NVIDIA ma ogłosił, że wprowadza dziś na rynek zupełnie nowe systemy HGX A100, które zawierają zaktualizowane akceleratory GPU A100 PCIe, oferujące dwukrotnie większą pamięć i szybszą przepustowość dla użytkowników HPC.
NVIDIA aktualizuje systemy HGX A100 o flagowe akceleratory GPU A100 HPC oparte na amperach — 80 GB pamięci HBM2e i przepustowość 2 TB/s
Istniejący akcelerator NVIDIA A100 HPC został wprowadzony w zeszłym roku w czerwcu i wygląda na to, że zielony zespół planuje wydać mu poważną aktualizację specyfikacji. Układ oparty jest na największym GPU Ampere firmy NVIDIA, A100, który mierzy 826 mm2 i zawiera obłędne 54 miliardy tranzystorów. NVIDIA zapewnia swoim akceleratorom HPC zwiększenie specyfikacji w połowie cyklu, co oznacza, że o akceleratorach nowej generacji usłyszymy podczas GTC 2022.

Procesory graficzne NVIDIA A100 Tensor Core zapewniają bezprecedensową akcelerację HPC, aby sprostać złożonym wyzwaniom związanym ze sztuczną inteligencją, analizą danych, szkoleniem modeli i symulacjami związanymi z przemysłowymi HPC. Procesory graficzne A100 80 GB PCIe zwiększają przepustowość pamięci GPU o 25 procent w porównaniu z A100 40 GB, do 2 TB/s i zapewniają 80 GB pamięci o wysokiej przepustowości HBM2e.
Ogromna pojemność pamięci i wysoka przepustowość karty A100 80 GB PCIe umożliwia przechowywanie większej ilości danych i większych sieci neuronowych w pamięci, minimalizując komunikację między węzłami i zużycie energii. W połączeniu z większą przepustowością pamięci umożliwia naukowcom osiągnięcie wyższej przepustowości i szybszych wyników, maksymalizując wartość ich inwestycji informatycznych.
A100 80 GB PCIe jest zasilany przez architekturę NVIDIA Ampere, która wykorzystuje technologię Multi-Instance GPU (MIG), aby zapewnić przyspieszenie dla mniejszych obciążeń, takich jak wnioskowanie AI. MIG umożliwia systemom HPC skalowanie mocy obliczeniowej i pamięci z gwarantowaną jakością usług. Oprócz PCIe istnieją cztero-i ośmiodrożne konfiguracje NVIDIA HGX A100.
Wsparcie partnerów NVIDIA dla karty A100 80 GB PCIe obejmuje Atos, Cisco, Dell Technologies, Fujitsu, H3C, HPE, Inspur, Lenovo, Pinguin Computing, QCT i Supermicro. Platforma HGX z procesorami graficznymi opartymi na A100 połączonymi przez NVLink jest również dostępna za pośrednictwem usług w chmurze Amazon Web Services, Microsoft Azure i Oracle Cloud Infrastructure.
Pod względem specyfikacji akcelerator GPU A100 PCIe nie zmienia się zbytnio pod względem podstawowej konfiguracji. GPU GA100 zachowuje specyfikacje, które widzieliśmy w wariancie 250 W z 6912 rdzeniami CUDA rozmieszczonymi w 108 jednostkach SM, 432 rdzeniami Tensor i 80 GB pamięci HBM2e, która zapewnia wyższą przepustowość 2,0 TB/s w porównaniu do 1,55 TB/s w wariant 40 GB.

Wyróżniony obraz kości NVIDIA GA100.
Wariant A100 SMX jest już wyposażony w pamięć 80 GB, ale nie zawiera szybszych matryc HBM2e, jak ten nadchodzący wariant A100 PCIe. Jest to również największa ilość pamięci, jaką kiedykolwiek zastosowano w karcie graficznej opartej na PCIe, ale nie należy oczekiwać, że konsumenckie karty graficzne będą w najbliższym czasie oferować tak wysokie pojemności. Interesujące jest to, że moc znamionowa pozostaje niezmieniona, co oznacza, że patrzymy na układy o większej gęstości przeznaczone do zastosowań o wysokiej wydajności.
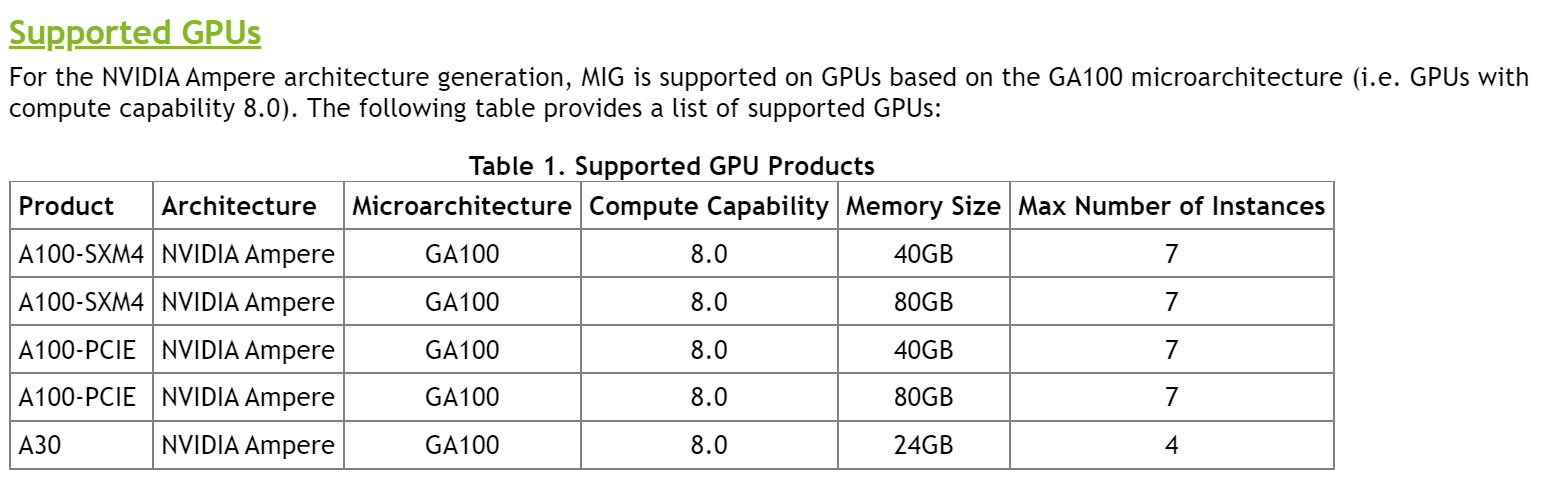
Dane techniczne karty graficznej A100 PCIe 80 GB wymienione na stronie internetowej NVIDIA. (Kredyty obrazkowe: Videocardz)
Wydajność FP64 jest nadal oceniana na 9,7/19,5 TFLOPs, wydajność FP32 jest oceniana na 19,5/156/312 TFLOPs (sparsity), wydajność FP16 jest oceniana na 312/624 TFLOPs (sparsity), a INT8 na 624/1248 szczytów (rzadkość). NVIDIA planuje wypuścić swój najnowszy akcelerator HPC w przyszłym tygodniu i możemy również spodziewać się ceny ponad 20 000 USD, biorąc pod uwagę, że wariant 40 GB A100 sprzedaje się za około 15 000 USD.
Oprócz tych zapowiedzi, NVIDIA ogłosiła również swoje nowe rozwiązanie InfiniBand, które zapewnia konfiguracje do 2048 punktów NDR 400 Gb/s (lub 4096 portów NDR 200) z całkowitą dwukierunkową przepustowością 1,64 Pb/s. Już samo to jest 5-krotnym wzrostem w porównaniu z poprzednią generacją i oferuje 32-krotnie wyższy akcelerator AI.
Specyfikacja Tesla A100 z procesorem graficznym NVIDIA Ampere GA100:
| Karta graficzna NVIDIA Tesla | Tesla K40 (PCI-Express) |
Tesla M40 (PCI-Express) |
Tesla P100 (PCI-Express) |
Tesla P100 (SXM2) | Tesla V100 (SXM2) | Tesla V100S (PCIe) | NVIDIA A100 (SXM4) | NVIDIA A100 (PCIe4) | |
|---|---|---|---|---|---|---|---|---|---|
| GPU | GK110 (Kepler) | GM200 (Maxwell) | GP100 (Pascal) | GP100 (Pascal) | GV100 (Volta) | GV100 (Wolta) | GA100 (A) | GA100 (A) | |
| Węzeł procesowy | 28 nm | 28nm | 16nm | 16nm | 12nm | 12nm | 7nm | 7nm | |
| Tranzystory | 7,1 miliarda | 8 miliardów | 15,3 miliardów | 15,3 miliardów | 21,1 miliarda | 21,1 miliarda | 54,2 miliarda | 54,2 miliarda | |
| Rozmiar matrycy GPU | 551 mm2 | 601 mm2 | 610 mm2 | 610 mm2 | 815mm2 | 815mm2 | 826mm2 | 826mm2 | |
| SM | 15 | 24 | 56 | 56 | 80 | 80 | 108 | 108 | |
| TPC | 15 | 24 | 28 | 28 | 40 | 40 | 54 | 54 | |
| Rdzenie CUDA FP32 na SM | 192 | 128 | 64 | 64 | 64 | 64 | 64 | 64 | |
| FP64 CUDA rdzenie/SM | 64 | 4 | 32 | 32 | 32 | 32 | 32 | 32 | |
| Rdzenie CUDA FP32 | 2880 | 3072 | 3584 | 3584 | 5120 | 5120 | 6912 | 6912 | |
| FP64 rdzenie CUDA | 960 | 96 | 1792 | 1792 | 2560 | 2560 | 3456 | 3456 | |
| Rdzenie napinające | Nie dotyczy | nie dotyczy | nie dotyczy | nie dotyczy | 640 | 640 | 432 | 432 | |
| Jednostki tekstury | 240 | 192 | 224 | 224 | 320 | 320 | 432 | 432 | |
| Zegar podwyższający | 875 MHz | 1114 MHz | 1329 MHz | 1480 MHz | 1530 MHz | 1601 MHz | 1410 MHz | 1410 MHz | |
| TOP (DNN/AI) | Nie dotyczy | Nie dotyczy | Nie dotyczy | Nie dotyczy | 125 szczytów | 130 szczytów | 1248 TOPs 2496 TOPs z rzadkością |
1248 TOPs 2496 TOPs z rzadkością |
|
| Obliczenia FP16 | Nie dotyczy | Nie dotyczy | 18,7 TFLOP | 21,2 TFLOP | 21,2 TFLOP td> | 30,4 TFLOP | 32,8 TFLOP | 312 TFLOP 624 TFLOPs ze sparsity |
312 TFLOPs 624 TFLOPs ze sparsity |
| Obliczenia FP32 | 5,04 TFLOP | 6,8 TFLOP | 10,0 TFLOP | 10,6 TFLOP | 15,7 TFLOP | 16,4 TFLOP | 156 TFLOP (19,5 TFLOP standardowe) |
156 TFLOP (standardowo 19,5 TFLOP) |
|
| Obliczenia FP64 | 1,68 TFLOP | 0,2 TFLOP | 4,7 TFLOP | 5,30 TFLOP | 7,80 TFLOP | 8,2 TFLOP | 19,5 TFLOP (9,7 TFLOP standardowe) |
19,5 TFLOP (9,7 TFLOP standardowe) |
|
| Interfejs pamięci | 384-bitowy GDDR5 | 384-bitowy GDDR5 | 4096-bitowy HBM2 | 4096-bitowy HBM2 | 4096-bitowy HBM2 | 4096-bitowy HBM2 | 6144-bit HBM2e | 6144-bit HBM2e | |
| Rozmiar pamięci | 12 GB GDDR5 @ 288 GB/s | 24 GB GDDR5 przy 288 GB/s | 16 GB HBM2 przy 732 GB/s 12 GB HBM2 przy 549 GB/s |
16 GB HBM2 przy 732 GB/s | 16 GB HBM2 przy 900 GB/s | 16 GB HBM2 przy 1134 GB/s | Do 40 GB HBM2 przy 1,6 TB/s Do 80 GB HBM2 przy 1,6 TB/s |
Do 40 GB HBM2 przy 1,6 TB/s Do 80 GB HBM2 przy 2,0 TB/s |
|
| Rozmiar pamięci podręcznej L2 | 1536 KB | 3072 KB | 4096 KB | 4096 KB | 6144 KB | 6144 KB | 40960 KB | 40960 KB | |
| TDP | 235W | 250 W | 250 W | 300 W | 300 W | 250 W | 400 W | 250 W |