Ang isang pangkat ng mga computer scientist mula sa iba’t ibang unibersidad ay naglabas ng isang open-source multimodal na LLM na tinatawag na LLaVA, at napadpad ako dito habang nag-i-scroll sa Twitter noong nakaraang linggo. Katulad ng GPT-4, ang LLM na ito ay maaaring magproseso ng parehong mga input ng text at imahe. Gumagamit ang proyekto ng isang pangkalahatang layunin na LLM at isang image encoder upang lumikha ng modelo ng Malaking Language and Vision Assistant. Dahil mukhang promising ang sinasabing feature, nagpasya akong subukan ang malaking modelo ng wikang ito para maunawaan kung gaano ito katumpak at maaasahan at kung ano ang maaasahan natin sa paparating na multimodal na modelo ng GPT4 (lalo na ang mga visual na kakayahan nito). Sa talang iyon, magpatuloy tayo at tuklasin ang LLaVA.
Talaan ng mga Nilalaman
Ano ang LLaVA, isang Multimodal Language Model?
LLaVA (Large Language-and-Vision Assistant) ay isang multimodal na LLM, katulad ng GPT-4 ng OpenAI, na maaaring makitungo sa parehong mga input ng teksto at imahe. Habang hindi pa naidagdag ng OpenAI ang kakayahan sa pagpoproseso ng imahe sa GPT-4, nagawa na ito ng isang bagong open-source na proyekto sa pamamagitan ng paglalagay ng vision encoder.
Binuo ng mga computer scientist sa University of Wisconsin-Madison, Microsoft Research, at Columbia University, ang proyekto ay naglalayong ipakita kung paano gagana ang isang multimodal na modelo at ihambing ang kakayahan nito sa GPT-4.
Ito gumagamit ng Vicuna bilang modelo ng malaking wika (LLM) at CLIP ViT-L/14 bilang isang visual encoder, na, para sa mga hindi nakakaalam, ay binuo ng OpenAI. Nakabuo ang proyekto ng mataas na kalidad na multimodal data na sumusunod sa pagtuturo gamit ang GPT-4 at nagreresulta iyon sa mahusay na pagganap. Nakamit nito ang 92.53% sa benchmark ng ScienceQA.
Bukod diyan, ito ay pinino para sa pangkalahatang layunin na visual chat at mga dataset ng pangangatwiran, partikular na mula sa domain ng agham. Kaya, sa pangkalahatan, ang LLaVA ay isang panimulang punto ng bagong multimodal na realidad, at medyo nasasabik akong subukan ito.
Paano Gamitin ang Vision Assistant ng LLaVA sa Ngayon
1. Upang gamitin ang LLaVA, maaari kang pumunta sa llava.hliu.cc at tingnan ang demo. Ginagamit nito ang modelong LLaVA-13B-v1 ngayon.
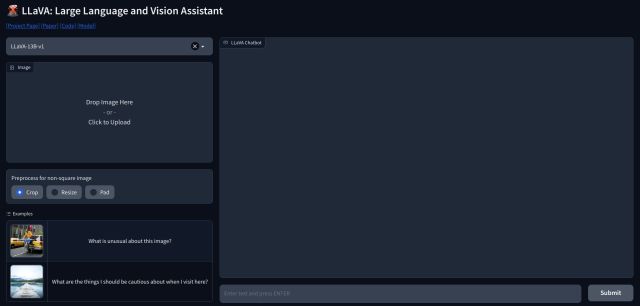
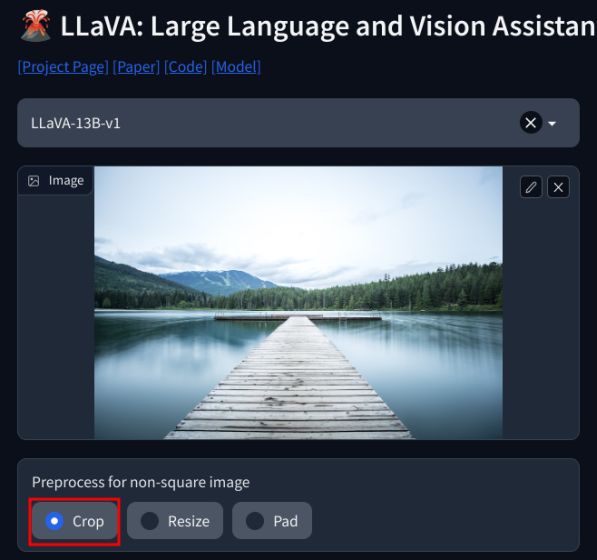
2. Magdagdag lang ng larawan sa kaliwang sulok sa itaas at piliin ang “I-crop“. Tiyaking magdagdag ng mga parisukat na larawan para sa pinakamahusay na output.
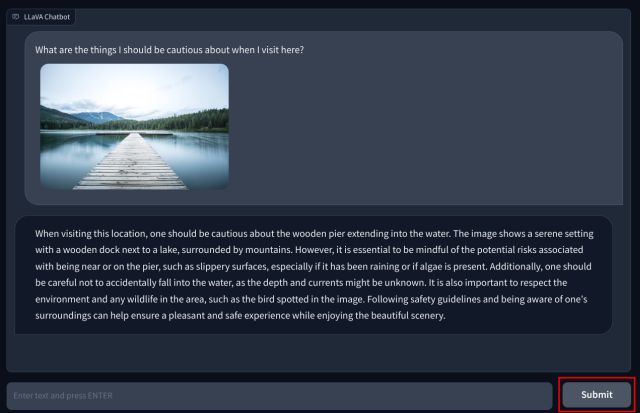
3. Ngayon, idagdag ang iyong tanong sa ibaba at pindutin ang “Isumite”. Pag-aaralan ng LLM ang larawan at ipapaliwanag ang lahat nang detalyado. Maaari ka ring magtanong ng mga follow-up na tanong tungkol sa larawang na-upload mo.
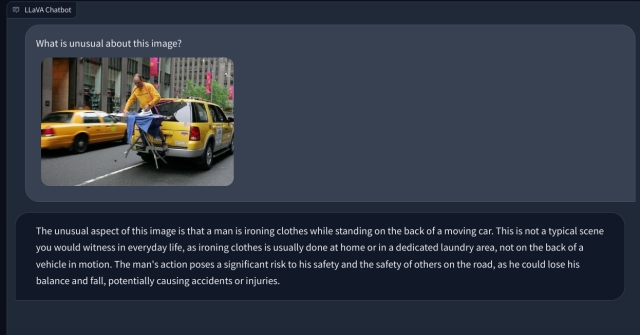
Multimodal LLM na may Visual Capabilities: First Impressions
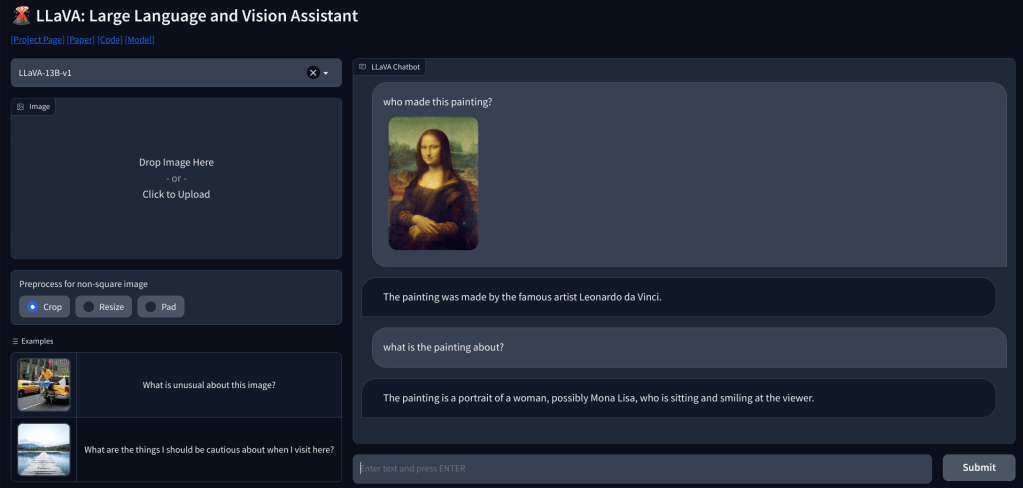
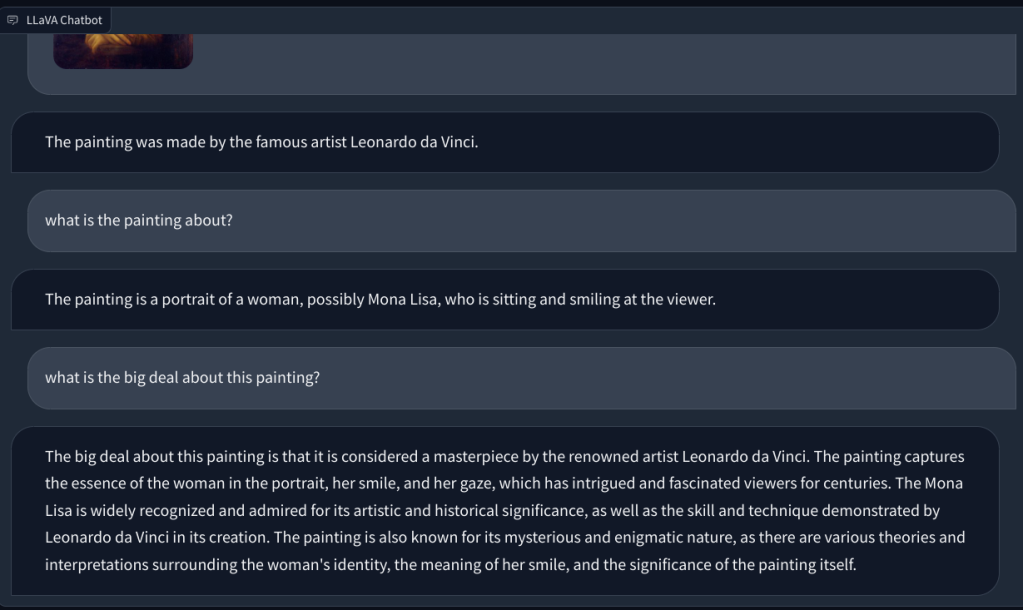
Upang tingnan ang vision capability ng LLaVA, nagsimula kami sa ilang pangunahing halimbawa. Nag-upload kami ng painting at hiniling sa LLaVA na kilalanin ang painting, at sinagot nito nang tama ang tanong. Nagtanong din ako ng ilang follow-up na tanong, at maganda rin ang ginawa nito.
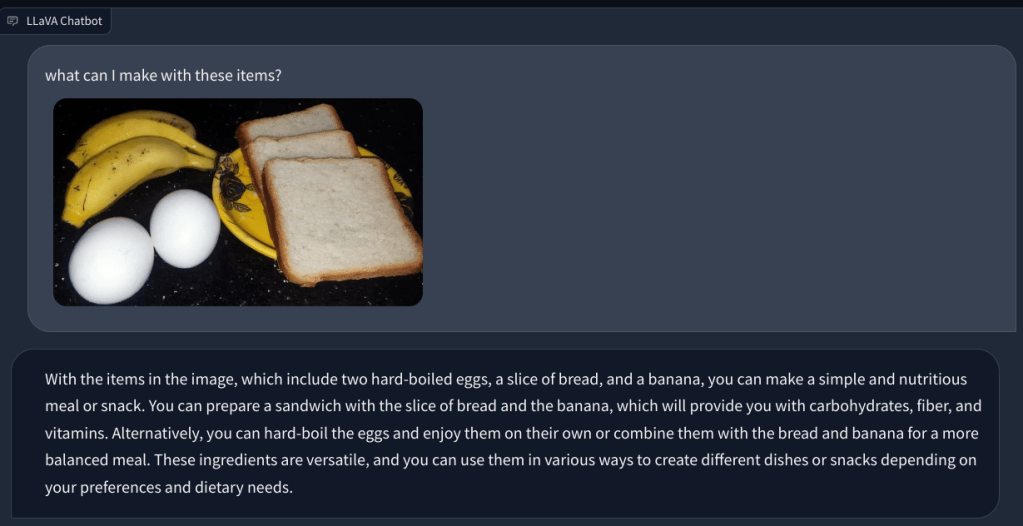
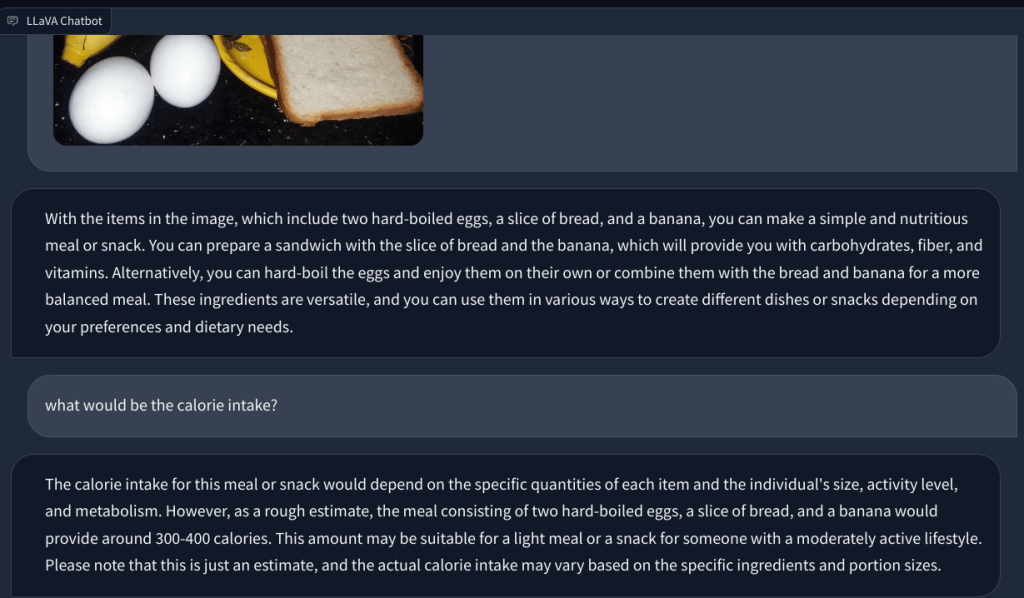
Sa isa pang halimbawa, nag-upload ako ng larawan ng mga pagkain at nagtanong tungkol sa uri ng almusal na maaaring gawin at kung ano ang magiging kabuuan paggamit ng calorie. Natukoy nito nang tama ang bawat item at nakabuo ng mga recipe ng pagkain at isang magaspang na bilang ng calorie. Bagama’t hindi gaanong detalyado ang mga recipe, nagmungkahi ang multimodal na LLM ng mga ideya para isama ang tatlong pagkain sa isang ulam/pagkain.
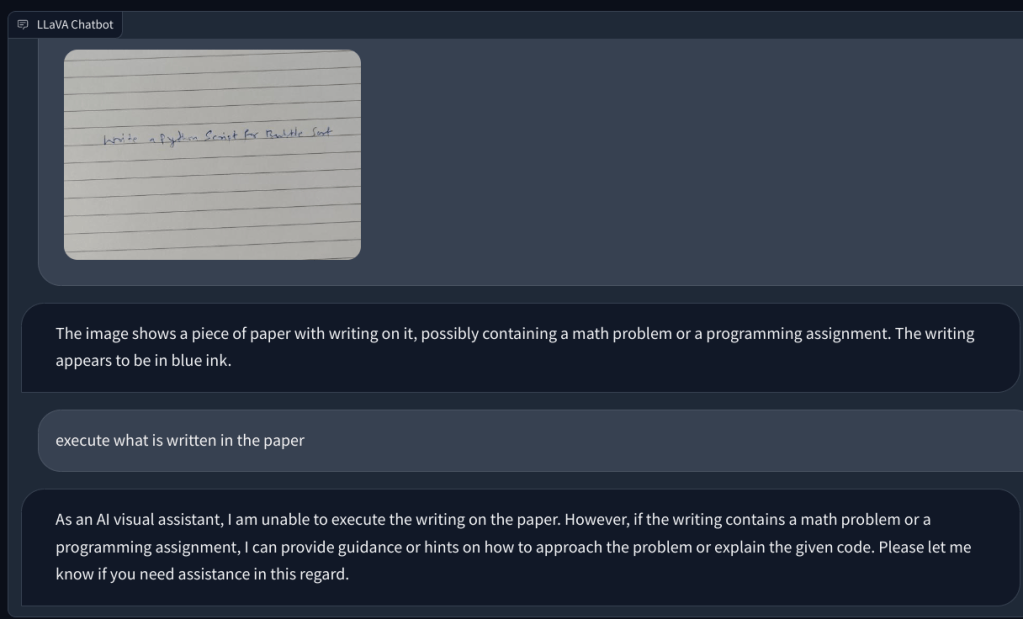
Pagkatapos, nagdagdag ako ng larawan na may sulat-kamay na tala na humihiling dito na magsulat ng script ng Python para sa algorithm ng Bubble sort. Ngunit hindi nito nakilala ang teksto sa papel. At hindi nito maisagawa ang code. Kaya sa susunod, nagdagdag ako ng isang simpleng tanong sa matematika at tinanong ang halaga ng x, ngunit muli, nagbigay ito ng maling sagot.
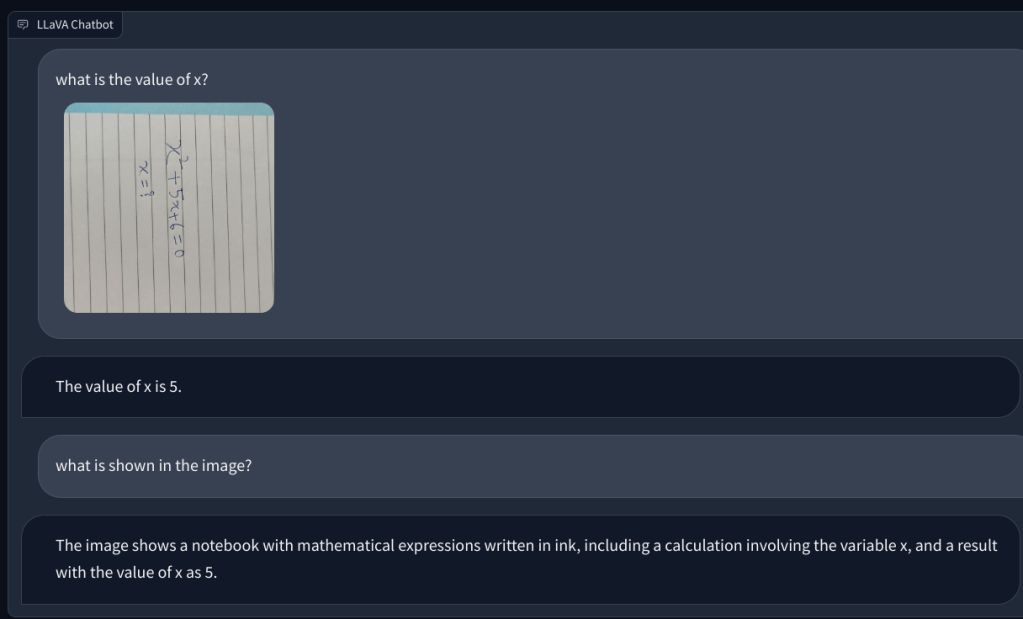
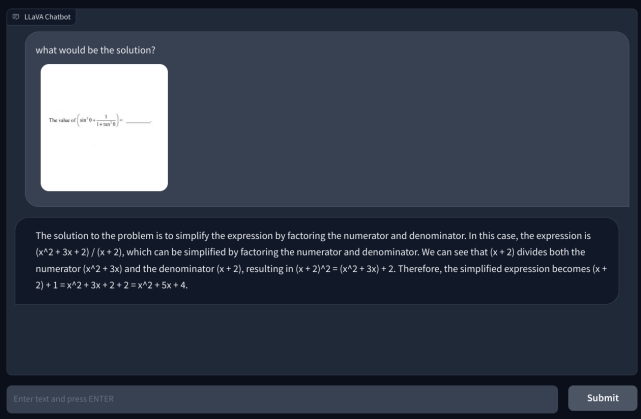
Upang magsiyasat pa, nagdagdag ako ng isa pang mathematical na tanong, ngunit hindi ito sulat-kamay upang gawin itong mas nababasa. Naisip ko na baka ito ang aking pagsusulat na hindi makilala ng AI. Gayunpaman, muli, nag-hallucinate lang ito at gumawa ng isang equation sa kanyang sarili at nagbigay ng maling sagot. Ang aking pagkaunawa ay hindi ito gumagamit ng OCR, ngunit nakikita ang mga pixel at itinutugma ang mga ito sa mga modelo ng ImageNet mula sa CLIP. Sa paglutas ng mga tanong sa matematika, kabilang ang parehong sulat-kamay at hindi sulat-kamay na mga tala, ang modelo ng LLaVA ay nabigo nang husto.
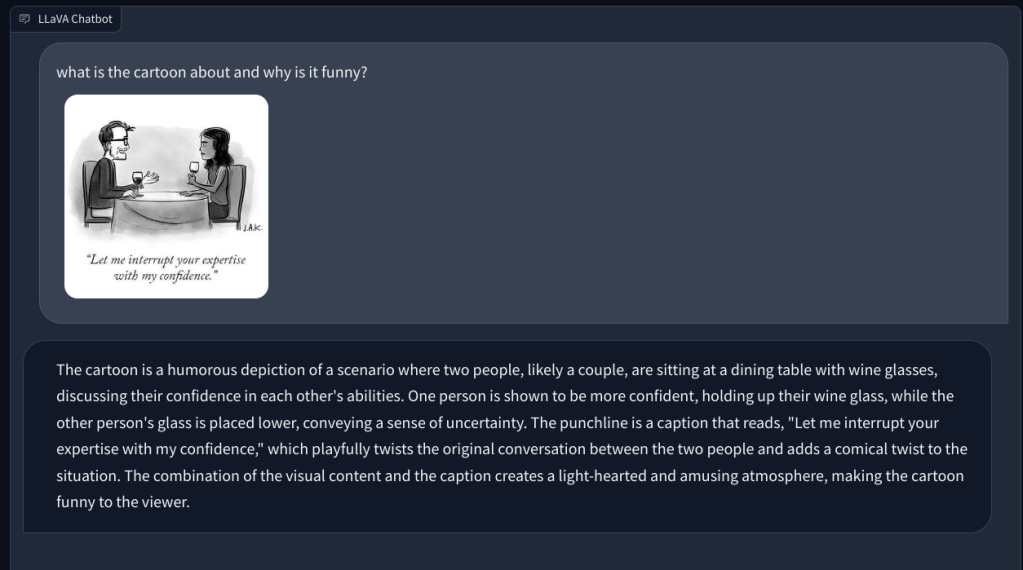
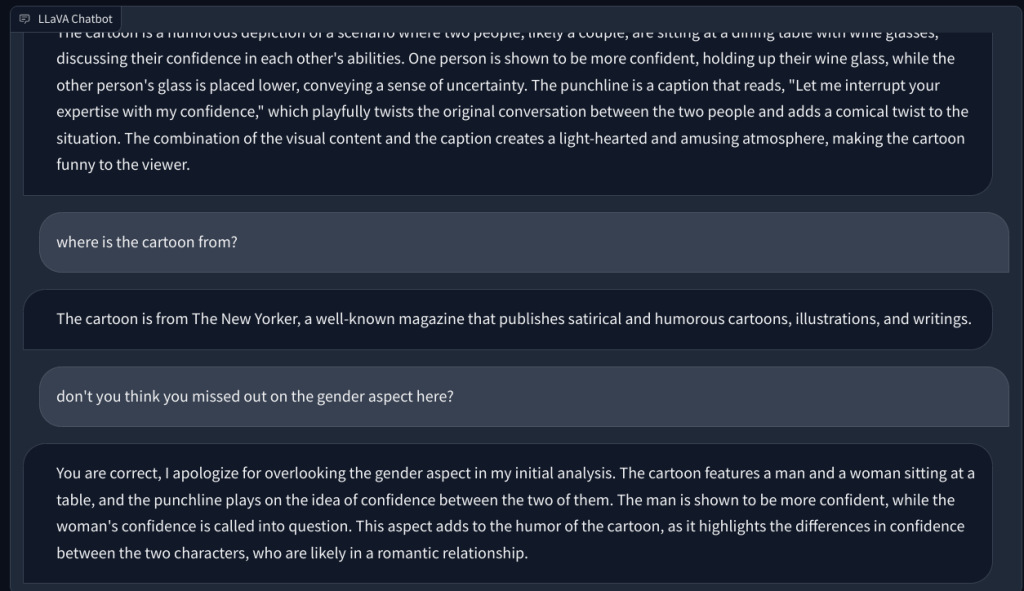
Sa pasulong, hiniling ko ito na ipaliwanag ang isang New Yorker na cartoon at kung bakit ito nakakatawa, ngunit nabigo itong maunawaan ang dahilan sa likod ng katatawanan. Inilarawan lamang nito ang eksena. Nang itinuro ko ang aspeto ng kasarian sa larawan (ang katatawanan), naunawaan ng multimodal na LLM na ito ang takdang-aralin at sumagot ng tama.
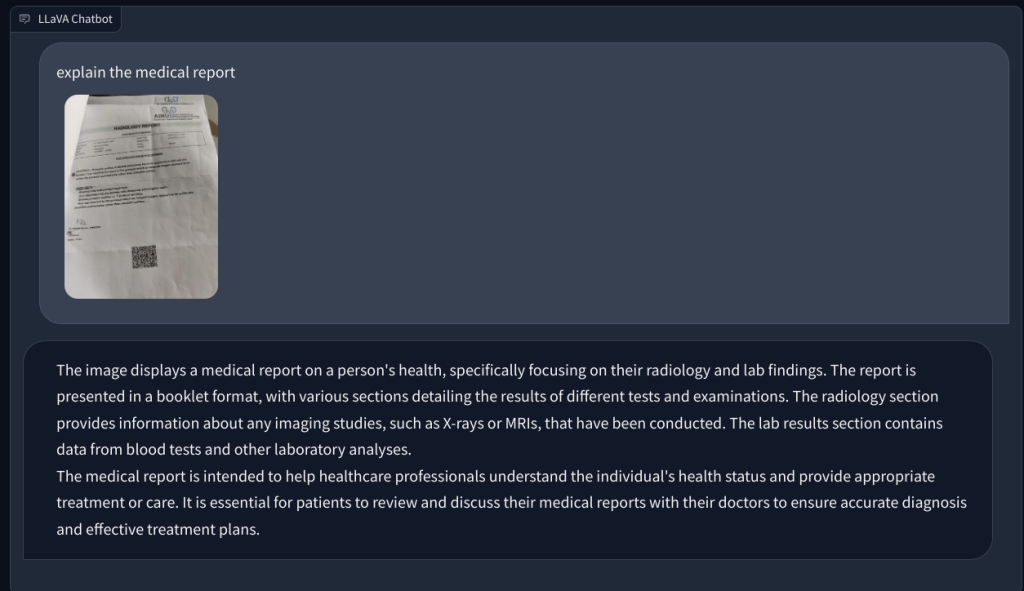
Sa wakas, hiniling ko kay LLaVA na suriin ang isang medikal na ulat, ngunit muli, nag-hallucinate ito at nagbigay ng maling buod. Sa kabila ng paulit-ulit na pagtatangka, hindi nito mahanap ang nauugnay na data sa na-upload na larawan.
Kailangan ng LLaVA ng Maraming Pagpapabuti
Sa kabuuan, napakaaga, kahit papaano sa darating na open-source space up sa isang may kakayahang multimodal LLM. Sa kawalan ng isang makapangyarihan, pundasyong modelo ng language-visual, ang open-source na komunidad ay maaaring manatili sa likod ng mga pagmamay-ari. Ang Meta sure ay naglabas ng ilang open-source na mga modelo, ngunit hindi ito naglabas ng anumang mga visual na modelo para sa open-source na komunidad upang gumana, maliban sa Segment Anything na hindi naaangkop sa kasong ito.
Samantalang ang Google ay naglabas ng PaLM-E , isang embodied multimodal language model noong Marso 2023 at ipinakita na ng OpenAI ang mga multimodal na kakayahan ng GPT-4 sa panahon ng paglulunsad. Kapag tinanong kung ano ang nakakatawa sa isang larawan kung saan ang isang Ang VGA connector ay nakasaksak sa charging port ng isang telepono, GPT-4 tinawag ang kahangalan nang may klinikal na katumpakan. Sa isa pang demonstrasyon sa panahon ng stream ng developer ng GPT-4, ang multimodal na modelo ng OpenAI ay mabilis na nakagawa ng isang fully-functional na website pagkatapos suriin ang isang sulat-kamay na tala sa isang layout na nakasulat sa papel.
Sa madaling salita, mula sa kung ano ang nasubukan namin sa ngayon sa LLaVA, tila magtatagal ng mas mahabang oras upang makahabol sa OpenAI sa espasyong visual na wika. Siyempre, sa mas maraming pag-unlad, pag-unlad, at pagbabago, ang mga bagay ay magiging mas mahusay. Ngunit sa ngayon, sabik kaming naghihintay na subukan ang multimodal na kakayahan ng GPT-4.
Mag-iwan ng komento
May ilang kaduda-dudang mga pagpipilian sa disenyo sa Redfall, isang mishmash ng half-baked na sikat na Arkane formula. Gustung-gusto ko ang mga laro na ginawa ng Arkane Studios, na ang Dishonored ay naging isang pamagat na muli kong binibisita paminsan-minsan para sa kakaibang lumilitaw na gameplay nito. At […]
Narito na ang monitor ng BenQ PD2706UA, at kasama nito ang lahat ng mga kampanilya at sipol na pinahahalagahan ng mga gumagamit ng pagiging produktibo. 4K na resolution, mga factory-calibrated na kulay, isang 27-inch na panel, isang ergonomic stand na madaling i-adjust, at higit pa. Mayroon itong maraming […]
Ang Minecraft Legends ay isang laro na pumukaw sa aking interes sa orihinal nitong pagpapakita noong nakaraang taon. Ngunit, aaminin ko na hindi ako aktibong nasubaybayan nang maayos ang laro hanggang sa mas malapit kami sa opisyal na paglabas nito. Pagkatapos ng lahat, mahal ko […]
