Valutazioni dell’editor: Valutazioni degli utenti:[Totale: 0 Media: 0].ilfs_responsive_below_title_1 { width: 300px; } @media(larghezza minima: 500px) {.ilfs_responsive_below_title_1 { larghezza: 300px; } } @media(larghezza minima: 800px) {.ilfs_responsive_below_title_1 { larghezza: 336px; } }
OCRmyPDF è uno strumento open source gratuito per aggiungere un livello di testo OCR ai file PDF scansionati per crearli ricercabile. Prende semplicemente un file PDF scansionato da te e quindi esegue l’OCR su tutte le pagine per identificare il testo e aggiungervi un livello. Inoltre, identificando il testo, può correggere i file PDF. Se alcuni PDF sono inclinati e ruotano in modo errato, puoi scegliere di correggere automaticamente anche quello.
Questo strumento viene eseguito in modalità riga di comando e dipende dal motore OCR Ghostscript e Tesseract. È in grado di identificare il testo utilizzando l’OCR in qualsiasi lingua e genera file PDF ricercabili. Puoi eseguire questo strumento sui compiti scansionati degli studenti o sui moduli PDF per rendere i dati estraibili. Poiché utilizza Tesseract, che è un potente motore OCR, la precisione del testo è quasi fino al 97%.
Abbiamo utilizzato uno strumento da riga di comando prima per estrarre il testo dai PDF scansionati, ma OCRmyPDF qui è più avanzato. Se sei un programmatore, puoi creare un’interfaccia utente Web o desktop attorno ad esso. Oppure puoi anche sfruttare la sua funzionalità CLI per consentirgli di elaborare più file PDF in blocco in modo da renderli ricercabili.
Software gratuito per aggiungere un livello di testo OCR al file PDF scansionato: OCRmyPDF
OCRmyPDF può essere eseguito facilmente su Mac, Windows e Linux. Oltre a Ghostscript e Tesseract, dipende anche da Python. Quindi, dovrai assicurarti di avere Python. E se non hai Python, puoi semplicemente installarlo da qui. In questo post utilizzerò Windows ma i passaggi sono praticamente gli stessi per altre piattaforme.
Scarica Ghostscript e ottieni Tesseract per Windows. Installa entrambi e verifica se i comandi”tesseract.exe”e”gswin64c.exe”funzionano. In caso contrario, dovrai aggiungere la posizione a questi file nella variabile di ambiente PATH. Aprire il prompt dei comandi con diritti di amministratore e quindi digitare il comando seguente per installare OCRmyPDF.
pip install ocrmypdf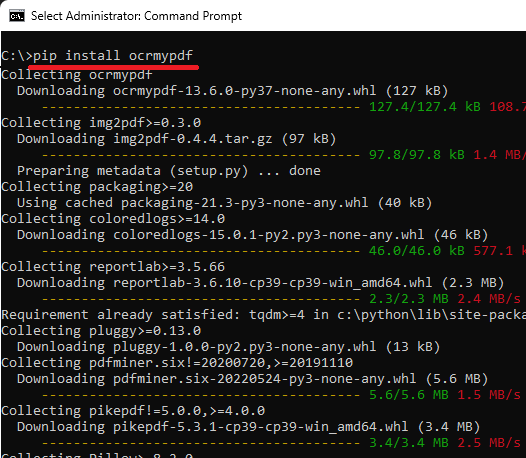 Passare dal prompt di CMD alla cartella in cui il file di input sta usando il comando cd.
Passare dal prompt di CMD alla cartella in cui il file di input sta usando il comando cd.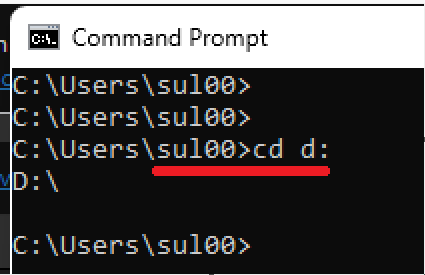 Esegui il comando principale OCRmyPDF in questo modo e attendi qualche secondo. Salverà il file PDF finale nella stessa directory con il nome”output_searchable.pdf”.
Esegui il comando principale OCRmyPDF in questo modo e attendi qualche secondo. Salverà il file PDF finale nella stessa directory con il nome”output_searchable.pdf”.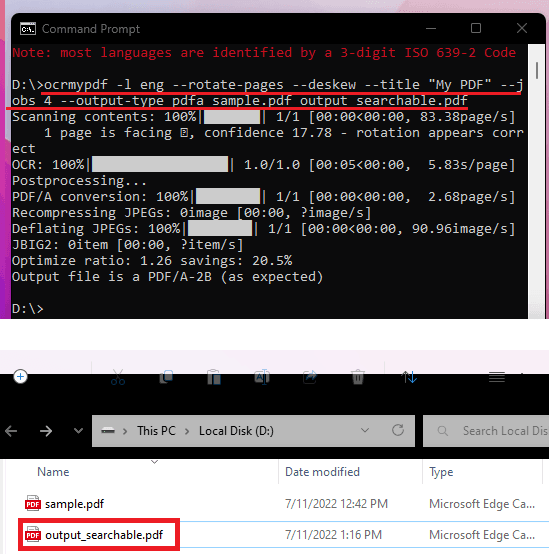 Fatto.
Fatto.
In questo modo, puoi utilizzare questo semplice strumento da riga di comando per installare e utilizzare OCRmyPDF. Il processo è semplice e abbastanza diretto. Devi solo eseguire un semplice comando e si occuperà del resto da solo.
Considerazioni finali:
OCRmyPDF è uno strumento molto utile per gli utenti che hanno molti documenti scansionati ed è difficile per loro estrarre il testo. Se sei una di quelle persone che usano questo strumento per rendere copiabile il testo su quei file PDF. Inoltre, poiché aggiunge un livello di testo, anche il file PDF verrà ricercato automaticamente.