.fb-comments,.fb-comments span,.fb-comments span iframe[style]{min-width:100%!important;width:100% !important}
มีข้อมูลมาก ใช้เวลาน้อย ผู้เชี่ยวชาญด้านแมชชีนเลิร์นนิง (ML) นักวิทยาศาสตร์ข้อมูล วิศวกร และผู้ที่ชื่นชอบได้ประสบปัญหานี้ทั่วโลก ตั้งแต่การประมวลผลภาษาธรรมชาติไปจนถึงคอมพิวเตอร์วิทัศน์ ตารางไปจนถึงอนุกรมเวลา และทุกอย่างที่อยู่ระหว่างนั้น ปัญหาเก่าแก่ของการปรับความเร็วให้เหมาะสมเมื่อเรียกใช้ข้อมูลกับ GPU ให้มากที่สุดเท่าที่คุณจะทำได้ได้สร้างแรงบันดาลใจให้กับโซลูชันนับไม่ถ้วน วันนี้ เรายินดีที่จะประกาศคุณลักษณะสำหรับนักพัฒนาซอฟต์แวร์ PyTorch โดยใช้เฟรมเวิร์กโอเพนซอร์สแบบเนทีฟ เช่น PyTorch Lightning และ PyTorch DDP ที่จะปรับปรุงเส้นทางไปยังคลาวด์
Amazon SageMaker เป็นบริการที่มีการจัดการเต็มรูปแบบสำหรับ ML และการฝึกโมเดล SageMaker เป็นสภาพแวดล้อมการประมวลผลที่ปรับให้เหมาะสมที่สุดสำหรับการฝึกอบรมที่มีประสิทธิภาพสูงตามขนาด การฝึกโมเดล SageMaker มอบประสบการณ์การฝึกระยะไกลด้วยระนาบการควบคุมที่ไร้รอยต่อ เพื่อฝึกฝนและทำซ้ำโมเดล ML ได้อย่างง่ายดายด้วยประสิทธิภาพสูงและต้นทุนต่ำ เรารู้สึกตื่นเต้นที่จะประกาศคุณลักษณะใหม่ในพอร์ตการฝึกอบรม SageMaker ที่ทำให้ PyTorch ใช้งานในวงกว้างได้ง่ายขึ้นและเข้าถึงได้ง่ายขึ้น:
ขณะนี้ PyTorch Lightning สามารถรวมเข้ากับไลบรารีข้อมูลแบบคู่ขนานแบบกระจายของ SageMaker ด้วยการเปลี่ยนแปลงโค้ดเพียงบรรทัดเดียว การฝึกโมเดล SageMaker ตอนนี้รองรับ PyTorch Distributed Data Parallel แบบเนทีฟพร้อมแบ็กเอนด์ NCCL ทำให้นักพัฒนาสามารถโยกย้ายไปยัง SageMaker ได้ง่ายกว่าที่เคย
ในโพสต์นี้ เราพูดถึงคุณสมบัติใหม่เหล่านี้ และเรียนรู้วิธีที่ Amazon Search เรียกใช้ PyTorch Lightning ด้วยแบ็กเอนด์การฝึกอบรมแบบกระจายที่ปรับให้เหมาะสมใน SageMaker เพื่อเร่งเวลาการฝึกโมเดล
ก่อนดำดิ่งสู่ Amazon กรณีศึกษาการค้นหา สำหรับผู้ที่ไม่คุ้นเคย เราต้องการให้ข้อมูลพื้นฐานเกี่ยวกับไลบรารีข้อมูลแบบคู่ขนานแบบกระจายของ SageMaker ในปี 2020 เราได้พัฒนาและเปิดตัวการกำหนดค่าคลัสเตอร์แบบกำหนดเองสำหรับการไล่ระดับสีแบบกระจายตามขนาดที่เพิ่มประสิทธิภาพของคลัสเตอร์โดยรวม ซึ่งเปิดตัวใน Amazon Science ในชื่อ Herring การใช้เซิร์ฟเวอร์พารามิเตอร์ที่ดีที่สุดและโทโพโลยีแบบวงแหวนทำให้ SageMaker Distributed Data Parallel (SMDDP) ได้รับการปรับให้เหมาะสมสำหรับโทโพโลยีเครือข่าย Amazon Elastic Compute Cloud (Amazon EC2) รวมถึง EFA สำหรับขนาดคลัสเตอร์ที่ใหญ่ขึ้น SMDDP สามารถปรับปรุงปริมาณงานได้ 20-40% เมื่อเทียบกับ Horovod (TensorFlow) และ PyTorch Distributed Data Parallel สำหรับขนาดคลัสเตอร์ที่เล็กกว่าและรุ่นที่รองรับ เราขอแนะนำ SageMaker Training Compiler ซึ่งสามารถลดเวลางานโดยรวมได้มากถึง 50%
จุดเด่นของลูกค้า: PyTorch Lightning บนแบ็กเอนด์ที่เพิ่มประสิทธิภาพของ SageMaker ด้วย Amazon Search
Amazon Search รับผิดชอบ ประสบการณ์การค้นหาและค้นพบใน Amazon.com ช่วยเพิ่มประสบการณ์การค้นหาสำหรับลูกค้าที่กำลังมองหาผลิตภัณฑ์ที่จะซื้อใน Amazon ในระดับสูง Amazon Search จะสร้างดัชนีสำหรับผลิตภัณฑ์ทั้งหมดที่ขายบน Amazon.com เมื่อลูกค้าเข้าสู่การค้นหา Amazon Search จะใช้เทคนิค ML ที่หลากหลาย รวมถึงโมเดลการเรียนรู้เชิงลึก เพื่อจับคู่ผลิตภัณฑ์ที่เกี่ยวข้องและน่าสนใจกับคำถามของลูกค้า จากนั้นจึงจัดอันดับผลิตภัณฑ์ก่อนที่จะแสดงผลลัพธ์ให้กับลูกค้า
นักวิทยาศาสตร์ของ Amazon Search ได้ใช้ PyTorch Lightning เป็นหนึ่งในเฟรมเวิร์กหลักในการฝึกโมเดลการเรียนรู้เชิงลึกที่ขับเคลื่อนการจัดอันดับของ Search เนื่องจากมีการเพิ่มฟีเจอร์การใช้งานใน ด้านบนของ PyTorch SMDDP ไม่ได้รับการสนับสนุนสำหรับโมเดลการเรียนรู้เชิงลึกที่เขียนใน PyTorch Lightning ก่อนการเปิดตัว SageMaker ใหม่นี้ สิ่งนี้ทำให้นักวิทยาศาสตร์ของ Amazon Search ไม่ต้องการใช้ PyTorch Lightning ในการปรับขนาดการฝึกโมเดลโดยใช้เทคนิคข้อมูลคู่ขนาน ทำให้เวลาในการฝึกอบรมช้าลงอย่างมาก และป้องกันไม่ให้พวกเขาทดสอบการทดลองใหม่ที่ต้องการการฝึกอบรมที่ปรับขนาดได้มากขึ้น
การเปรียบเทียบเบื้องต้นของทีม ผลลัพธ์แสดงเวลาการฝึกเร็วขึ้น 7.3 เท่าสำหรับโมเดลตัวอย่าง เมื่อฝึกบนแปดโหนดเมื่อเปรียบเทียบกับพื้นฐานการฝึกแบบโหนดเดียว โมเดลพื้นฐานที่ใช้ในการเปรียบเทียบเหล่านี้เป็นโครงข่ายประสาท perceptron แบบหลายชั้นที่มีชั้นที่เชื่อมต่อกันหนาแน่นเจ็ดชั้นและพารามิเตอร์มากกว่า 200 ตัว ตารางต่อไปนี้สรุปผลการเปรียบเทียบบนอินสแตนซ์การฝึก SageMaker ml.p3.16xlarge
ต่อไป เราจะเจาะลึกรายละเอียดการเปิดตัวใหม่ หากต้องการ คุณสามารถก้าวผ่าน สมุดบันทึกตัวอย่าง
เรียกใช้ PyTorch Lightning ด้วยไลบรารีการฝึกอบรมแบบกระจายของ SageMaker
เรายินดีที่จะประกาศว่า SageMaker Data Parallel ผสานรวมกับ PyTorch Lightning ภายในการฝึก SageMaker
PyTorch Lightning เป็นเฟรมเวิร์กโอเพนซอร์สที่ให้ความเรียบง่ายสำหรับการเขียนโมเดลที่กำหนดเองใน PyTorch ในบางวิธีที่คล้ายกับที่ Keras ทำเพื่อ TensorFlow หรือแม้กระทั่งเนื้อหาที่ Hugging Face นั้น PyTorch Lightning ให้ API ระดับสูงพร้อมนามธรรมสำหรับฟังก์ชันการทำงานระดับล่างส่วนใหญ่ของ PyTorch เอง ซึ่งรวมถึงการกำหนดโมเดล การทำโปรไฟล์ การประเมิน การตัดแต่งกิ่ง โมเดลคู่ขนาน การกำหนดค่าไฮเปอร์พารามิเตอร์ การเรียนรู้การถ่ายโอน และอื่นๆ
ก่อนหน้านี้ นักพัฒนาซอฟต์แวร์ PyTorch Lightning ไม่แน่ใจเกี่ยวกับวิธีการโยกย้ายโค้ดการฝึกของพวกเขาไปยังระดับสูงอย่างราบรื่น ประสิทธิภาพคลัสเตอร์ SageMaker GPU นอกจากนี้ ไม่มีทางที่พวกเขาจะได้ใช้ประโยชน์จากประสิทธิภาพที่เพิ่มขึ้นซึ่งนำเสนอโดย SageMaker Data Parallel
สำหรับ PyTorch Lightning โดยทั่วไปแล้ว ควรจะมีการเปลี่ยนแปลงโค้ดเพียงเล็กน้อยหรือไม่มีเลยเพื่อเรียกใช้ API เหล่านี้ เกี่ยวกับการฝึกอบรม SageMaker ในสมุดบันทึกตัวอย่าง เราใช้ DDPStrategy และ DDPPlugin วิธีการ p>
มีสามขั้นตอนในการใช้ PyTorch Lightning กับ SageMaker Data Parallel เป็นแบ็กเอนด์ที่ปรับให้เหมาะสม:
ใช้ AWS Deep Learning Container (DLC) เป็นอิมเมจพื้นฐานของคุณ หรือเลือกสร้างคอนเทนเนอร์ของคุณเองและ ติดตั้งแบ็กเอนด์ SageMaker Data Parallel ด้วยตัวคุณเอง ตรวจสอบให้แน่ใจว่าคุณได้รวม PyTorch Lightning ไว้ในแพ็คเกจที่จำเป็นของคุณแล้ว เช่น ไฟล์ Requirement.txt ทำการเปลี่ยนแปลงโค้ดเล็กน้อยในสคริปต์การฝึกอบรมของคุณเพื่อเปิดใช้แบ็กเอนด์ที่ปรับให้เหมาะสม เหล่านี้รวมถึง: นำเข้าไลบรารี SM DDP: นำเข้า smdistributed.dataparallel.torch.torch_smddp ตั้งค่าสภาพแวดล้อม PyTorch Lightning สำหรับ SageMaker: จาก pytorch_lightning.plugins.environments.lightning_environment นำเข้า LightningEnvironment env=LightningEnvironment() env.world_size=lambda: int(os.environ[“WORLD_SIZE”]) env.global_rank=lambda: int(os.environ[“RANK”]) หากคุณกำลังใช้ PyTorch Lightning เวอร์ชันเก่ากว่า 1.5.10 คุณจะต้องเพิ่มอีกสองสาม ขั้นตอน ขั้นแรก เพิ่มตัวแปรสภาพแวดล้อม: os.environ[“PL_TORCH_DISTRIBUTED_BACKEND”]=”smddp”ประการที่สอง ตรวจสอบให้แน่ใจว่าคุณใช้ DDPPlugin แทนที่จะเป็น DDPStrategy หากคุณกำลังใช้เวอร์ชันที่ใหม่กว่า ซึ่งคุณสามารถตั้งค่าได้อย่างง่ายดายโดยวาง requirements.txt ไว้ใน source_dir สำหรับงานของคุณ ก็ไม่จำเป็น ดูรหัสต่อไปนี้: ddp=DDPPlugin(parallel_devices=[torch.device(“cuda”, d) for d in range(num_gpus)], cluster_environment=env) หรือกำหนดแบ็กเอนด์กลุ่มกระบวนการของคุณเป็น”smddp”ในวัตถุ DDPSTrategy. อย่างไรก็ตาม หากคุณใช้ PyTorch Lightning กับแบ็กเอนด์ PyTorch DDP ซึ่งได้รับการสนับสนุนเช่นกัน เพียงลบพารามิเตอร์”process_group_backend”นี้ ดูรหัสต่อไปนี้: ddp=DDPStrategy( cluster_environment=env, process_group_backend=”smddp“, accelerator=”gpu“) ตรวจสอบว่าคุณมี วิธีการแจกจ่ายที่ระบุไว้ในตัวประมาณ เช่น distribution={“smdistributed”:{“dataparallel”:”enabled”:True if you’re using the Herring backend หรือ distribution={“pytorchddp”:”enabled”:True สำหรับรายการพารามิเตอร์ที่เหมาะสมทั้งหมดในพารามิเตอร์การกระจาย โปรดดูเอกสารประกอบของเรา ที่นี่
ตอนนี้คุณสามารถเริ่มงานการฝึกอบรม SageMaker ได้แล้ว! คุณสามารถเริ่มงานการฝึกอบรมผ่าน Python SDK, Boto3, คอนโซล SageMaker, AWS Command Line Interface (AWS CLI) และวิธีการอื่นๆ อีกนับไม่ถ้วน จากมุมมองของ AWS นี่เป็นคำสั่ง API เดียว: create-training-job ไม่ว่าคุณจะเรียกใช้คำสั่งนี้จากเทอร์มินัลในพื้นที่ของคุณ ฟังก์ชัน AWS Lambda, โน้ตบุ๊ก Amazon SageMaker Studio, ไปป์ไลน์ KubeFlow หรือสภาพแวดล้อมการประมวลผลอื่นๆ ขึ้นอยู่กับคุณโดยสมบูรณ์
โปรดทราบว่าการผสานรวมระหว่าง PyTorch ปัจจุบัน Lightning และ SageMaker Data Parallel รองรับเฉพาะ PyTorch เวอร์ชันใหม่กว่าเท่านั้น โดยเริ่มที่ 1.11 นอกจากนี้ รุ่นนี้มีเฉพาะใน AWS DLC สำหรับ SageMaker เริ่มต้นที่ PyTorch 1.12 ตรวจสอบให้แน่ใจว่าคุณชี้ไปที่รูปภาพนี้เป็นฐานของคุณ ใน us-east-1 ที่อยู่นี้จะเป็นดังนี้:
ecr_image=”763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-training:1.12.0-gpu-py38-cu113-ubuntu20.04-sagemaker”
จากนั้นคุณสามารถขยายคอนเทนเนอร์ Docker ของคุณโดยใช้สิ่งนี้เป็นอิมเมจพื้นฐานของคุณ หรือคุณสามารถส่งผ่านสิ่งนี้เป็นตัวแปรไปยังอาร์กิวเมนต์ image_uri ของ ตัวประมาณการฝึกอบรม SageMaker Data Parallel บน SageMaker
ปัญหาที่ใหญ่ที่สุด PyTorch Distributed Data Parallel (DDP) การแก้ปัญหานั้นง่ายมาก: ความเร็ว กรอบงานการฝึกอบรมแบบกระจายที่ดีควรให้ความเสถียร ความน่าเชื่อถือ และที่สำคัญที่สุดคือประสิทธิภาพที่ยอดเยี่ยมในขนาดต่างๆ PyTorch DDP นำเสนอสิ่งนี้ผ่านการจัดหา API ให้กับนักพัฒนาซอฟต์แวร์เพื่อจำลองโมเดลของตนผ่านอุปกรณ์ GPU หลายตัว ในการตั้งค่าทั้งแบบโหนดเดียวและหลายโหนด จากนั้นกรอบงานจะจัดการการแบ่งกลุ่มวัตถุที่แตกต่างกันตั้งแต่ชุดข้อมูลการฝึกไปจนถึงสำเนาแบบจำลองแต่ละชุด โดยการเฉลี่ยการไล่ระดับสีสำหรับสำเนาแบบจำลองแต่ละชุดเพื่อซิงโครไนซ์ในแต่ละขั้นตอน สิ่งนี้สร้างแบบจำลองเดียวเมื่อเสร็จสิ้นการฝึกวิ่งเต็มรูปแบบ แผนภาพต่อไปนี้แสดงกระบวนการนี้
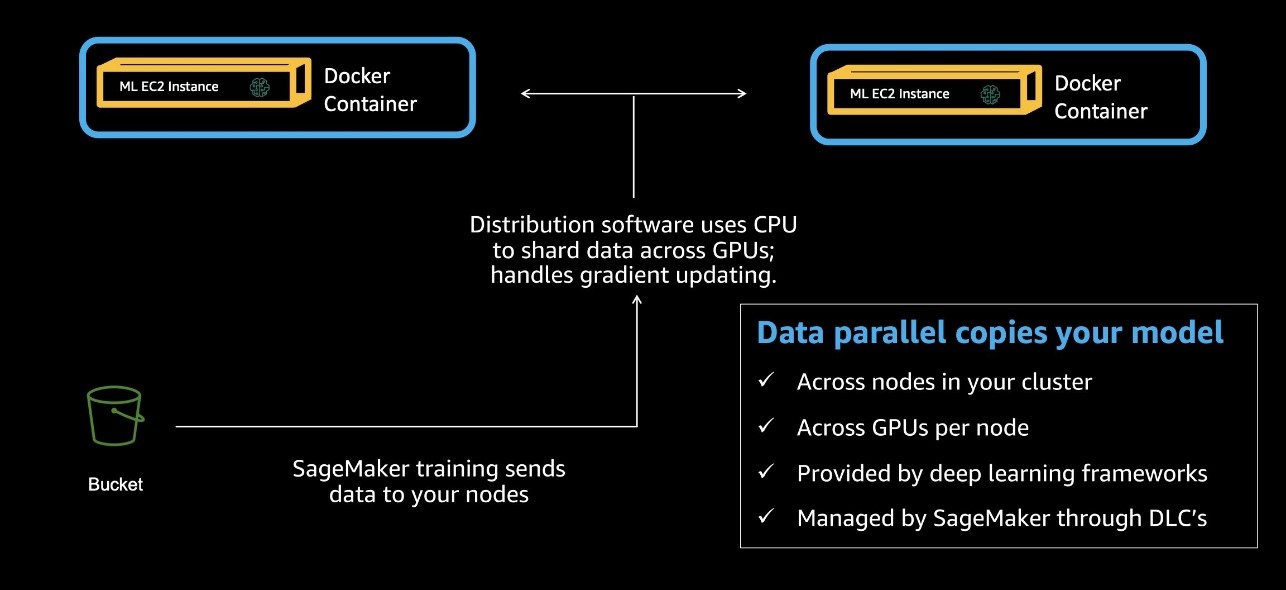
PyTorch DDP เป็นเรื่องปกติในโครงการที่ใช้ชุดข้อมูลขนาดใหญ่ ขนาดที่แม่นยำของชุดข้อมูลแต่ละชุดจะแตกต่างกันอย่างมาก แต่แนวทางทั่วไปคือการปรับขนาดชุดข้อมูล ขนาดการคำนวณ และขนาดโมเดลในอัตราส่วนที่ใกล้เคียงกัน เรียกอีกอย่างว่ากฎหมายว่าด้วยมาตราส่วน การผสมผสานที่ลงตัวระหว่างสามข้อนี้มีขึ้นอย่างมากสำหรับการอภิปรายและจะแตกต่างกันไปตาม ในการใช้งาน ที่ AWS จากการทำงานร่วมกับลูกค้าหลายราย เราสามารถเห็นประโยชน์จากกลยุทธ์ข้อมูลแบบขนานได้อย่างชัดเจนเมื่อขนาดชุดข้อมูลโดยรวมอย่างน้อยสองสามสิบ GB เมื่อชุดข้อมูลมีขนาดใหญ่ขึ้น การใช้กลยุทธ์ข้อมูลคู่ขนานบางประเภทก็เป็นเทคนิคที่สำคัญในการเร่งการทดสอบโดยรวมและปรับปรุงเวลาของคุณให้คุ้มค่า
ก่อนหน้านี้ ลูกค้าที่ใช้ PyTorch DDP สำหรับการฝึกอบรมแบบกระจาย ในสถานที่หรือในสภาพแวดล้อมการประมวลผลอื่นๆ ขาดกรอบงานในการโยกย้ายโปรเจ็กต์ของพวกเขาไปยัง SageMaker Training อย่างง่ายดาย เพื่อใช้ประโยชน์จาก GPU ประสิทธิภาพสูงพร้อมระนาบการควบคุมที่ไร้รอยต่อ โดยเฉพาะอย่างยิ่ง พวกเขาจำเป็นต้องย้ายข้อมูลเฟรมเวิร์กคู่ขนานไปยัง SMDDP หรือพัฒนาและทดสอบความสามารถของ PyTorch DDP บน SageMaker Training ด้วยตนเอง วันนี้ SageMaker Training ยินดีที่จะมอบประสบการณ์ที่ราบรื่นให้กับลูกค้าที่เริ่มต้นใช้งานโค้ด PyTorch DDP
หากต้องการใช้งานอย่างมีประสิทธิภาพ คุณไม่จำเป็นต้องทำการเปลี่ยนแปลงใดๆ กับสคริปต์การฝึกอบรมของคุณ
คุณสามารถดูพารามิเตอร์ใหม่นี้ได้ในโค้ดต่อไปนี้ ในพารามิเตอร์การกระจาย เพียงเพิ่ม pytorchddp และตั้งค่าให้เปิดใช้งานเป็นจริง
estimator=PyTorch( base_job_name=”pytorch-dataparallel-mnist”, source_dir=”code”, entry_point=”my_model.py”,… # การฝึกอบรมโดยใช้ SMDataParallel Distributed Training Framework distribution=”pytorchddp”:”enabled”:”true”)
การกำหนดค่าใหม่นี้เริ่มต้นที่ SageMaker Python SDK เวอร์ชัน 2.102.0 และ PyTorch DLC’s 1.11
สำหรับ PyTorch DDP นักพัฒนาที่คุ้นเคยกับเฟรมเวิร์ก torchrun ยอดนิยม การรู้ว่านี่ไม่ใช่ ไม่จำเป็นในสภาพแวดล้อมการฝึกอบรม SageMaker ซึ่งมีความทนทานต่อข้อผิดพลาดที่แข็งแกร่งอยู่แล้ว อย่างไรก็ตาม เพื่อลดการเขียนโค้ดใหม่ คุณสามารถนำสคริปต์ตัวเรียกใช้งานอื่นที่เรียกใช้คำสั่งนี้เป็นจุดเริ่มต้นของคุณ
ตอนนี้นักพัฒนา PyTorch สามารถย้ายสคริปต์ของตนไปยัง SageMaker ได้อย่างง่ายดาย เพื่อให้แน่ใจว่าสคริปต์และคอนเทนเนอร์สามารถทำงานได้อย่างราบรื่นในหลาย ๆ สภาพแวดล้อมในการประมวลผล
ซึ่งจะช่วยเตรียมพวกเขาให้พร้อมสำหรับการใช้ประโยชน์จาก ไลบรารีการฝึกอบรมแบบกระจายของ SageMaker ที่มีโทโพโลยีการฝึกอบรมที่ปรับให้เหมาะกับ AWS เพื่อเพิ่มประสิทธิภาพการเร่งความเร็วได้ถึง 40% สำหรับนักพัฒนา PyTorch นี่คือโค้ดบรรทัดเดียว! สำหรับโค้ด PyTorch DDP คุณสามารถตั้งค่าแบ็กเอนด์เป็น smddp ในการเริ่มต้น (โปรดดู แก้ไขสคริปต์การฝึกอบรม PyTorch) ดังที่แสดงในโค้ดต่อไปนี้:
นำเข้า smdistributed.dataparallel.torch.torch_smddp นำเข้า torch.distributed เป็น dist dist.init_process_group(backend=’smddp’)
ดังที่เราเห็นข้างต้น คุณยังสามารถตั้งค่าแบ็กเอนด์ของ DDPStrategy เป็น smddp เมื่อใช้ Lightning ซึ่งอาจนำไปสู่ 40 % การเร่งความเร็วโดยรวม สำหรับคลัสเตอร์ขนาดใหญ่! หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับการฝึกอบรมแบบกระจายบน SageMaker โปรดดูที่ การสัมมนาผ่านเว็บแบบออนดีมานด์ ซึ่งรองรับ โน้ตบุ๊ก เอกสารที่เกี่ยวข้อง และเอกสาร
บทสรุป
ในโพสต์นี้ เราได้แนะนำคุณลักษณะใหม่สองอย่างภายในกลุ่มการฝึกอบรม SageMaker สิ่งเหล่านี้ทำให้นักพัฒนา PyTorch ใช้โค้ดที่มีอยู่บน SageMaker ทั้ง PyTorch DDP และ PyTorch Lightning ได้ง่ายขึ้นมาก
เรายังแสดงให้เห็นว่า Amazon Search ใช้ SageMaker Training เพื่อฝึกอบรมโมเดลการเรียนรู้เชิงลึกของพวกเขาอย่างไร โดยเฉพาะอย่างยิ่ง PyTorch Lightning ด้วย SageMaker Data Parallel ที่ปรับปรุงไลบรารีส่วนรวมให้เป็นแบ็กเอนด์ การย้ายไปยังการฝึกอบรมแบบกระจายช่วยให้ Amazon Search ใช้เวลาในการฝึกเร็วขึ้น 7.3 เท่า
เกี่ยวกับผู้เขียน
Emily Webber เข้าร่วม AWS หลังจากเปิดตัว SageMaker และพยายามบอกให้โลกรู้ตั้งแต่นั้นมา! นอกเหนือจากการสร้างประสบการณ์ ML ใหม่ให้กับลูกค้าแล้ว เอมิลี่ชอบนั่งสมาธิและศึกษาพุทธศาสนาในทิเบต
 Karan Dhiman เป็นวิศวกรพัฒนาซอฟต์แวร์ที่ AWS ซึ่งตั้งอยู่ในเมืองโตรอนโต ประเทศแคนาดา เขาหลงใหลอย่างมากเกี่ยวกับพื้นที่ Machine Learning และสร้างโซลูชันสำหรับการเร่งปริมาณงานการประมวลผลแบบกระจาย
Karan Dhiman เป็นวิศวกรพัฒนาซอฟต์แวร์ที่ AWS ซึ่งตั้งอยู่ในเมืองโตรอนโต ประเทศแคนาดา เขาหลงใหลอย่างมากเกี่ยวกับพื้นที่ Machine Learning และสร้างโซลูชันสำหรับการเร่งปริมาณงานการประมวลผลแบบกระจาย
 Vishwa Karia เป็นวิศวกรพัฒนาซอฟต์แวร์ที่ AWS Deep Engine ความสนใจของเธออยู่ที่จุดตัดระหว่าง Machine Learning และ Distributed Systems และเธอยังหลงใหลในการเสริมสร้างพลังให้กับผู้หญิงในด้านเทคโนโลยีและ AI
Vishwa Karia เป็นวิศวกรพัฒนาซอฟต์แวร์ที่ AWS Deep Engine ความสนใจของเธออยู่ที่จุดตัดระหว่าง Machine Learning และ Distributed Systems และเธอยังหลงใหลในการเสริมสร้างพลังให้กับผู้หญิงในด้านเทคโนโลยีและ AI
Eiman Elnahrawy เป็นวิศวกรซอฟต์แวร์หลักที่ Amazon Search ซึ่งเป็นผู้นำด้านความพยายามในการเร่งความเร็ว การปรับขนาด และระบบอัตโนมัติของ Machine Learning ความเชี่ยวชาญของเธอครอบคลุมหลายด้าน รวมถึง Machine Learning, Distributed Systems และ Personalization
ให้คะแนนโพสต์นี้
การแบ่งปันคือความห่วงใย!

