
У NVIDIA есть объявила , что сегодня запускает новую систему HGX A100, включающую обновленные ускорители графического процессора A100 PCIe с удвоенным объемом памяти и более высокой пропускной способностью для пользователей HPC.
NVIDIA обновляет системы HGX A100 флагманскими графическими ускорителями A100 HPC на базе ампер-память HBM2e 80 ГБ и пропускная способность 2 ТБ/с
Существующий ускоритель NVIDIA A100 HPC был представлен в прошлом году в июне, и похоже, что зеленая команда планирует серьезно обновить его характеристики. Чип основан на самом большом графическом процессоре Ampere от NVIDIA, A100, который имеет площадь 826 мм2 и содержит 54 миллиарда транзисторов. NVIDIA увеличивает спецификации своих ускорителей HPC в середине цикла, а это значит, что мы услышим об ускорителях следующего поколения на GTC 2022.

Графические процессоры NVIDIA A100 с тензорным ядром обеспечивают беспрецедентное ускорение высокопроизводительных вычислений для решения сложных задач искусственного интеллекта, анализа данных, обучения моделей и моделирования, актуальных для промышленных высокопроизводительных вычислений. Графические процессоры A100 80 ГБ PCIe увеличивают пропускную способность памяти графического процессора на 25 процентов по сравнению с A100 40 ГБ до 2 ТБ/с и предоставляют 80 ГБ памяти HBM2e с высокой пропускной способностью.
Огромный объем памяти A100 80GB PCIe и высокая пропускная способность позволяют хранить в памяти больше данных и большие нейронные сети, сводя к минимуму межузловое взаимодействие и потребление энергии. В сочетании с более высокой пропускной способностью памяти это позволяет исследователям достичь более высокой пропускной способности и более быстрых результатов, максимизируя ценность своих инвестиций в ИТ.
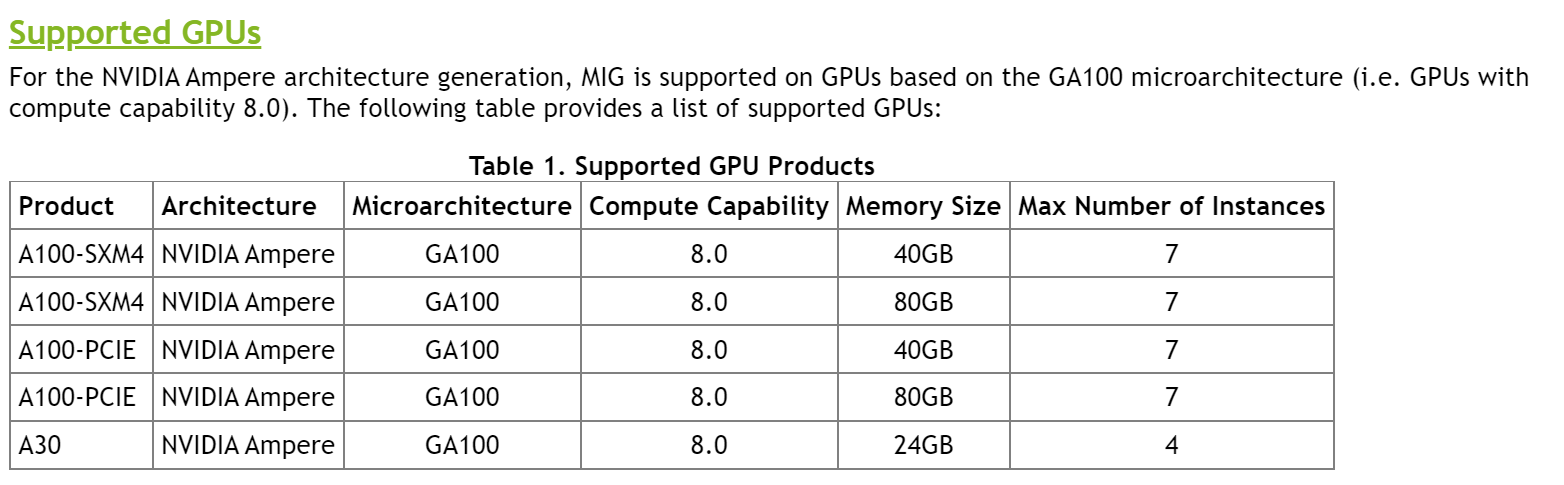
A100 80GB PCIe основан на архитектуре NVIDIA Ampere, в которой используется технология Multi-Instance GPU (MIG), обеспечивающая ускорение для небольших рабочих нагрузок, таких как логический вывод ИИ. MIG позволяет системам HPC масштабировать вычислительные ресурсы и память с гарантированным качеством обслуживания. Помимо PCIe, существуют четырех-и восьмипроцессорные конфигурации NVIDIA HGX A100.
Партнерская поддержка NVIDIA для A100 80GB PCIe включает Atos, Cisco, Dell Technologies, Fujitsu, H3C, HPE, Inspur, Lenovo, Penguin Computing , QCT и Supermicro . Платформа HGX с графическими процессорами на базе A100, соединенными через NVLink, также доступна через облачные сервисы от Amazon Web Services, Microsoft Azure и Oracle Cloud Infrastructure .
Что касается спецификаций, ускоритель A100 PCIe GPU не сильно меняет с точки зрения конфигурации ядра. Графический процессор GA100 сохраняет характеристики, которые мы видели в варианте мощностью 250 Вт с 6912 ядрами CUDA, размещенными в 108 SM-модулях, 432 тензорных ядрах и 80 ГБ памяти HBM2e, что обеспечивает более высокую пропускную способность 2,0 ТБ/с по сравнению с 1,55 ТБ/с на вариант на 40 ГБ.

Рекомендуемое изображение кристалла NVIDIA GA100.
Вариант A100 SMX уже поставляется с памятью 80 ГБ, но в нем нет более быстрых кристаллов HBM2e, как этот грядущий вариант A100 PCIe. Это также самый большой объем памяти, который когда-либо имелся на видеокарте на базе PCIe, но не ожидайте, что потребительские видеокарты будут иметь такую высокую емкость в ближайшее время. Интересно то, что номинальная мощность остается неизменной, а это означает, что мы рассматриваем чипы с более высокой плотностью размещения, предназначенные для высокопроизводительных вариантов использования.
Технические характеристики графической карты A100 PCIe 80 ГБ как указано на веб-странице NVIDIA. (Изображение предоставлено: Videocardz)
Производительность FP64 по-прежнему оценивается на уровне 9,7/19,5 терафлопс, производительность FP32-19,5/156/312 терафлопс (разреженность), производительность FP16-312/624 терафлопс (разреженность), а INT8-624 терафлопс. 1248 ТОПов (разреженность). NVIDIA планирует выпустить свой последний ускоритель HPC на следующей неделе, и мы также можем ожидать, что его цена составит более 20 000 долларов США, учитывая, что вариант A100 на 40 ГБ продается по цене около 15 000 долларов США.
В дополнение к этим объявлениям NVIDIA также анонсировала свое новое решение InfiniBand, которое обеспечивает конфигурации до 2048 точек NDR 400 Гбит/с (или 4096 портов NDR 200) с общей двунаправленной пропускной способностью 1,64 Пбит/с. с. Одно это в 5 раз больше, чем у предыдущего поколения, и предлагает в 32 раза более мощный ускоритель ИИ.
Технические характеристики Tesla A100 на базе графического процессора NVIDIA Ampere GA100:
| Графическая карта NVIDIA Tesla | Tesla K40 (PCI-Express) |
Tesla M40 (PCI-Express) |
Tesla P100 (PCI-Express) |
Tesla P100 (SXM2) | Tesla V100 (SXM2) | Tesla V100S (PCIe) | NVIDIA A100 (SXM4) | NVIDIA A100 (PCIe4) |
|---|---|---|---|---|---|---|---|---|
| GPU | GK110 (Kepler) | GM200 (Maxwell) | GP100 (Pascal) | GP100 (Паскаль) | GV100 (Volta) | GV100 (Вольта) | GA100 (Ампер) | GA100 (Ампер) |
| Узел процесса | 28 нм | 28 нм | 16 нм | 16 нм | 12 нм | 12 нм | 7 нм | 7 нм |
| Транзисторы | 7,1 миллиарда | 8 миллиардов | 15,3 миллиарда | 15,3 миллиарда | 21,1 миллиарда | 21,1 миллиарда | 54,2 миллиарда | 54,2 миллиарда |
| Размер кристалла GPU | 551 мм2 | 601 мм2 | 610 мм2 | 610 мм2 | 815 мм2 | 815 мм2 | 826 мм2 | 826 мм2 |
| SM | 15 | 24 | 56 | 56 | 80 | 80 | 108 | 108 |
| TPC | 15 | 24 | 28 | 28 | 40 | 40 | 54 | 54 |
| Количество ядер CUDA FP32 на SM | 192 | 128 | 64 | 64 | 64 | 64 | 64 | 64 |
| FP64 CUDA Cores/SM | 64 | 4 | 32 | 32 | 32 | 32 | 32 | 32 |
| Ядра CUDA FP32 | 2880 | 3072 | 3584 | 3584 | 5120 | 5120 | 6912 | 6912 |
| Ядра CUDA FP64 | 960 | 96 | 1792 | 1792 | 2560 | 2560 | 3456 | 3456 |
| Тензорные ядра | Н/Д | Неприменимо | Неприменимо | Неприменимо | 640 | 640 | 432 | 432 |
| Единицы текстуры | 240 | 192 | 224 | 224 | 320 | 320 | 432 | 432 |
| Частота разгона | 875 МГц | 1114 МГц | 1329 МГц | 1480 МГц | 1530 МГц | 1601 МГц | 1410 МГц | 1410 МГц |
| ТОПы (DNN/AI) | Неприменимо | Неприменимо | Неприменимо | Н/Д | 125 ТОПов | 130 ТОПов | 1248 ТОПов 2496 ТОПов с разреженностью |
1248 ТОПов 2496 ТОПов с разреженностью |
| FP16 Compute | Н/Д | Н/Д | 18,7 терафлопс | 21,2 терафлопс | 30,4 TFLOPs | 32,8 TFLOPs | 312 TFLOPs 624 ТФЛОП с разрежением |
312 терафлопов 624 терафлоп с разрежением |
| FP32 Compute | 5,04 TFLOPs | 6,8 терафлопс | 10,0 терафлопс | 10,6 терафлопс | 15,7 TFLOPs | 16,4 TFLOPs | 156 TFLOPs (19,5 TFLOPs стандарт) |
156 терафлопс (стандарт 19,5 терафлопс) |
| FP64 Compute | 1,68 TFLOPs | 0,2 терафлопс | 4,7 терафлопс | 5,30 терафлопс | 7,80 терафлопс | 8,2 терафлопс | 19,5 терафлопс (9,7 терафлопс стандарт) |
19,5 терафлопс (стандарт 9,7 терафлопс) |
| Интерфейс памяти | 384-битной GDDR5 | 384-битный GDDR5 | 4096-битный HBM2 | 4096-битный HBM2 | 4096-битный HBM2 | 4096-битный HBM2 | 6144-бит HBM2e | 6144-битный HBM2e |
| Размер памяти | 12 ГБ GDDR5 @ 288 ГБ/с | 24 ГБ GDDR5 @ 288 ГБ/с | 16 ГБ HBM2 @ 732 ГБ/с 12 ГБ HBM2 @ 549 ГБ/с |
16 ГБ HBM2 @ 732 ГБ/с | 16 ГБ HBM2 @ 900 ГБ/с | 16 ГБ HBM2 @ 1134 ГБ/с | До 40 ГБ HBM2 @ 1,6 ТБ/с До 80 ГБ HBM2 при 1,6 ТБ/с |
До 40 ГБ HBM2 при 1,6 ТБ/с До 80 ГБ HBM2 при 2,0 ТБ/с |
| Размер кэша L2 | 1536 КБ | 3072 КБ | 4096 КБ | 4096 КБ | 6144 КБ | 6144 КБ | 40960 КБ | 40960 КБ |
| TDP | 235 Вт | 250 Вт | 250 Вт | 300 Вт | 300 Вт | 250 Вт | 400 Вт | 250 Вт |