.fb-comments,.fb-comments span,.fb-comments span iframe[style]{min-width:100%!important;width:100%!important}
Isang bagong exploration initiative na kinasasangkutan ng US at China ang nagmungkahi ng paggamit ng Generative Adversarial Networks (GANs) para i-maximize ang realismo ng pagmamaneho ng mga simulator.
Sa isang nobela, kunin lang ang problema sa pagbuo ng mga photorealistic na sitwasyon sa pagmamaneho ng POV. , ang mga siyentipiko ay nagdisenyo ng isang hybrid na pamamaraan na gumaganap sa lakas ng iba’t ibang mga pamamaraan, sa pamamagitan ng paghahalo ng mas photorealistic na output ng CycleGAN-based na mga system na may mga karagdagang tampok na ginawa ng kumbensyon, na kailangang magkaroon ng mas malaking yugto ng elemento at pagkakapare-pareho, ang ganitong uri ng bilang mga marka ng highway at ang aktwal na mga sasakyan na naobserbahan mula sa punto ng relo ng driver.
Ang Hybrid Generative Neural Graphics (HGNG) ay nagbibigay ng bagong direksyon para sa mga simulation sa pagmamaneho na nagpapanatili ng katumpakan ng mga 3D na modelo para sa mga mahahalagang bahagi (ganito ang uri ng kalsada markings at sasakyan), kahit na naglalaro sa lakas ng mga GAN sa paggawa ng kaakit-akit at hindi paulit-ulit na background at ambient na detalye. Resource
Ang programa, na kilala bilang Hybrid Generative Ang Neural Graphics (HGNG), ay nag-iiniksyon ng talagang pinipigilan na output mula sa isang tradisyonal, CGI-pangunahing nakabatay sa pagmamaneho simulator sa isang pipeline ng GAN, kung saan ang NVIDIA SPADE framework tungkol sa gawain ng teknolohiya ng ecosystem.
Ang kalamangan, ayon sa mga may-akda, ay ang mga kapaligiran sa pagmamaneho ay bubuo sa potensyal na mas sari-sari, na lumilikha ng mas nakaka-engganyong karanasan. Tulad ng kinatatayuan nito, kahit na ang pag-convert ng CGI output sa photoreal neural rendering output ay hindi matugunan ang problema ng pag-uulit, dahil ang pangunahing footage na nakapasok sa neural pipeline ay napipigilan ng mga limitasyon ng mga kapaligiran sa disenyo, at ang kanilang pagkahilig na ulitin ang mga texture at meshes.

Na-convert na footage mula sa 2021 papel‘Pagpapahusay sa photorealism enhancement’, na patuloy na umaasa sa CGI-rendered footage, kabilang ang background at pangkalahatang ambient na elemento, na pumipigil sa pagpili ng kapaligiran sa simulate na karanasan sa pagtatrabaho. Pinagmulan: https://www.youtube.com/enjoy?v=P1IcaBn3ej0
Sinasaad ng papel*:
‘Ang katapatan ng isang karaniwang simulator sa pagmamaneho ay nakadepende sa pinakamataas na kalidad ng laptop graphics pipeline nito, na binubuo ng mga 3D na produkto, texture, at rendering motor. Ang malaking kalidad na mga uri at texture ng 3D ay nangangailangan ng pagiging artisan, habang ang rendering motor ay dapat magpatakbo ng mga kumplikadong kalkulasyon ng pisika para sa praktikal na paglalarawan ng ilaw at pagtatabing.’
Ang bagong papel ay pinamagatang Photorealism in Driving Simulations: Blending Generative Adversarial Impression Synthesis with Rendering, at nagmula sa mga mananaliksik sa Department of Electrical and Laptop Engineering sa Ohio Condition College, at Chongqing Changan Automobile Co Ltd sa Chongqing, China.
Track record Material
Binabago ng HGNG ang semantic na layout ng isang input na CGI-generated na eksena sa pamamagitan ng paghahalo ng bahagyang nai-render na foreground na materyal sa mga GAN-generated na kapaligiran. Kahit na ang mga siyentipiko ay nag-eksperimento sa maraming mga dataset kung saan sanayin ang mga bersyon, ang pinaka mahusay ay napatunayang ang KITTI Vision Benchmark Suite, na kadalasang nagtatampok ng mga pagkuha ng driver-POV substance mula sa German town ng Karlsruhe.
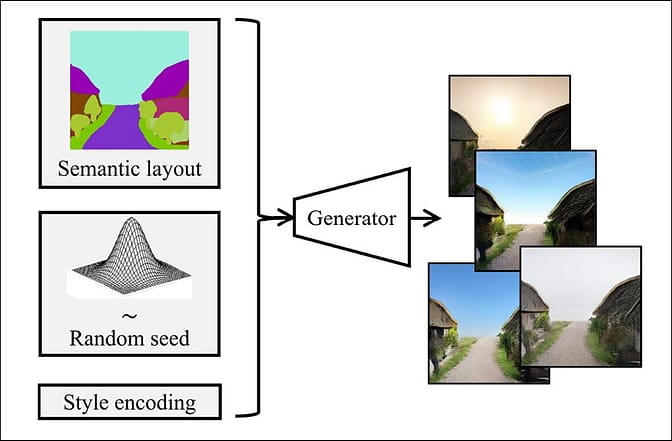
Nag-eksperimento ang mga siyentipiko sa dalawang Conditional GAN (cGAN) at CYcleGAN (CyGAN) bilang generative network, na natuklasan sa huli na ang bawat isa ay may mga kalakasan at kahinaan: Kasama sa cGAN ang mga nakapares na dataset, at CyGAN ay hindi. Gayunpaman, hindi magagawa ng CyGAN sa ngayon na madaig ang makabagong likha sa mga karaniwang simulator, habang naghihintay ng higit pang mga pagsulong sa pagbagay sa lugar at pagkakapare-pareho ng ikot. Bilang resulta, nakukuha ng cGAN, kasama ang mga karagdagang detalye ng ipinares na impormasyon, ang pinakamagagandang resulta sa ngayon.
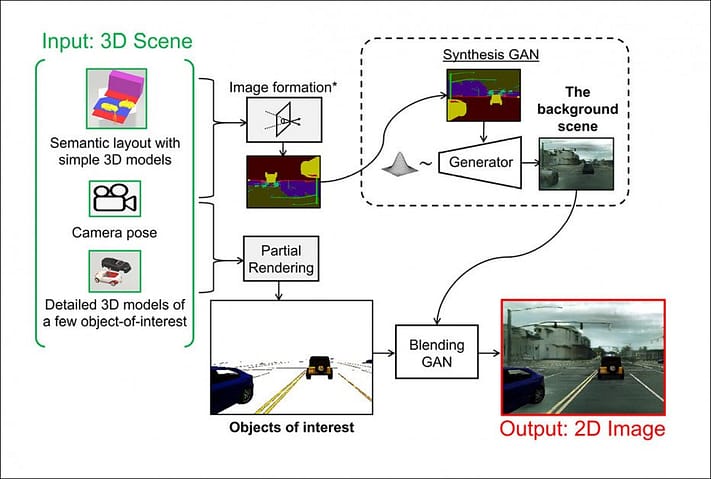
Ang konseptwal na arkitektura ng HGNG.
Sa HGNG neural graphics pipeline, ang mga 2D na representasyon ay hinuhubog mula sa CGI-synthesized na mga eksena. Ang mga bagay na ipinapasa sa daloy ng GAN mula sa pag-render ng CGI ay minimal hanggang sa mga’mahahalagang’bahagi, kasama ang mga marka ng kalye at mga sasakyang de-motor, na hindi na ngayon ma-render ng isang GAN mismo sa sapat na temporal na regularidad at integridad para sa isang driving simulator. Ang cGAN-synthesized na graphic ay ihahalo sa bahagyang physics-based na pag-render.
Mga Pagsusuri
Upang suriin ang diskarte, ginamit ng mga siyentipiko ang SPADE, na pinag-aralan sa Cityscapes, upang baguhin ang semantic na layout ng eksena sa photorealistic na output. Ang CGI resource ay nagmula sa open supply driving simulator CARLA, na gumagamit ng Unreal Engine 4 (UE4).

Output mula sa open resource driving simulator na CARLA. Supply: https://arxiv.org/pdf/1711.03938.pdf
Ang shading at lighting motor ng UE4 ang nagbigay ng semantic structure at ang bahagyang nai-render na mga larawan, na may mga autos at lane markings lang na output. Naabot ang paghahalo sa isang GP-GAN na okasyong tinuruan sa Transient Characteristics Database, at lahat ng eksperimento ay tumatakbo sa NVIDIA RTX 2080 na may 8 GB ng GDDR6 VRAM.
Sinuri ng mga mananaliksik para sa pagpapanatili ng semantiko – ang kapasidad ng output graphic sa tumutugma sa paunang semantic segmentation mask na dapat na template para sa eksena.
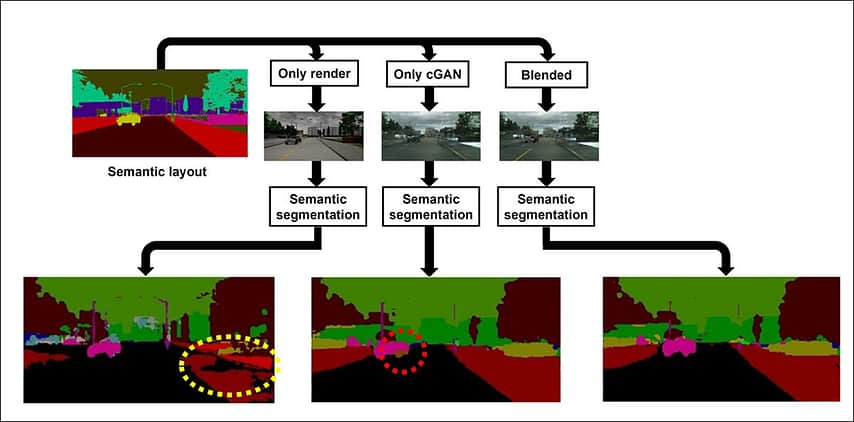
Sa mga visual na pagsubok naunang nabanggit, nakikita natin na sa’render only’na graphic (natitira sa ibaba), ang kabuuang render ay hindi nakakakuha ng mga kapani-paniwalang anino. Pansinin ng mga mananaliksik na sa artikulong ito (dilaw na bilog) ang mga anino ng mga puno na nahuhulog sa bangketa ay nagkamali sa pag-uuri ng DeepLabV3 (ang semantic segmentation framework na ginamit para sa mga eksperimentong ito) bilang’daan’na nakasulat na nilalaman.
Sa gitnang column-move, nakita namin na ang mga sasakyan na itinatag ng cGAN ay walang sapat na maaasahang kahulugan upang maging magagamit sa isang driving simulator (purple circle). Sa pinakamainam na paglipat ng column, ang pinaghalong imahe ay umaayon sa tunay na kahulugan ng semantiko, habang pinapanatili ang mga kritikal na bahagi na pangunahing nakabatay sa CGI.
Upang suriin ang pagiging totoo, ginamit ng mga mananaliksik ang Frechet Inception Length (FID) bilang pangkalahatang sukatan ng pagganap, dahil maaari itong gumana sa mga ipinares na detalye o hindi nakapares na kaalaman.
Nagamit ang ilang dataset bilang totoong katotohanan: Cityscapes, KITTI, at ADE20K.
Natapos ang mga larawan ng output sa kaibahan laban sa bawat isa at lahat ng nagtatrabaho sa mga marka ng FID, at laban sa physics-based na karamihan (i.e., CGI) pipeline, habang sinusuri din ang semantic retention.
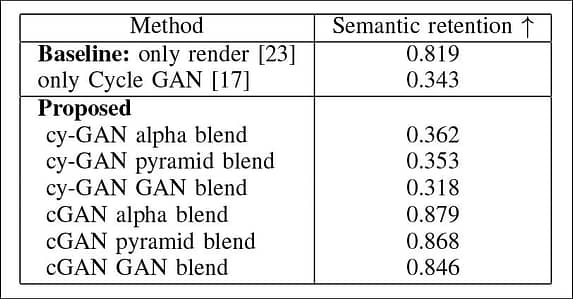
Sa mga resultang natapos, na nauugnay sa sema Ang pagpapanatili, mas mahusay na mga marka ay mas mahusay, kasama ang CGAN pyramid-based na pamamaraan (1 sa isang bilang ng mga pipeline na sinuri ng mga siyentipiko) ang pinakamataas na marka.
Ang mga epekto na nakalarawan kaagad sa naunang nabanggit ay nauugnay sa mga marka ng FID, na may pinakamataas na marka ng HGNG bilang resulta ng paggamit ng dataset ng KITTI.
Ang diskarteng’Only render'( na tinutukoy bilang [23]) ay tumutukoy sa output mula sa CARLA, isang CGI na kilusan na hindi inaasahang maging photorealistic.

Ang mga husay na benepisyo sa kumbensyonal na rendering motor (‘c’sa impression na kaagad na binanggit) ay nagpapakita ng hindi makatotohanang malayong background na mga katotohanan, ang ganitong uri ng bilang mga puno at halaman, kahit bagama’t nangangailangan ng mga detalyadong modelo at just-in-time na paglo-load ng mesh, kasing perpekto ng iba pang mga paggamot na masinsinang processor. Sa gitna (b), makikita natin na nabigo ang cGAN na makakuha ng kasiya-siyang kahulugan para sa mga kinakailangang bagay, mga sasakyan at mga marka ng kalye. Sa iminungkahing pinaghalong output (a), mahusay ang kahulugan ng kotse at kalsada, kahit na ang kapaligiran ay iba-iba at photorealistic.
Ang papel ay nagtatapos sa pamamagitan ng pagmumungkahi na ang temporal na regularidad ng GAN-ginawa na seksyon ng ang pag-render ng pipeline ay maaaring mapataas sa pamamagitan ng paggamit ng mas malalaking dataset ng lungsod, at ang pangmatagalang gawain sa path na ito ay maaaring mag-alok sa iyo ng tunay na pagpipilian sa mataas na presyo na neural transformation ng mga stream na pangunahing nakabatay sa CGI, bagama’t nagbibigay ng mas mataas na realismo at saklaw.
* Ang aking conversion ng mga inline na pagsipi ng mga may-akda sa mga hyperlink.
Inihayag ang unang pagkakataon noong ika-23 ng Hulyo 2022.
I-rate ang post na ito
Ang pagbabahagi ay nagmamalasakit!

