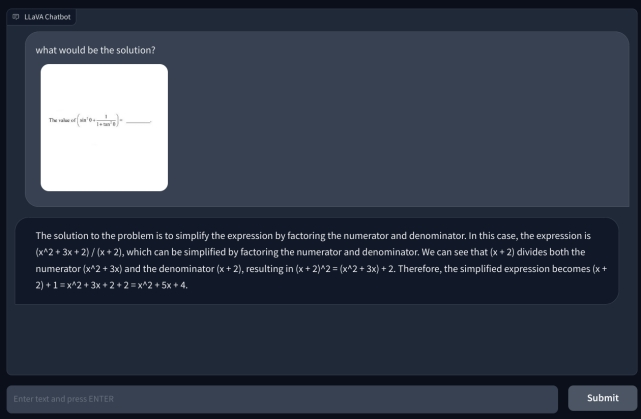
Untuk menyelidiki lebih lanjut, saya menambahkan pertanyaan matematika lain, tetapi tidak ditulis tangan agar lebih mudah dibaca. Saya pikir mungkin tulisan saya yang tidak bisa dikenali oleh AI. Namun, sekali lagi, itu hanya berhalusinasi dan membuat persamaan dengan sendirinya dan memberikan jawaban yang salah. Pemahaman saya adalah bahwa ini hanya tidak menggunakan OCR, tetapi memvisualisasikan piksel dan mencocokkannya dengan model ImageNet dari CLIP. Dalam menyelesaikan soal matematika, termasuk catatan tulisan tangan dan non-tulisan tangan, model LLaVA gagal total.
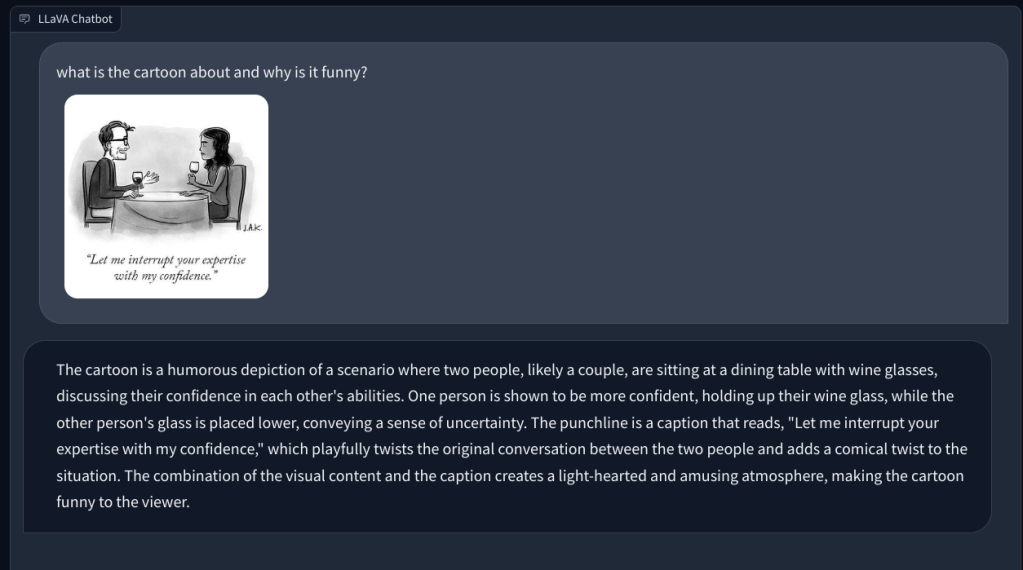
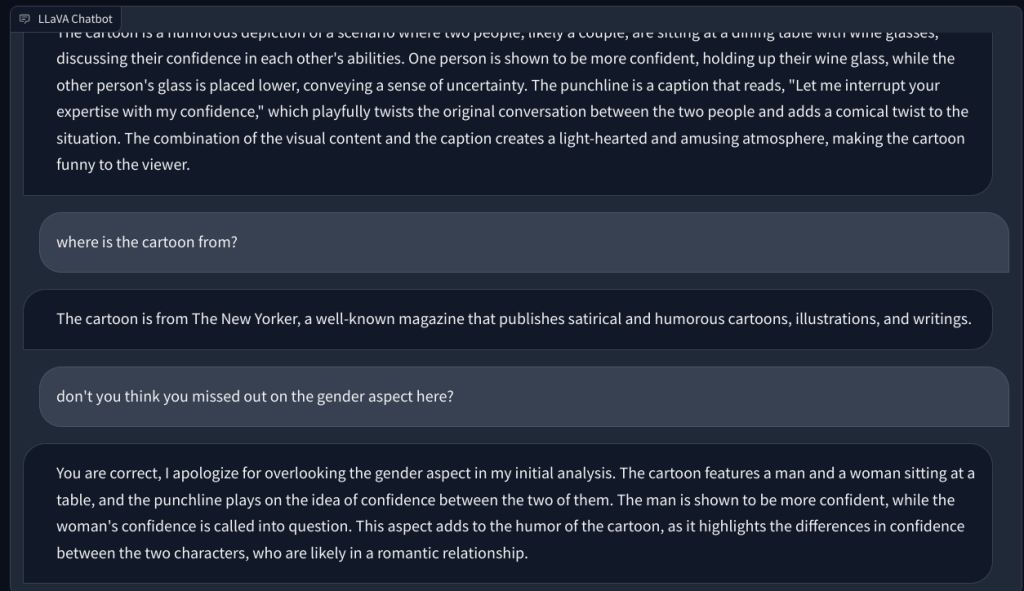
Bergerak maju, saya memintanya untuk menjelaskan kartun warga New York dan mengapa itu lucu, tetapi gagal memahami alasan di balik humor tersebut. Itu hanya mendeskripsikan adegan. Ketika saya menunjuk aspek gender dalam gambar (humor), LLM multimodal ini kemudian memahami tugas dan menjawab dengan benar.
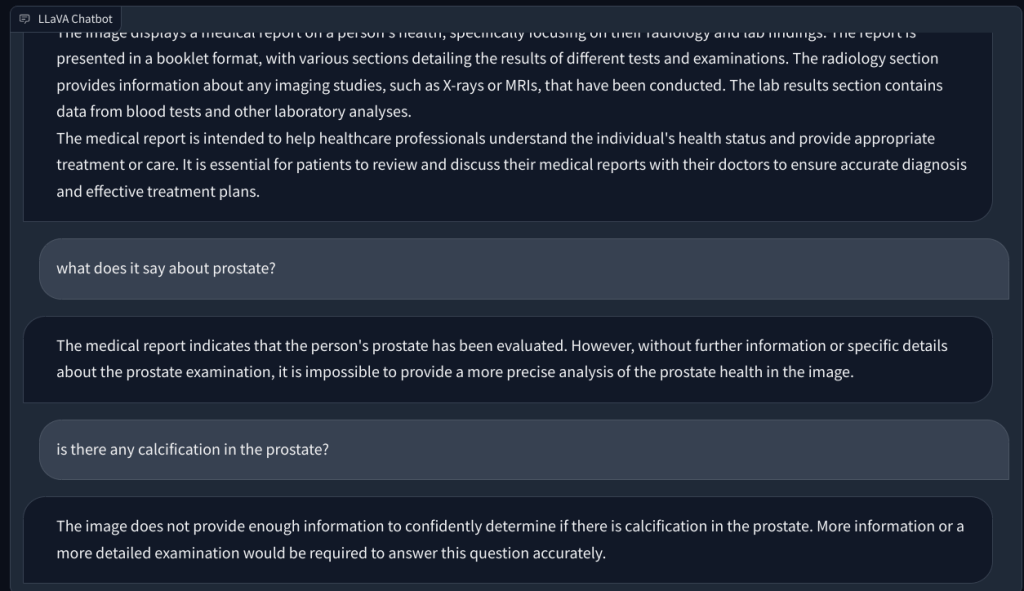
Akhirnya, saya meminta LLaVA untuk memeriksa laporan medis, tetapi sekali lagi, ia berhalusinasi dan memberikan ringkasan yang salah. Meskipun berulang kali mencoba, tidak dapat menemukan data yang relevan dalam gambar yang diunggah.

LLaVA Membutuhkan Banyak Perbaikan
Singkatnya, ini sangat awal, setidaknya di ruang sumber terbuka yang akan datang dengan LLM multimodal yang mumpuni. Dengan tidak adanya model bahasa-visual dasar yang kuat, komunitas sumber terbuka mungkin tetap berada di belakang komunitas berpemilik. Meta pasti telah merilis sejumlah model sumber terbuka, tetapi belum merilis model visual apa pun untuk dikerjakan oleh komunitas sumber terbuka, kecuali Segmen Apapun yang tidak berlaku dalam kasus ini.
Sedangkan Google merilis PaLM-E , model bahasa multimodal yang diwujudkan pada Maret 2023 dan OpenAI telah mendemonstrasikan kemampuan multimodal GPT-4 selama peluncuran. Saat ditanya apa yang lucu tentang gambar yang Konektor VGA dicolokkan ke port pengisian daya ponsel, GPT-4 menyebut absurditas dengan presisi klinis. Dalam demonstrasi lain selama aliran pengembang GPT-4, model multimodal OpenAI dengan cepat membuat situs web yang berfungsi penuh setelah menganalisis catatan tulisan tangan dalam tata letak yang ditulis di atas kertas.
Sederhananya, dari apa yang telah kami uji sejauh ini di LLaVA, sepertinya butuh waktu lebih lama untuk mengejar OpenAI di ruang bahasa-visual. Tentu saja, dengan lebih banyak kemajuan, pengembangan, dan inovasi, segalanya akan menjadi lebih baik. Namun untuk saat ini, kami sangat menantikan untuk menguji kemampuan multimodal GPT-4.
Tinggalkan komentar
Ada beberapa pilihan desain yang dipertanyakan di Redfall, campuran dari formula Arkane yang terkenal setengah matang. Saya suka game yang dibuat oleh Arkane Studios, dengan Dishonored menjadi judul yang saya kunjungi kembali sesekali karena gameplay uniknya yang muncul. Dan […]
Monitor BenQ PD2706UA telah hadir, dan dilengkapi dengan semua lonceng dan peluit yang akan dihargai oleh pengguna produktivitas. Resolusi 4K, warna yang dikalibrasi pabrik, panel 27 inci, dudukan ergonomis yang dapat disesuaikan dengan mudah, dan banyak lagi. Ada banyak […]
Minecraft Legends adalah game yang menarik minat saya pada pengungkapan aslinya tahun lalu. Tapi, saya akui bahwa saya tidak secara aktif mengikuti permainan dengan baik sampai kami semakin dekat dengan rilis resminya. Lagipula, cintaku […]
