Este guia foi gentilmente apoiado por nossos amigos em LogRocket , um serviço de monitoramento de desempenho frontend , repetição da sessão e análise do produto para ajudá-lo a construir melhores experiências para o cliente. LogRocket rastreia as principais métricas, incl. DOM completo, tempo para o primeiro byte, primeiro atraso de entrada, CPU do cliente e uso de memória. Obtenha um teste gratuito do LogRocket/ hoje.
>
O desempenho na web é uma fera complicada, não é? Como sabemos realmente onde estamos em termos de desempenho e quais são exatamente nossos gargalos de desempenho? É JavaScript caro, entrega lenta de fontes da web, imagens pesadas ou renderização lenta? Otimizamos o suficiente com trepidação de árvore, levantamento de escopo, divisão de código e todos os padrões de carregamento sofisticados com observador de interseção, hidratação progressiva, dicas de clientes, HTTP/3, trabalhadores de serviço e-meu Deus-trabalhadores de borda? E, o mais importante, onde começamos a melhorar o desempenho e como estabelecemos uma cultura de desempenho de longo prazo?
Antigamente, o desempenho costumava ser um mero pensamento tardio . Muitas vezes adiado até o final do projeto, ele se resumia a minificação, concatenação, otimização de ativos e, potencialmente, alguns ajustes finos no arquivo config do servidor. Olhando para trás agora, as coisas parecem ter mudado significativamente.
O desempenho não é apenas uma preocupação técnica: ele afeta tudo, desde a acessibilidade à usabilidade até a otimização do mecanismo de pesquisa e, ao incorporá-lo ao fluxo de trabalho, as decisões de design devem ser informadas por suas implicações de desempenho. O desempenho deve ser medido, monitorado e refinado continuamente , e a crescente complexidade da web apresenta novos desafios que tornam difícil acompanhar as métricas, porque os dados variam significativamente dependendo do dispositivo, navegador, protocolo, tipo de rede e latência (CDNs, ISPs, caches, proxies, firewalls, balanceadores de carga e servidores, todos desempenham um papel no desempenho).
Então, se criássemos uma visão geral de todas as coisas que devemos ter em mente ao melhorar o desempenho-desde o início do projeto até o lançamento final do site-como seria? Abaixo, você encontrará uma (esperançosamente imparcial e objetiva) lista de verificação de desempenho de front-end para 2021 -uma visão geral atualizada dos problemas que você pode precisar considerar para garantir que seus tempos de resposta sejam rápidos e a interação do usuário seja sem problemas e seus sites não drenam a largura de banda do usuário.
Índice
- Preparação: planejamento e métricas
Cultura de desempenho, Core Web Vitals, perfis de desempenho, CrUX, Lighthouse, FID, TTI, CLS, dispositivos. - Definindo metas realistas
Orçamentos de desempenho, metas de desempenho, estrutura RAIL, orçamentos de 170KB/30KB. - Definindo o ambiente
Escolha de uma estrutura, custo de desempenho de linha de base, Webpack, dependências, CDN, arquitetura front-end, CSR, SSR, CSR + SSR, renderização estática, pré-renderização, padrão PRPL. - Otimizações de ativos
Brotli, AVIF, WebP, imagens responsivas, AV1, alojamento de mídia adaptável, compressão de vídeo, fontes da web, fontes do Google. - Construir otimizações
Módulos JavaScript, padrão de módulo/nomodule, trepidação de árvore, divisão de código, levantamento de escopo, Webpack, serviço diferencial, web trabalhador, WebAssembly, pacotes JavaScript, React, SPA, hidratação parcial, importação na interação, terceiros, cache. - Otimizações de entrega
Carregamento lento, observador de intersecção, renderização e decodificação adiada, CSS crítico, streaming, dicas de recursos, mudanças de layout, service worker. - Rede, HTTP/2, HTTP/3
Agrafamento OCSP, certificados EV/DV, empacotamento, IPv6, QUIC, HTTP/3. - Teste e monitoramento
Fluxo de trabalho de auditoria, navegadores proxy, página 404, prompts de consentimento de cookie GDPR, diagnóstico de desempenho CSS, acessibilidade. - Vitórias rápidas
- Baixe a lista de verificação (PDF, Apple Pages, MS Word)
- Vamos lá!
(Você também pode apenas baixar o PDF da lista de verificação (166 KB) ou baixe o arquivo editável Apple Pages (275 KB) ou o arquivo.docx (151 KB). Otimização feliz , todos!)
Preparação: planejamento e métricas
Microotimizações são ótimas para manter o desempenho sob controle, mas é fundamental ter metas claramente definidas em mente-metas mensuráveis que influenciam as decisões tomadas ao longo do processo. Existem alguns modelos diferentes, e os discutidos abaixo são bastante opinativos-certifique-se de definir suas próprias prioridades desde o início.
- Estabeleça uma cultura de desempenho.
Em muitas organizações, os desenvolvedores de front-end sabem exatamente quais são os problemas subjacentes comuns e quais estratégias devem ser usadas para corrigi-los. No entanto, enquanto não houver um endosso estabelecido da cultura de desempenho, cada decisão se transformará em um campo de batalha de departamentos, dividindo a organização em silos. Você precisa da adesão das partes interessadas do negócio e, para consegui-lo, precisa estabelecer um estudo de caso ou uma prova de conceito sobre como a velocidade-especialmente Core Web Vitals , que abordaremos em detalhes mais tarde-beneficia métricas e indicadores-chave de desempenho ( KPIs ) com os quais se preocupam.Por exemplo, para tornar o desempenho mais tangível, você pode expor o impacto no desempenho da receita mostrando o correlação entre a taxa de conversão e o tempo de carregamento do aplicativo, bem como o desempenho de renderização. Ou a taxa de rastreamento do bot de pesquisa (PDF, páginas 27–50).
Sem um forte alinhamento entre as equipes de desenvolvimento/design e negócios/marketing, o desempenho não será sustentável a longo prazo. Estude reclamações comuns que chegam ao atendimento ao cliente e à equipe de vendas, estude análises para altas taxas de rejeição e quedas de conversão. Explore como melhorar o desempenho pode ajudar a aliviar alguns desses problemas comuns. Ajuste o argumento de acordo com o grupo de interessados com quem você está falando.
Faça experiências de desempenho e avalie os resultados-tanto no celular quanto no computador (por exemplo, com Google Analytics ). Isso o ajudará a construir um estudo de caso sob medida para a empresa com dados reais. Além disso, o uso de dados de estudos de caso e experimentos publicados em WPO Stats ajudará a aumentar a sensibilidade para as empresas sobre por que o desempenho é importante e qual o impacto que ele tem no usuário experiência e métricas de negócios. Afirmar que o desempenho é importante por si só não é suficiente-você também precisa estabelecer algumas metas mensuráveis e rastreáveis e observá-las ao longo do tempo.
Como chegar? Em sua palestra sobre Building Performance for the Long Term , Allison McKnight compartilha um estudo de caso abrangente de como ajudou a estabelecer uma cultura de desempenho na Etsy ( slides ). Mais recentemente, Tammy Everts falou sobre hábitos de equipes de desempenho altamente eficazes em organizações pequenas e grandes.
Ao ter essas conversas nas organizações, é importante ter em mente que, assim como a UX é um espectro de experiências, o desempenho da web é uma distribuição . Como Karolina Szczur observou ,”esperar que um único número seja capaz de fornecer uma classificação a se aspirar é um suposição errada.”Portanto, as metas de desempenho precisam ser granulares, rastreáveis e tangíveis.
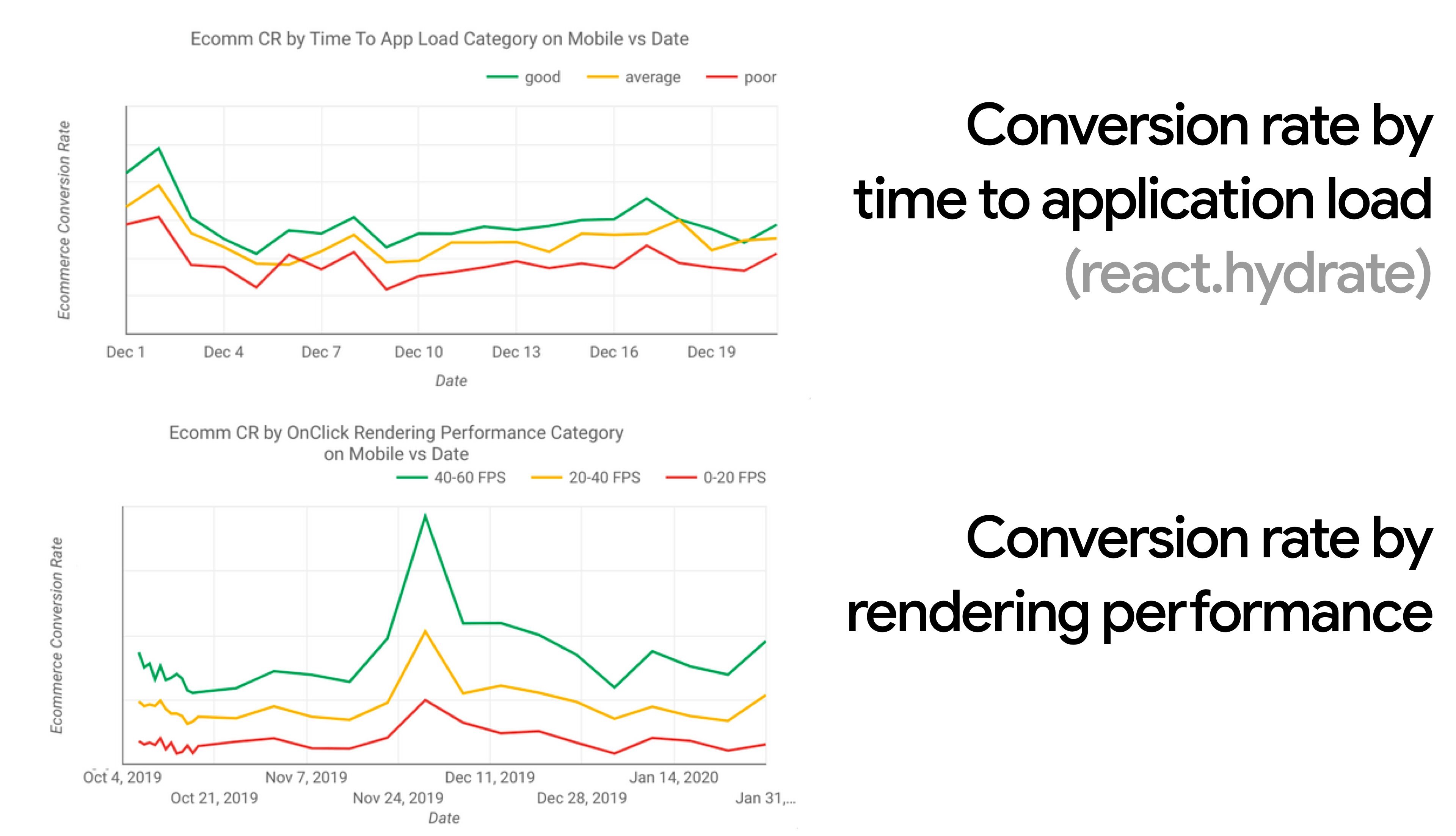
- Objetivo: ser pelo menos 20% mais rápido que seu concorrente mais rápido.
De acordo com pesquisa psicológica , se você deseja que os usuários sintam que seu site é mais rápido do que o seu site do concorrente, você precisa ser pelo menos 20% mais rápido. Estude seus principais concorrentes, colete métricas sobre o desempenho deles em dispositivos móveis e desktops e defina limites que o ajudem a ultrapassá-los. No entanto, para obter resultados e metas precisos, certifique-se primeiro de obter uma imagem completa da experiência de seus usuários, estudando suas análises. Você pode então imitar a experiência do 90º percentil para teste.Para ter uma boa primeira impressão do desempenho de seus concorrentes, você pode usar o Relatório UX do Chrome ( CrUX , um conjunto de dados RUM pronto, vídeo de introdução por Ilya Grigorik e guia detalhado de Rick Viscomi), ou Treo , uma ferramenta de monitoramento de RUM com tecnologia do Chrome UX Report. Os dados são coletados dos usuários do navegador Chrome, portanto, os relatórios serão específicos do Chrome, mas eles fornecerão uma distribuição bastante completa do desempenho, mais importante, pontuações do Core Web Vitals, para uma ampla gama de visitantes. Observe que novos conjuntos de dados CrUX são lançados na segunda terça-feira de cada mês .
Como alternativa, você também pode usar:
- Ferramenta de comparação de relatórios do Chrome UX de Addy Osmani ,
- Speed Scorecard (também fornece um estimador de impacto na receita),
- Comparação de teste de experiência real do usuário ou
- SiteSpeed CI (com base em teste sintético ).
Observação : se você usar Page Speed Insights ou Page Speed Insights API (não, não está obsoleto!), você pode obter Dados de desempenho CrUX para páginas específicas em vez de apenas os agregados. Esses dados podem ser muito mais úteis para definir metas de desempenho para ativos como “página de destino” ou “lista de produtos”. E se você estiver usando CI para testar os orçamentos, você precisa ter certeza de que seu ambiente testado corresponde a CrUX se você usou CrUX para definir a meta ( obrigado Patrick Meenan! ).
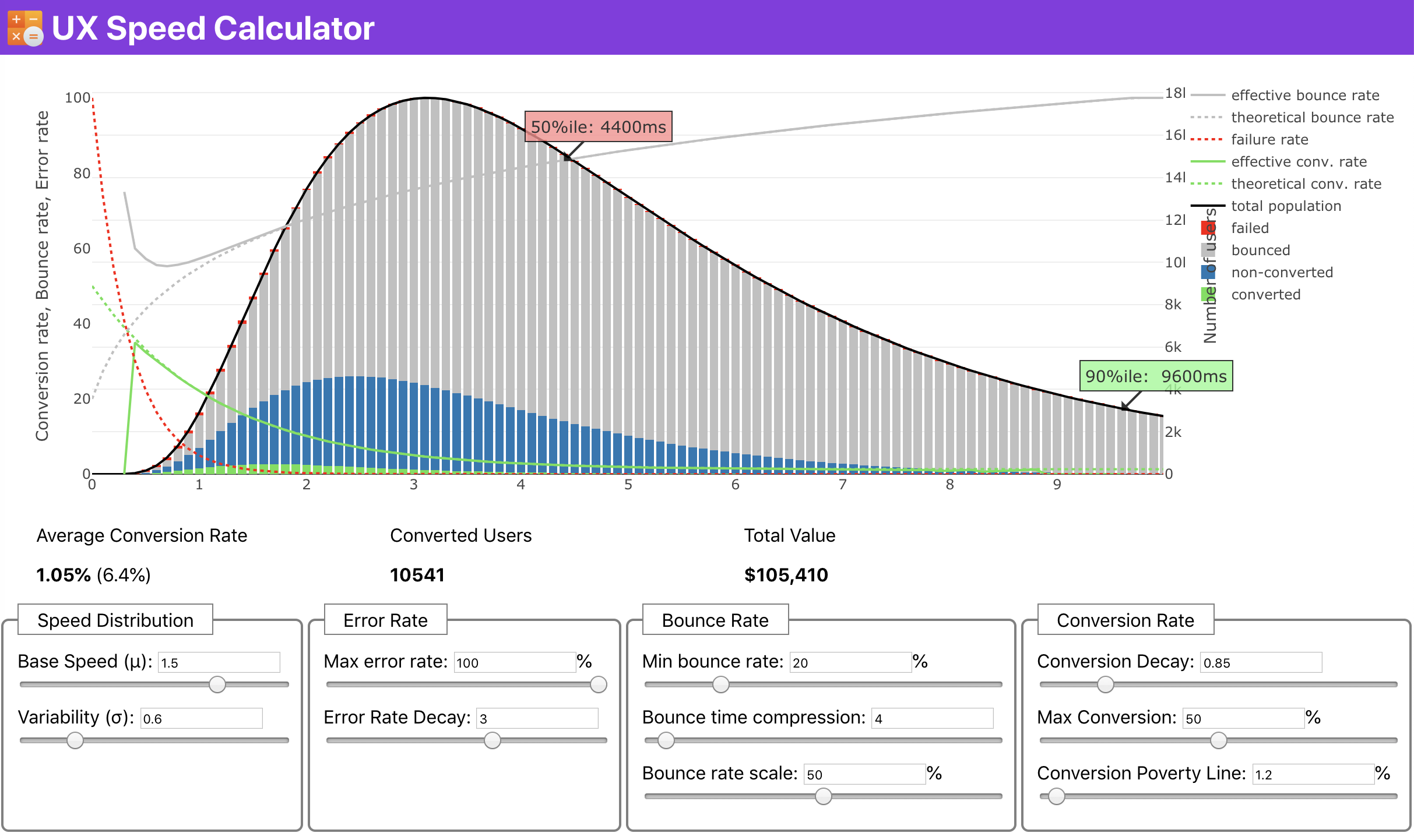
Se precisar de ajuda para mostrar o motivo por trás da priorização da velocidade, ou se quiser visualizar a diminuição da taxa de conversão ou aumento na taxa de rejeição com desempenho mais lento, ou talvez seja necessário defender uma solução de RUM em seu organização, Sergey Chernyshev criou uma UX Speed Calculator , uma ferramenta de código aberto que ajuda você a simular dados e visualizá-los para direcionar seu ponto de vista.
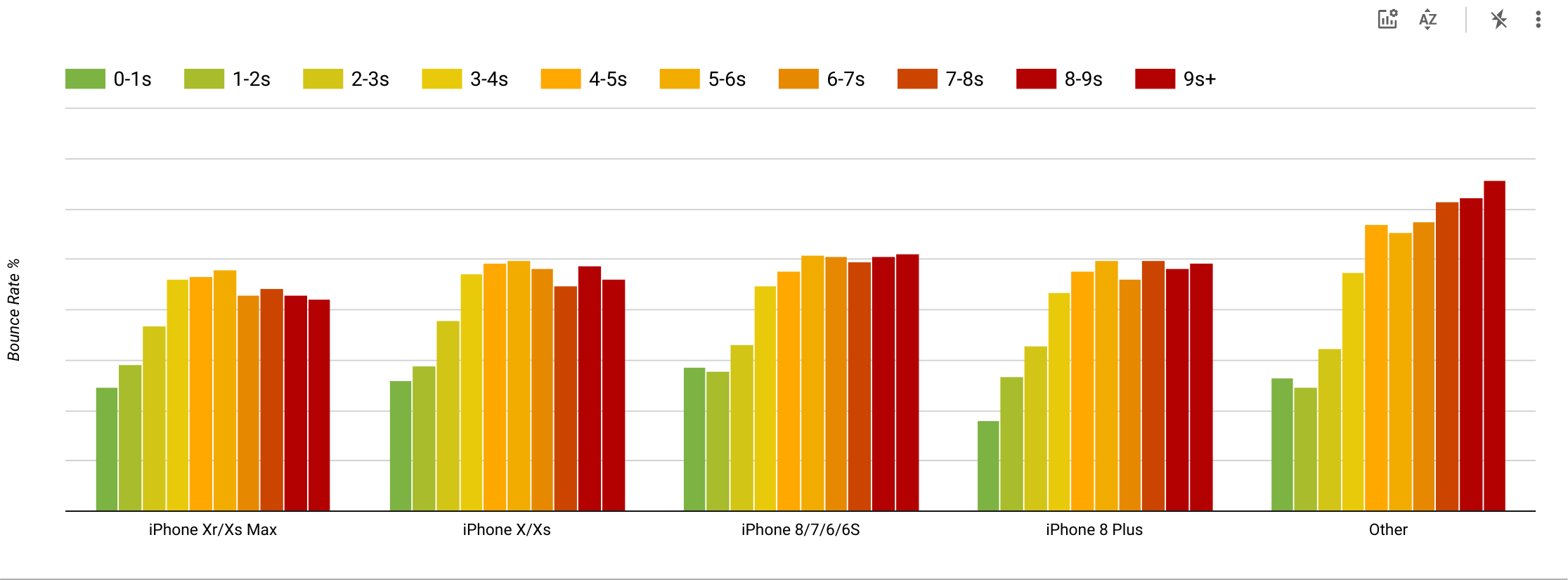
Às vezes, você pode querer ir um pouco mais fundo, combinando os dados vindos do CrUX com quaisquer outros dados que você já tenha para descobrir rapidamente onde estão os atrasos, pontos cegos e ineficiências-para seus concorrentes ou para seu projeto. Em seu trabalho, Harry Roberts tem usado uma Planilha de topografia de velocidade do site que usa para decompor desempenho por tipos de página-chave e rastreie como as métricas-chave são diferentes entre elas. Você pode baixar a planilha como Planilhas Google, Excel, documento OpenOffice ou CSV.
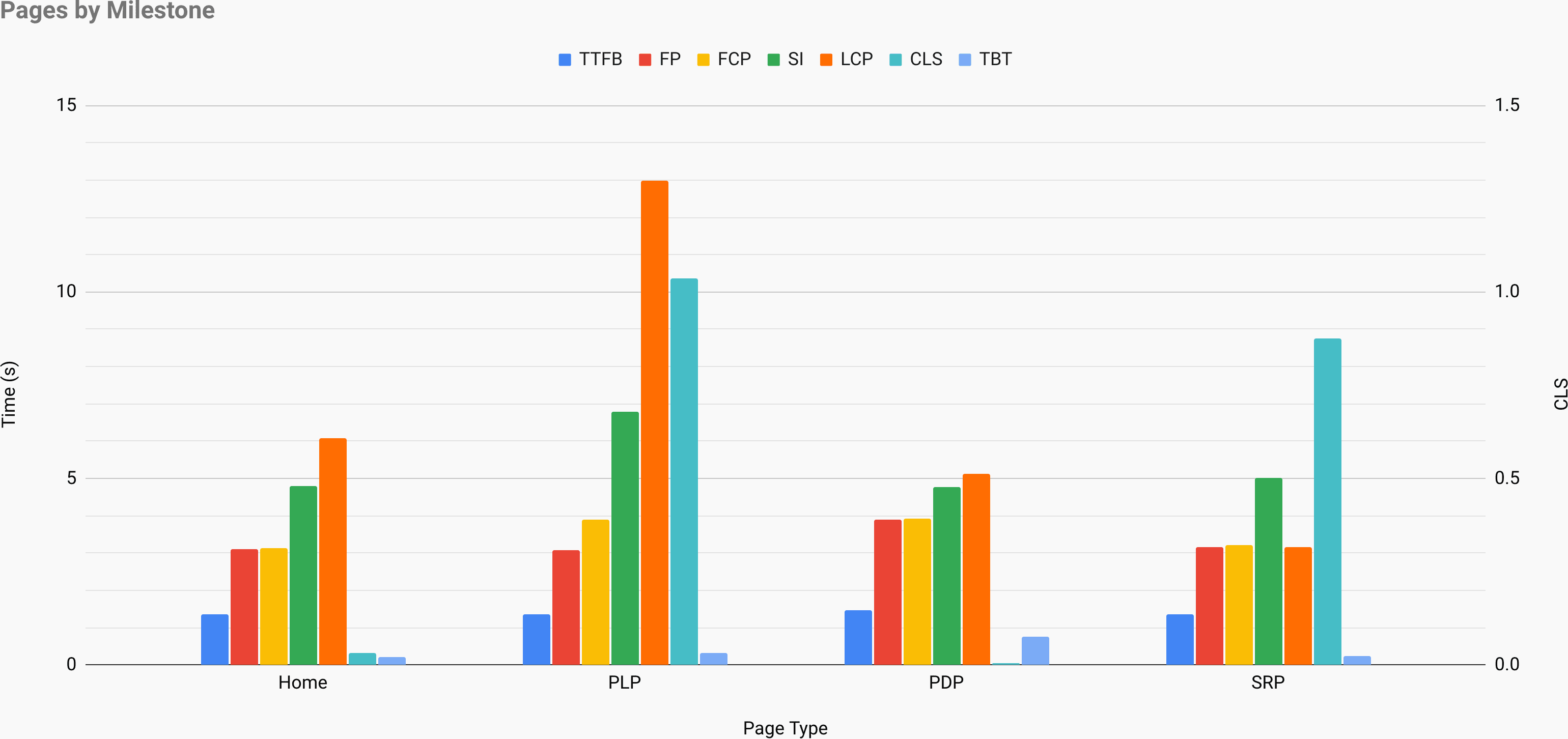
E se quiser ir todo o caminho, você pode execute uma auditoria de desempenho do Lighthouse em cada página de um site (via Lightouse Parade ), com uma saída salva como CSV. Isso o ajudará a identificar quais páginas específicas (ou tipos de páginas) de seus concorrentes têm pior ou melhor desempenho e em que você pode querer concentrar seus esforços. (Para o seu próprio site, provavelmente é melhor enviar dados para um endpoint de análise !).

Colete dados, configure uma planilha , reduza 20% e configure suas metas ( orçamentos de desempenho ) dessa forma. Agora você tem algo mensurável para testar. Se você está mantendo o orçamento em mente e tentando enviar apenas a carga útil mínima para obter um tempo rápido de interação, você está em um caminho razoável.
Precisa de recursos para começar?
- Addy Osmani escreveu um artigo muito detalhado sobre como iniciar o orçamento de desempenho , como para quantificar o impacto dos novos recursos e por onde começar quando você ultrapassar o orçamento.
- guia de Lara Hogan sobre como abordar projetos com um orçamento de desempenho pode fornecer dicas úteis para designers.
- Harry Roberts publicou um guia sobre como configurar uma planilha do Google para exibição o impacto de scripts de terceiros no desempenho, usando Request Map ,
- Calculadora de orçamento de desempenho de Jonathan Fielding, Katie Hempenius’ perf-budget-calculator e Browser Calories podem ajudar na criação de orçamentos (graças a Karolina Szczur para avisar).
- Em muitas empresas, os orçamentos de desempenho não devem ser aspiracionais, mas sim pragmáticos, servindo como um sinal de espera para evitar escorregar além de um certo ponto. Nesse caso, você poderia escolher seu pior ponto de dados nas últimas duas semanas como um limite e partir daí. Orçamentos de desempenho, pragmaticamente mostra uma estratégia para conseguir isso.
- Além disso, torne o orçamento de desempenho e o desempenho atual visíveis configurando painéis com tamanhos de compilação de relatórios de gráficos. Existem muitas ferramentas que permitem que você faça isso: SiteSpeed.io painel (código aberto), SpeedCurve e Caliber são apenas alguns deles, e você pode encontrar mais ferramentas em perf.rocks .

Depois de ter um orçamento em vigor, incorpore-o ao seu processo de construção com Webpack Performance Dicas e tamanho do pacote , Lighthouse CI , PWMetrics ou Sitespeed CI para aplicar orçamentos em solicitações pull e fornecer um histórico de pontuação em comentários de RP.
Para expor os orçamentos de desempenho a toda a equipe, integre os orçamentos de desempenho no Lighthouse via Lightwallet ou use o LHCI Action para uma rápida integração do Github Actions . E se precisar de algo personalizado, você pode usar webpagetest-charts-api , uma API de endpoints para construir gráficos de Resultados do WebPagetest.
No entanto, a conscientização sobre o desempenho não deve vir apenas dos orçamentos de desempenho. Assim como o Pinterest , você pode criar um regra eslint personalizada que não permite a importação de arquivos e diretórios que são conhecidos como dependência-pesado e iria inchar o pacote. Configure uma lista de pacotes “seguros” que podem ser compartilhados por toda a equipe.
Além disso, pense nas tarefas críticas do cliente que são mais benéficas para o seu negócio. Estude, discuta e defina limites de tempo aceitáveis para ações críticas e estabeleça”UX pronto” marcas de tempo do usuário que toda a organização aprovou. Em muitos casos, as jornadas do usuário afetarão o trabalho de muitos departamentos diferentes, portanto, o alinhamento em termos de tempos aceitáveis ajudará a apoiar ou evitar discussões de desempenho no futuro. Certifique-se de que os custos adicionais de recursos e recursos adicionados sejam visíveis e compreendidos.
Alinhe os esforços de desempenho com outras iniciativas de tecnologia, que vão desde novos recursos do produto sendo construído até a refatoração e o alcance de novos públicos globais. Portanto, sempre que ocorre uma conversa sobre desenvolvimento posterior, o desempenho também faz parte dessa conversa. É muito mais fácil atingir as metas de desempenho quando a base de código é nova ou está apenas sendo refatorada.
Além disso, como Patrick Meenan sugeriu, vale a pena planejar uma sequência de carregamento e compensações durante o processo de design. Se você priorizar antecipadamente quais peças são mais críticas e definir a ordem em que devem aparecer, também saberá o que pode ser atrasado. O ideal é que essa ordem também reflita a sequência de suas importações CSS e JavaScript, de modo que será mais fácil manuseá-las durante o processo de construção. Além disso, considere qual deve ser a experiência visual nos estados”intermediários”, enquanto a página está sendo carregada (por exemplo, quando as fontes da web ainda não foram carregadas).
Depois de estabelecer uma forte cultura de desempenho em sua organização, tente ser 20% mais rápido do que antes para manter as prioridades intactas com o passar do tempo ( obrigado, Guy Podjarny ! ). Mas considere os diferentes tipos e comportamentos de uso de seus clientes (que Tobias Baldauf chamou de cadência e coortes ), junto com o tráfego de bot e efeitos de sazonalidade.
Planejando, planejando, planejando. Pode ser tentador entrar em algumas otimizações”fáceis de usar”logo no início-e pode ser uma boa estratégia para ganhos rápidos-mas é será muito difícil manter o desempenho como uma prioridade sem planejar e definir metas de desempenho realistas e personalizadas para a empresa.
- Escolha as métricas certas.
Nem todas as métricas são igualmente importantes . Estude quais métricas são mais importantes para seu aplicativo: geralmente, elas serão definidas por quão rápido você pode começar a renderizar os pixels mais importantes de sua interface e quão rapidamente você pode fornecer capacidade de resposta de entrada para esses pixels renderizados. Esse conhecimento lhe dará o melhor alvo de otimização para esforços contínuos. No final, não são os eventos de carregamento ou os tempos de resposta do servidor que definem a experiência, mas a percepção de como a interface parece .O que isso significa? Em vez de focar no tempo de carregamento da página inteira (por meio dos tempos onLoad e DOMContentLoaded , por exemplo), priorize o carregamento da página conforme percebido por seus clientes . Isso significa focar em um conjunto ligeiramente diferente de métricas. Na verdade, escolher a métrica certa é um processo sem vencedores óbvios.
Com base na pesquisa de Tim Kadlec e nas anotações de Marcos Iglesias em sua palestra , as métricas tradicionais podem ser agrupadas em alguns conjuntos. Normalmente, precisaremos de todos eles para ter uma visão completa do desempenho e, no seu caso particular, alguns deles serão mais importantes do que outros.
- Métricas baseadas em quantidade medem o número de solicitações, peso e uma pontuação de desempenho. Bom para disparar alarmes e monitorar mudanças ao longo do tempo, mas não tão bom para entender a experiência do usuário.
- Métricas de Milestone usam estados durante o ciclo de vida do processo de carregamento, por exemplo, Tempo até o primeiro byte e Tempo até interativo . Bom para descrever a experiência do usuário e monitoramento, não tão bom para saber o que acontece entre os marcos.
- Métricas de renderização fornecem uma estimativa de quão rápido o conteúdo é renderizado (por exemplo, tempo de Iniciar renderização , Índice de velocidade ). Bom para medir e ajustar o desempenho de renderização, mas não tão bom para medir quando o conteúdo importante aparece e pode ser interagido.
- Métricas personalizadas medem um determinado evento personalizado para o usuário, por exemplo, Hora do primeiro tweet do Twitter e PinnerWaitTime . Bom para descrever a experiência do usuário com precisão, não tão bom para dimensionar as métricas e comparar com os concorrentes.
Para completar o quadro, geralmente procuramos métricas úteis entre todos esses grupos. Normalmente, os mais específicos e relevantes são:
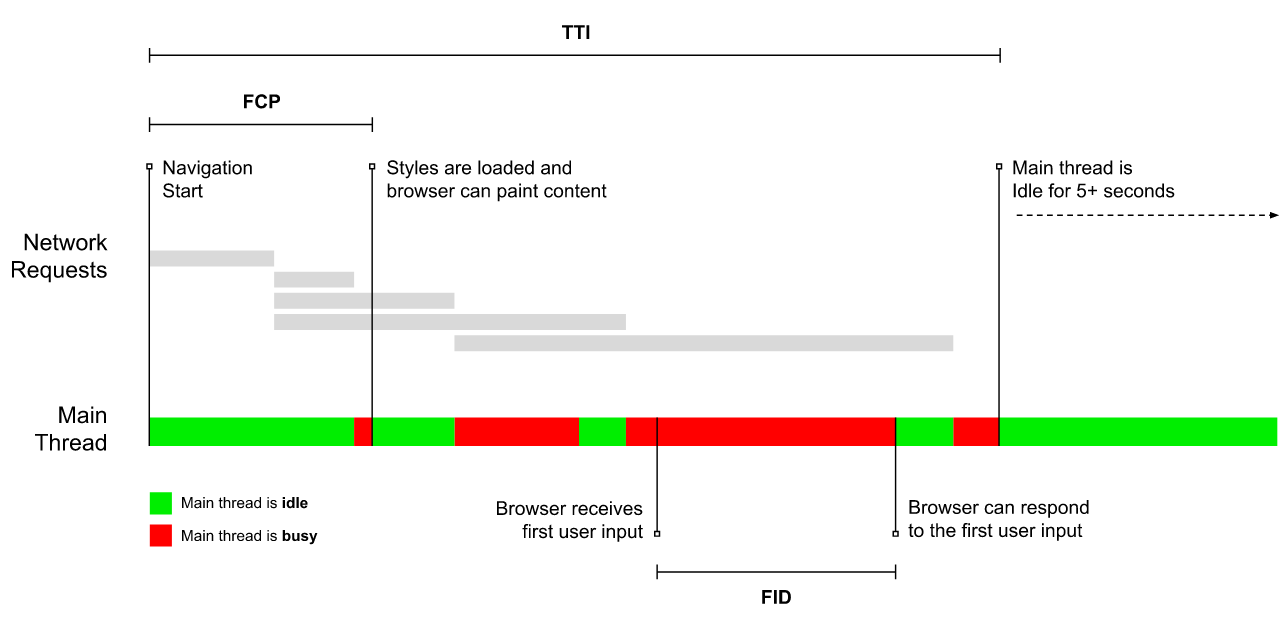
- Tempo para interação (TTI)
O ponto em cujo layout foi estabilizado , as principais fontes da web estão visíveis e a linha de execução principal está disponível o suficiente para lidar com a entrada do usuário-basicamente a marca de tempo quando um usuário pode interagir com a IU. As principais métricas para entender quanto espera um usuário tem de experimentar para usar o site sem atrasos. Boris Schapira escreveu uma postagem detalhada sobre como medir TTI de maneira confiável . - Primeiro atraso de entrada (FID) ou Capacidade de resposta de entrada
O momento desde quando um usuário interage pela primeira vez com seu site até o momento em que o navegador é realmente capaz de responder a essa interação. Complementa muito bem o TTI, pois descreve a parte que faltava na imagem: o que acontece quando um usuário realmente interage com o site. Pretende ser apenas uma métrica RUM. Existe uma biblioteca JavaScript para medir o FID no navegador. - Maior pintura com conteúdo (LCP)
Marca o ponto na linha do tempo de carregamento da página quando o conteúdo importante da página provavelmente foi carregado. A suposição é que o elemento mais importante da página é o maior um visível na janela de visualização do usuário . Se os elementos forem renderizados acima e abaixo da dobra, apenas a parte visível será considerada relevante. - Tempo total de bloqueio ( TBT )
Uma métrica que ajuda a quantificar o gravidade da não interatividade de uma página antes de se tornar interativa de forma confiável (ou seja, o thread principal está livre de qualquer tarefa em execução acima de 50 ms ( tarefas longas ) por pelo menos 5s). A métrica mede a quantidade total de tempo entre a primeira pintura e o tempo de interação (TTI) em que o encadeamento principal foi bloqueado por tempo suficiente para evitar a resposta de entrada. Não é de se admirar, então, que um baixo TBT seja um bom indicador de bom desempenho. (obrigado, Artem, Phil) - Mudança cumulativa de layout ( CLS )
A métrica destaca a frequência com que os usuários experimentam algo inesperadomudanças de layout ( refluxos ) ao acessar o site. Ele examina os elementos instáveis e seu impacto na experiência geral. Quanto menor a pontuação, melhor. - Índice de velocidade
Mede a rapidez o conteúdo da página é preenchido visualmente; quanto menor a pontuação, melhor. A pontuação do Índice de velocidade é calculada com base na velocidade do progresso visual , mas é apenas um valor calculado. Também é sensível ao tamanho da janela de visualização, então você precisa definir uma série de configurações de teste que correspondem ao seu público-alvo. Observe que está se tornando menos importante com o LCP se tornando uma métrica mais relevante ( obrigado, Boris , Artem! ). - Tempo gasto da CPU
Uma métrica que mostra com que frequência e por quanto tempo o thread principal está bloqueado, trabalhando na pintura, renderização, script e carregamento. O alto tempo de CPU é um indicador claro de uma experiência instável , ou seja, quando o usuário experimenta um lapso perceptível entre sua ação e uma resposta. Com o WebPageTest, você pode selecionar”Capture Dev Tools Timeline”na guia”Chrome” para expor a divisão do thread principal conforme ele é executado em qualquer dispositivo usando WebPageTest. - Custos de CPU em nível de componente
Assim como com o Tempo gasto da CPU , esta métrica, proposta por Stoyan Stefanov, explora o impacto do JavaScript na CPU . A ideia é usar a contagem de instruções da CPU por componente para entender seu impacto na experiência geral, isoladamente. Pode ser implementado usando Puppeteer e Chrome . - FrustrationIndex
Enquanto muitas métricas apresentadas acima explicam quando um evento específico acontece, FrustrationIndex de Tim Vereecke analisa o lacunas entre as métricas em vez de examiná-las individualmente. Ele analisa os principais marcos percebidos pelo usuário final, como Título é visível, Primeiro conteúdo é visível, Visualmente pronto e Página parece pronta e calcula uma pontuação indicando o nível de frustração ao carregar uma página. Quanto maior a lacuna, maior a chance de o usuário ficar frustrado. Potencialmente, um bom KPI para a experiência do usuário. Tim publicou uma postagem detalhada sobre FrustrationIndex e como funciona. - Impacto do peso do anúncio
Se o seu site depende da receita gerada pela publicidade, é útil para rastrear o peso do código relacionado ao anúncio. Paddy Ganti’s script constructs two URLs (one normal and one blocking the ads), prompts the generation of a video comparison via WebPageTest and reports a delta. - Deviation metrics
As noted by Wikipedia engineers, data of how much variance exists in your results could inform you how reliable your instruments are, and how much attention you should pay to deviations and outlers. Large variance is an indicator of adjustments needed in the setup. It also helps understand if certain pages are more difficult to measure reliably, e.g. due to third-party scripts causing significant variation. It might also be a good idea to track browser version to understand bumps in performance when a new browser version is rolled out. - Custom metrics
Custom metrics are defined by your business needs and customer experience. It requires you to identify important pixels, critical scripts, necessary CSS and relevant assets and measure how quickly they get delivered to the user. For that one, you can monitor Hero Rendering Times, or use Performance API, marking particular timestamps for events that are important for your business. Also, you can collect custom metrics with WebPagetest by executing arbitrary JavaScript at the end of a test.
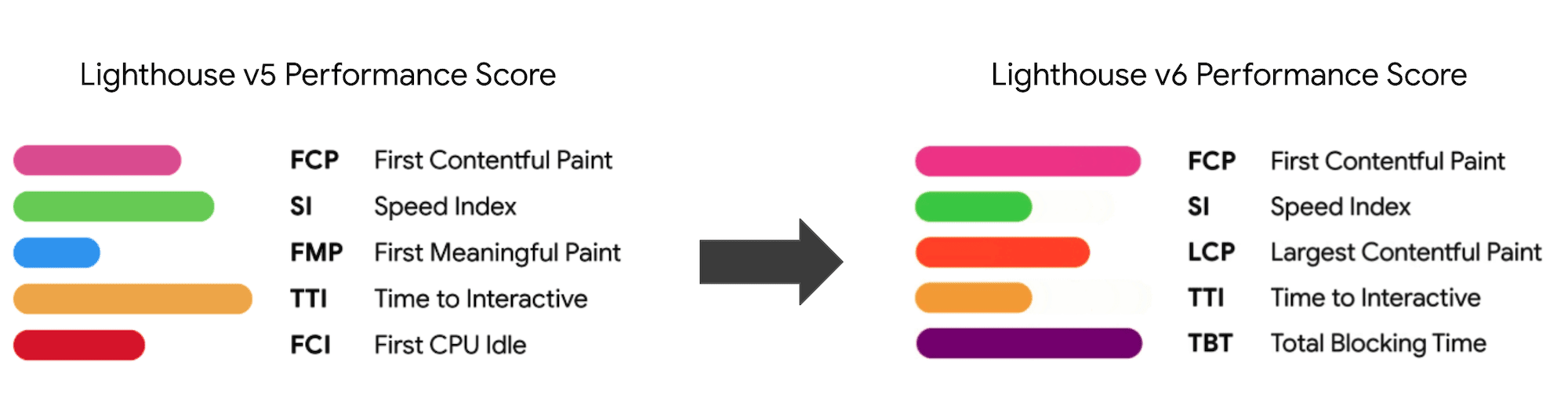
Note that the First Meaningful Paint (FMP) doesn’t appear in the overview above. It used to provide an insight into how quickly the server outputs any data. Long FMP usually indicated JavaScript blocking the main thread, but could be related to back-end/server issues as well. However, the metric has been deprecated recently as it appears not to be accurate in about 20% of the cases. It was effectively replaced with LCP which is both more reliable and easier to reason about. It is no longer supported in Lighthouse. Double check latest user-centric performance metrics and recommendations just to make sure you are on the safe page (thanks, Patrick Meenan).
Steve Souders has a detailed explanation of many of these metrics. It’s important to notice that while Time-To-Interactive is measured by running automated audits in the so-called lab environment, First Input Delay represents the actual user experience, with actual users experiencing a noticeable lag. In general, it’s probably a good idea to always measure and track both of them.
Depending on the context of your application, preferred metrics might differ: e.g. for Netflix TV UI, key input responsiveness, memory usage and TTI are more critical, and for Wikipedia, first/last visual changes and CPU time spent metrics are more important.
Note: both FID and TTI do not account for scrolling behavior; scrolling can happen independently since it’s off-main-thread, so for many content consumption sites these metrics might be much less important (thanks, Patrick!).
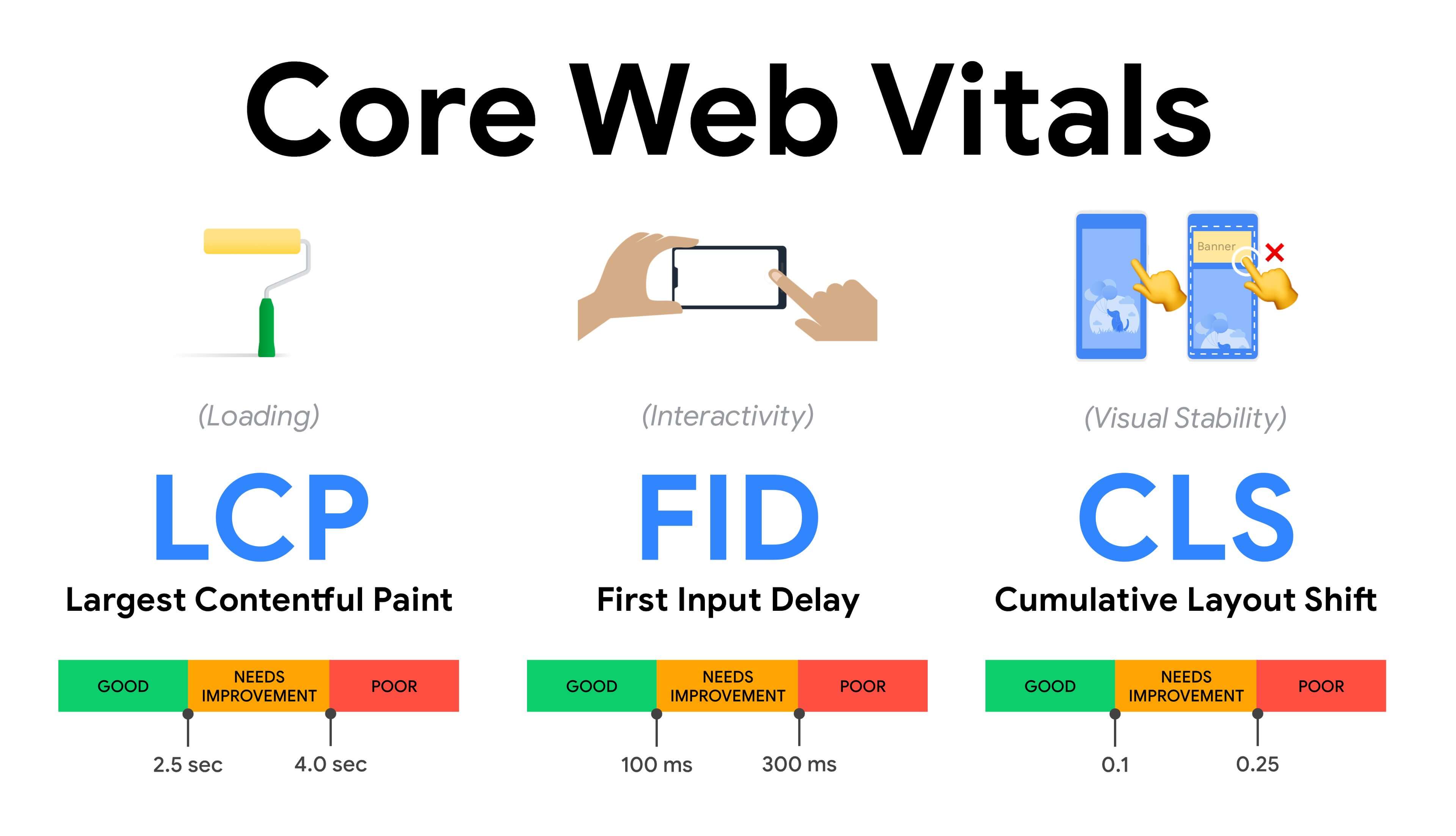
- Measure and optimize the Core Web Vitals.
For a long time, performance metrics were quite technical, focusing on the engineering view of how fast servers are at responding, and how quick browsers are at loading. The metrics have changed over the years — attempting to find a way to capture the actual user experience, rather than server timings. In May 2020, Google has announced Core Web Vitals, a set of new user-focused performance metrics, each representing a distinct facet of the user experience.For each of them, Google recommends a range of acceptable speed goals. At least 75% of all page views should exceed the Good range to pass this assessment. These metrics quickly gained traction, and with Core Web Vitals becoming ranking signals for Google Search in May 2021 (Page Experience ranking algorithm update), many companies have turned their attention to their performance scores.
Let’s break down each of the Core Web Vitals, one by one, along with useful techniques and tooling to optimize your experiences with these metrics in mind. (It’s worth noting that you will end up with better Core Web Vitals scores by following a general advice in this article.)
- Largest Contentful Paint (LCP) <2.5 sec.
Measures the loading of a page, and reports the render time of the largest image or text block that’s visible within the viewport. Hence, LCP is affected by everything that’s deferring the rendering of important information — be it slow server response times, blocking CSS, in-flight JavaScript (first-party or third-party), web font loading, expensive rendering or painting operations, lazy-loaded images, skeleton screens or client-side rendering.For a good experience, LCP should occur within 2.5s of when the page first starts loading. That means that we need to render the first visible portion of the page as early as possible. That will require tailored critical CSS for each template, orchestrating the
-order and prefetching critical assets (we’ll cover them later).The main reason for a low LCP score is usually images. To deliver an LCP in <2.5s on Fast 3G — hosted on a well-optimized server, all static without client-side rendering and with an image coming from a dedicated image CDN — means that the maximum theoretical image size is only around 144KB. That’s why responsive images matter, as well as preloading critical images early (with
preload).Quick tip: to discover what is considered LCP on a page, in DevTools you can hover over the LCP badge under”Timings”in the Performance Panel (thanks, Tim Kadlec!).
- First Input Delay (FID) <100ms.
Measures the responsiveness of the UI, i.e. how long the browser was busy with other tasks before it could react to a discrete user input event like a tap, or a click. It’s designed to capture delays that result from the main thread being busy, especially during page load.The goal is to stay within 50–100ms for every interaction. To get there, we need to identify long tasks (blocks the main thread for >50ms) and break them up, code-split a bundle into multiple chunks, reduce JavaScript execution time, optimize data-fetching, defer script execution of third-parties, move JavaScript to the background thread with Web workers and use progressive hydration to reduce rehydration costs in SPAs.
Quick tip: in general, a reliable strategy to get a better FID score is to minimize the work on the main thread by breaking larger bundles into smaller ones and serving what the user needs when they need it, so user interactions won’t be delayed. We’ll cover more on that in detail below.
- Cumulative Layout Shift (CLS) <0.1.
Measures visual stability of the UI to ensure smooth and natural interactions, i.e. the sum total of all individual layout shift scores for every unexpected layout shift that occurs during the lifespan of the page. An individual layout shift occurs any time an element which was already visible changes its position on the page. It’s scored based on the size of the content and distance it moved.So every time a shift appears — e.g. when fallback fonts and web fonts have different font metrics, or adverts, embeds or iframes coming in late, or image/video dimensions aren’t reserved, or late CSS forces repaints, or changes are injected by late JavaScript — it has an impact on the CLS score. The recommended value for a good experience is a CLS <0.1.
It’s worth noting that Core Web Vitals are supposed to evolve over time, with a predictable annual cycle. For the first year update, we might be expecting First Contentful Paint to be promoted to Core Web Vitals, a reduced FID threshold and better support for single-page applications. We might also see the responding to user inputs after load gaining more weight, along with security, privacy and accessibility (!) considerations.
Related to Core Web Vitals, there are plenty of useful resources and articles that are worth looking into:
- Web Vitals Leaderboard allows you to compare your scores against competition on mobile, tablet, desktop, and on 3G and 4G.
- Core SERP Vitals, a Chrome extension that shows the Core Web Vitals from CrUX in the Google Search Results.
- Layout Shift GIF Generator that visualizes CLS with a simple GIF (also available from the command line).
- web-vitals library can collect and send Core Web Vitals to Google Analytics, Google Tag Manager or any other analytics endpoint.
- Analyzing Web Vitals with WebPageTest, in which Patrick Meenan explores how WebPageTest exposes data about Core Web Vitals.
- Optimizing with Core Web Vitals, a 50-min video with Addy Osmani, in which he highlights how to improve Core Web Vitals in an eCommerce case-study.
- Cumulative Layout Shift in Practice and Cumulative Layout Shift in the Real World are comprehensive articles by Nic Jansma, which cover pretty much everything about CLS and how it correlates with key metrics such as Bounce Rate, Session Time or Rage Clicks.
- What Forces Reflow, with an overview of properties or methods, when requested/called in JavaScript, that will trigger the browser to synchronously calculate the style and layout.
- CSS Triggers shows which CSS properties trigger Layout, Paint and Composite.
- Fixing Layout Instability is a walkthrough of using WebPageTest to identify and fix layout instability issues.
- Cumulative Layout Shift, The Layout Instability Metric, another very detailed guide by Boris Schapira on CLS, how it’s calcualted, how to measure and how to optimize for it.
- How To Improve Core Web Vitals, a detailed guide by Simon Hearne on each of the metrics (including other Web Vitals, such as FCP, TTI, TBT), when they occur and how they are measured.
So, are Core Web Vitals the ultimate metrics to follow? Não exatamente. They are indeed exposed in most RUM solutions and platforms already, including Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (in the filmstrip view already), Newrelic, Shopify, Next.js, all Google tools (PageSpeed Insights, Lighthouse + CI, Search Console etc.) and many others.
However, as Katie Sylor-Miller explains, some of the main problems with Core Web Vitals are the lack of cross-browser support, we don’t really measure the full lifecycle of a user’s experience, plus it’s difficult to correlate changes in FID and CLS with business outcomes.
As we should be expecting Core Web Vitals to evolve, it seems only reasonable to always combine Web Vitals with your custom-tailored metrics to get a better understanding of where you stand in terms of performance.
- Largest Contentful Paint (LCP) <2.5 sec.
- Gather data on a device representative of your audience.
To gather accurate data, we need to thoroughly choose devices to test on. In most companies, that means looking into analytics and creating user profiles based on most common device types. Yet often, analytics alone doesn’t provide a complete picture. A significant portion of the target audience might be abandoning the site (and not returning back) just because their experience is too slow, and their devices are unlikely to show up as the most popular devices in analytics for that reason. So, additionally conducting research on common devices in your target group might be a good idea.Globally in 2020, according to the IDC, 84.8% of all shipped mobile phones are Android devices. An average consumer upgrades their phone every 2 years, and in the US phone replacement cycle is 33 months. Average bestselling phones around the world will cost under $200.
A representative device, then, is an Android device that is at least 24 months old, costing $200 or less, running on slow 3G, 400ms RTT and 400kbps transfer, just to be slightly more pessimistic. This might be very different for your company, of course, but that’s a close enough approximation of a majority of customers out there. In fact, it might be a good idea to look into current Amazon Best Sellers for your target market. (Thanks to Tim Kadlec, Henri Helvetica and Alex Russell for the pointers!).
What test devices to choose then? The ones that fit well with the profile outlined above. It’s a good option to choose a slightly older Moto G4/G5 Plus, a mid-range Samsung device (Galaxy A50, S8), a good middle-of-the-road device like a Nexus 5X, Xiaomi Mi A3 or Xiaomi Redmi Note 7 and a slow device like Alcatel 1X or Cubot X19, perhaps in an open device lab. For testing on slower thermal-throttled devices, you could also get a Nexus 4, which costs just around $100.
Also, check the chipsets used in each device and do not over-represent one chipset: a few generations of Snapdragon and Apple as well as low-end Rockchip, Mediatek would be enough (thanks, Patrick!).
If you don’t have a device at hand, emulate mobile experience on desktop by testing on a throttled 3G network (e.g. 300ms RTT, 1.6 Mbps down, 0.8 Mbps up) with a throttled CPU (5× slowdown). Eventually switch over to regular 3G, slow 4G (e.g. 170ms RTT, 9 Mbps down, 9Mbps up), and Wi-Fi. To make the performance impact more visible, you could even introduce 2G Tuesdays or set up a throttled 3G/4G network in your office for faster testing.
Keep in mind that on a mobile device, we should be expecting a 4×–5× slowdown compared to desktop machines. Mobile devices have different GPUs, CPU, memory and different battery characteristics. That’s why it’s important to have a good profile of an average device and always test on such a device.
- Synthetic testing tools collect lab data in a reproducible environment with predefined device and network settings (e.g. Lighthouse, Calibre, WebPageTest) and
- Real User Monitoring (RUM) tools evaluate user interactions continuously and collect field data (e.g. SpeedCurve, New Relic — the tools provide synthetic testing, too).
- use Lighthouse CI to track Lighthouse scores over time (it’s quite impressive),
- run Lighthouse in GitHub Actions to get a Lighthouse report alongside every PR,
- run a Lighthouse performance audit on every page of a site (via Lightouse Parade), with an output saved as CSV,
- use Lighthouse Scores Calculator and Lighthouse metric weights if you need to dive into more detail.
- Lighthouse is available for Firefox as well, but under the hood it uses the PageSpeed Insights API and generates a report based on a headless Chrome 79 User-Agent.
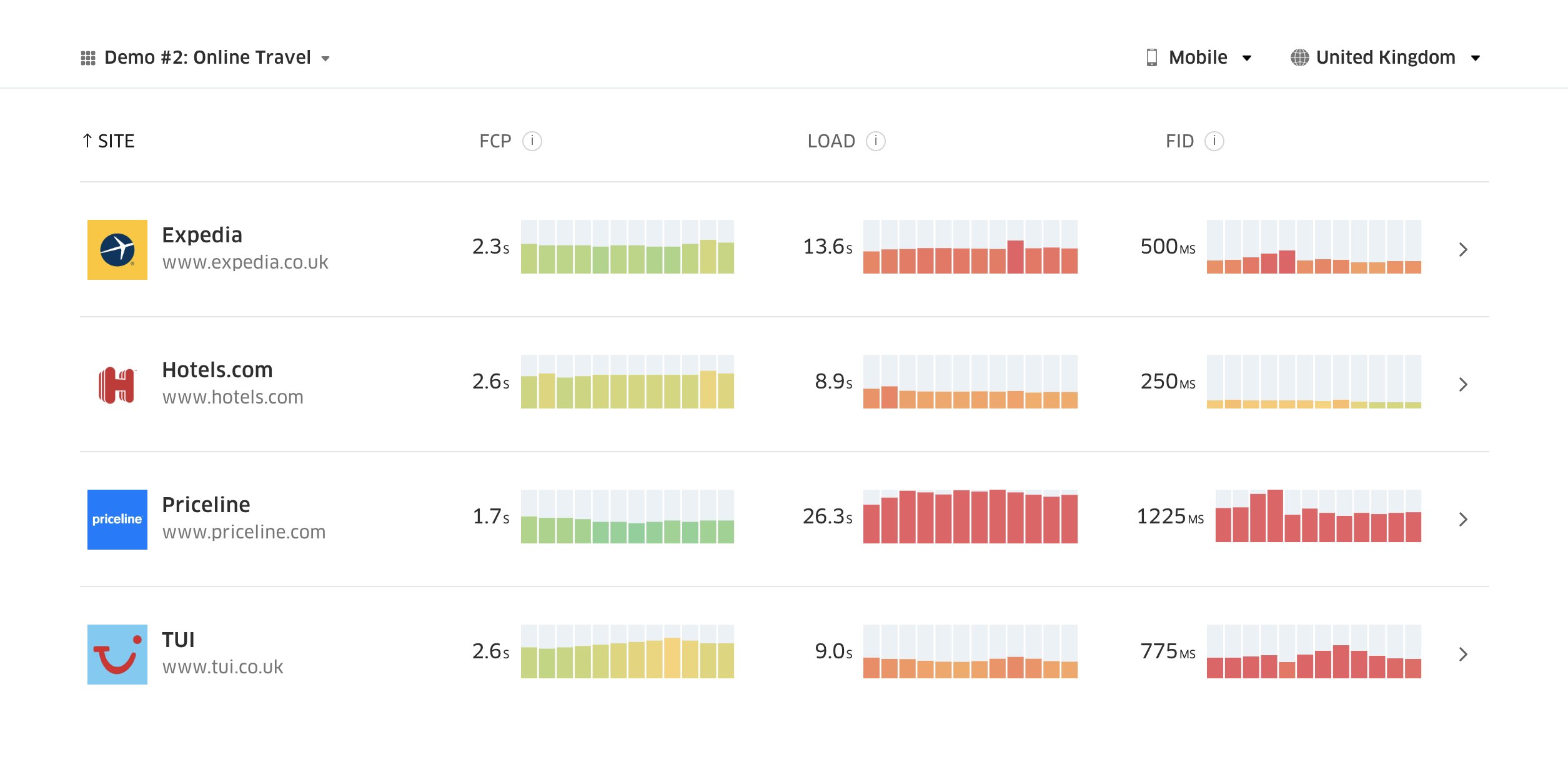
 Introducing the slowest day of the week. Facebook has introduced 2G Tuesdays to increase visibility and sensitivity of slow connections. (Image source)
Introducing the slowest day of the week. Facebook has introduced 2G Tuesdays to increase visibility and sensitivity of slow connections. (Image source)
Luckily, there are many great options that help you automate the collection of data and measure how your website performs over time according to these metrics. Keep in mind that a good performance picture covers a set of performance metrics, lab data and field data:
The former is particularly useful during development as it will help you identify, isolate and fix performance issues while working on the product. The latter is useful for long-term maintenance as it will help you understand your performance bottlenecks as they are happening live — when users actually access the site.
By tapping into built-in RUM APIs such as Navigation Timing, Resource Timing, Paint Timing, Long Tasks, etc., synthetic testing tools and RUM together provide a complete picture of performance in your application. You could use Calibre, Treo, SpeedCurve, mPulse and Boomerang, Sitespeed.io, which all are great options for performance monitoring. Furthermore, with Server Timing header, you could even
monitor back-end and front-end performance all in one place.
Note: It’s always a safer bet to choose network-level throttlers, external to the browser, as, for example, DevTools has issues interacting with HTTP/2 push, due to the way it’s implemented (thanks, Yoav, Patrick!). For Mac OS, we can use Network Link Conditioner, for Windows Windows Traffic Shaper, for Linux netem, and for FreeBSD dummynet.
As it’s likely that you’ll be testing in Lighthouse, keep in mind that you can:
- Set up”clean”and”customer”profiles for testing.
While running tests in passive monitoring tools, it’s a common strategy to turn off anti-virus and background CPU tasks, remove background bandwidth transfers and test with a clean user profile without browser extensions to avoid skewed results (in Firefox, and in Chrome).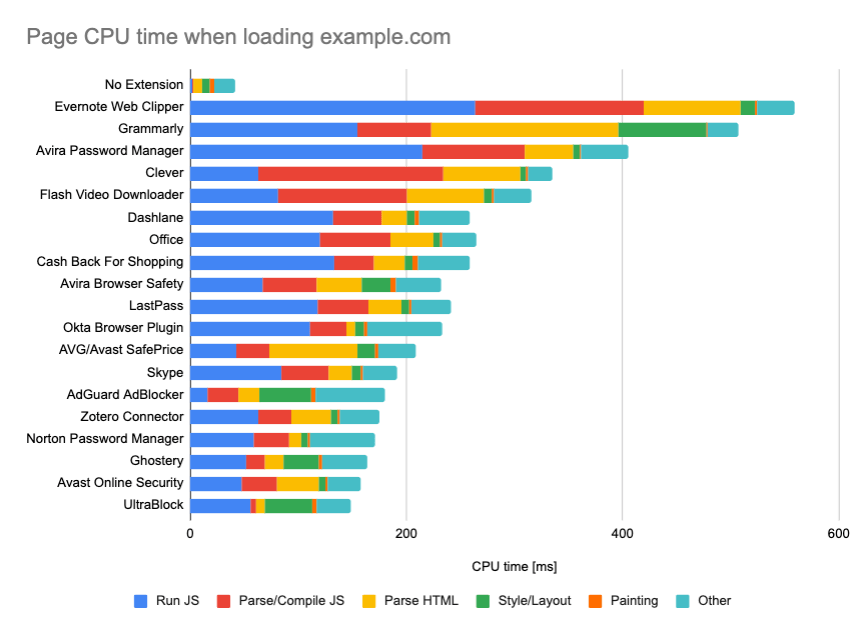
However, it’s also a good idea to study which browser extensions your customers use frequently, and test with dedicated “customer”profiles as well. In fact, some extensions might have a profound performance impact (2020 Chrome Extension Performance Report) on your application, and if your users use them a lot, you might want to account for it up front. Hence,”clean”profile results alone are overly optimistic and can be crushed in real-life scenarios.
- Share the performance goals with your colleagues.
Make sure that performance goals are familiar to every member of your team to avoid misunderstandings down the line. Every decision — be it design, marketing or anything in-between — has performance implications, and distributing responsibility and ownership across the entire team would streamline performance-focused decisions later on. Map design decisions against performance budget and the priorities defined early on.
Setting Realistic Goals
- 100-millisecond response time, 60 fps.
For an interaction to feel smooth, the interface has 100ms to respond to user’s input. Any longer than that, and the user perceives the app as laggy. The RAIL, a user-centered performance model gives you healthy targets: To allow for <100 milliseconds response, the page must yield control back to main thread at latest after every <50 milliseconds. Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. For high-pressure points like animation, it’s best to do nothing else where you can and the absolute minimum where you can’t.
 RAIL, a user-centric performance model.
RAIL, a user-centric performance model. Also, each frame of animation should be completed in less than 16 milliseconds, thereby achieving 60 frames per second (1 second ÷ 60=16.6 milliseconds) — preferably under 10 milliseconds. Because the browser needs time to paint the new frame to the screen, your code should finish executing before hitting the 16.6 milliseconds mark. We’re starting to have conversations about 120fps (e.g. iPad Pro’s screens run at 120Hz) and Surma has covered some rendering performance solutions for 120fps, but that’s probably not a target we’re looking at just yet.
Be pessimistic in performance expectations, but be optimistic in interface design and use idle time wisely (check idlize, idle-until-urgent and react-idle). Obviously, these targets apply to runtime performance, rather than loading performance.
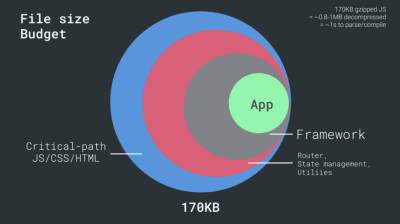
- FID <100ms, LCP <2.5s, TTI <5s on 3G, Critical file size budget <170KB (gzipped).
Although it might be very difficult to achieve, a good ultimate goal would be Time to Interactive under 5s, and for repeat visits, aim for under 2s (achievable only with a service worker). Aim for Largest Contentful Paint of under 2.5s and minimize Total Blocking Time and Cumulative Layout Shift. An acceptable First Input Delay is under 100ms–70ms. As mentioned above, we’re considering the baseline being a $200 Android phone (e.g. Moto G4) on a slow 3G network, emulated at 400ms RTT and 400kbps transfer speed.We have two major constraints that effectively shape a reasonable target for speedy delivery of the content on the web. On the one hand, we have network delivery constraints due to TCP Slow Start. The first 14KB of the HTML — 10 TCP packets, each 1460 bytes, making around 14.25 KB, albeit not to be taken literally — is the most critical payload chunk, and the only part of the budget that can be delivered in the first roundtrip (which is all you get in 1 sec at 400ms RTT due to mobile wake-up times).
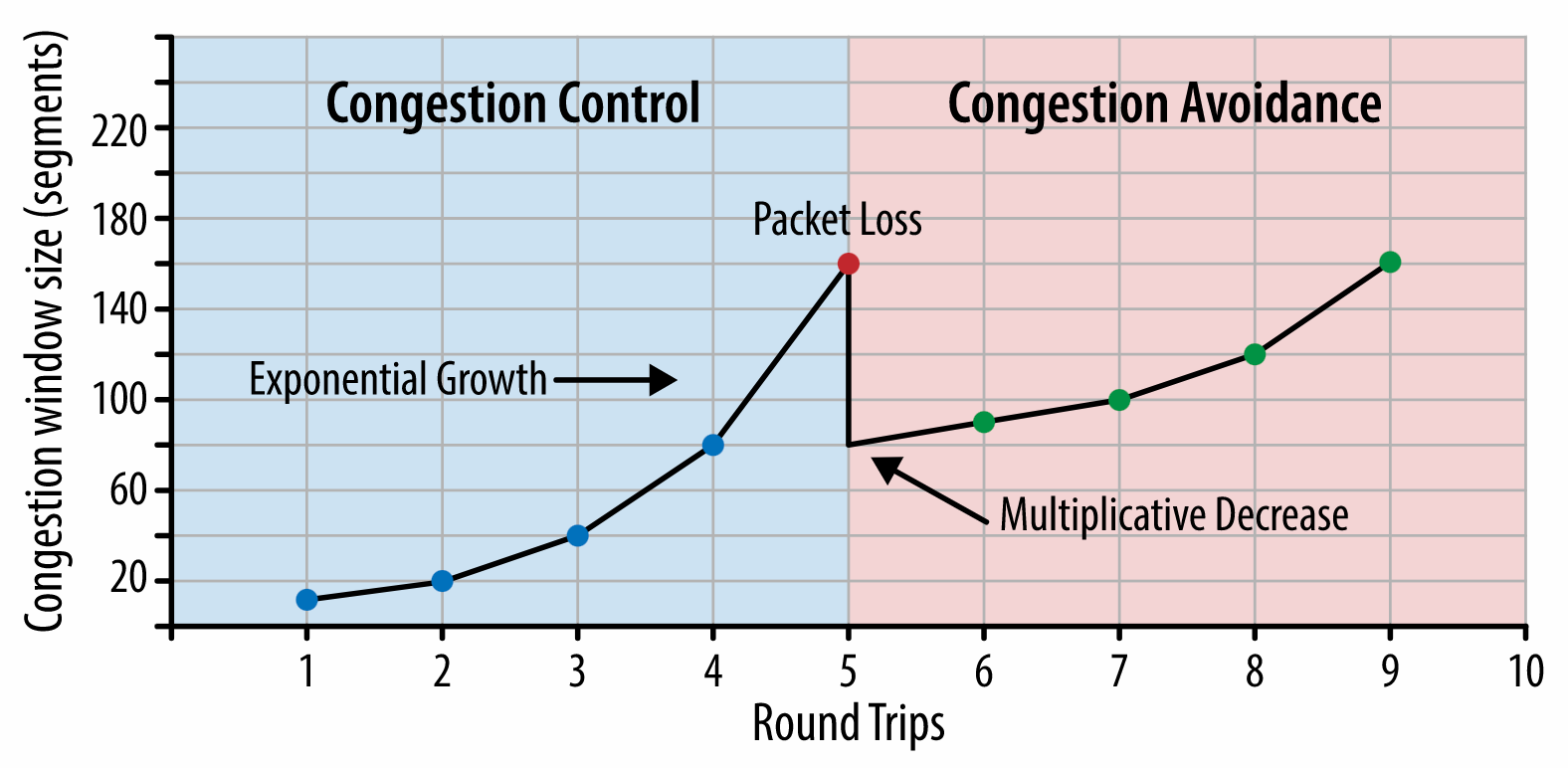
(Note: as TCP generally under-utilizes network connection by a significant amount, Google has developed TCP Bottleneck Bandwidth and RRT (BBR), a TCP delay-controlled TCP flow control algorithm. Designed for the modern web, it responds to actual congestion, rather than packet loss like TCP does, it is significantly faster, with higher throughput and lower latency — and the algorithm works differently. (thanks, Victor, Barry!)
On the other hand, we have hardware constraints on memory and CPU due to JavaScript parsing and execution times (we’ll talk about them in detail later). To achieve the goals stated in the first paragraph, we have to consider the critical file size budget for JavaScript. Opinions vary on what that budget should be (and it heavily depends on the nature of your project), but a budget of 170KB JavaScript gzipped already would take up to 1s to parse and compile on a mid-range phone. Assuming that 170KB expands to 3× that size when decompressed (0.7MB), that already could be the death knell of a”decent”user experience on a Moto G4/G5 Plus.
In the case of Wikipedia’s website, in 2020, globally, code execution has got 19% faster for Wikipedia users. So, if your year-over-year web performance metrics stay stable, that’s usually a warning sign as you’re actually regressing as the environment keeps improving (details in a blog post by Gilles Dubuc).
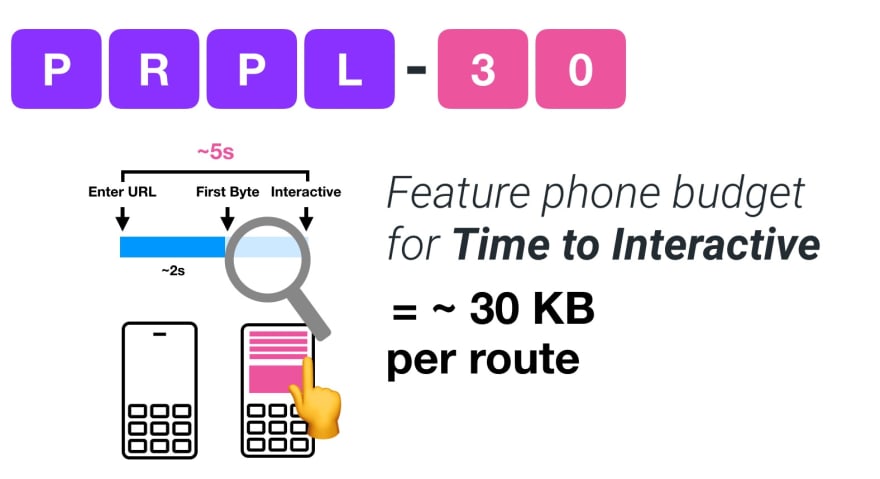
If you want to target growing markets such as South East Asia, Africa or India, you’ll have to look into a very different set of constraints. Addy Osmani covers major feature phone constraints, such as few low cost, high-quality devices, unavailability of high-quality networks and expensive mobile data — along with PRPL-30 budget and development guidelines for these environments.
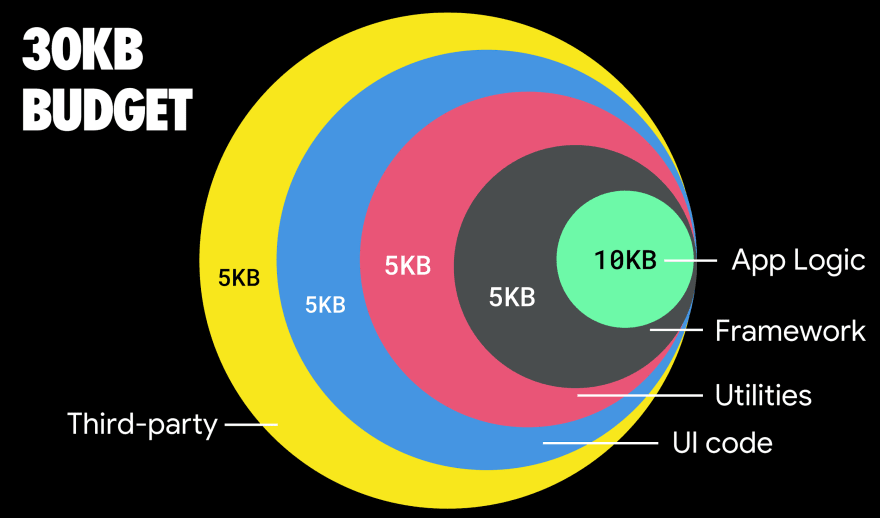
In fact, Google’s Alex Russell recommends to aim for 130–170KB gzipped as a reasonable upper boundary. In real-world scenarios, most products aren’t even close: a median bundle size today is around 452KB, which is up 53.6% compared to early 2015. On a middle-class mobile device, that accounts for 12–20 seconds for Time-To-Interactive.
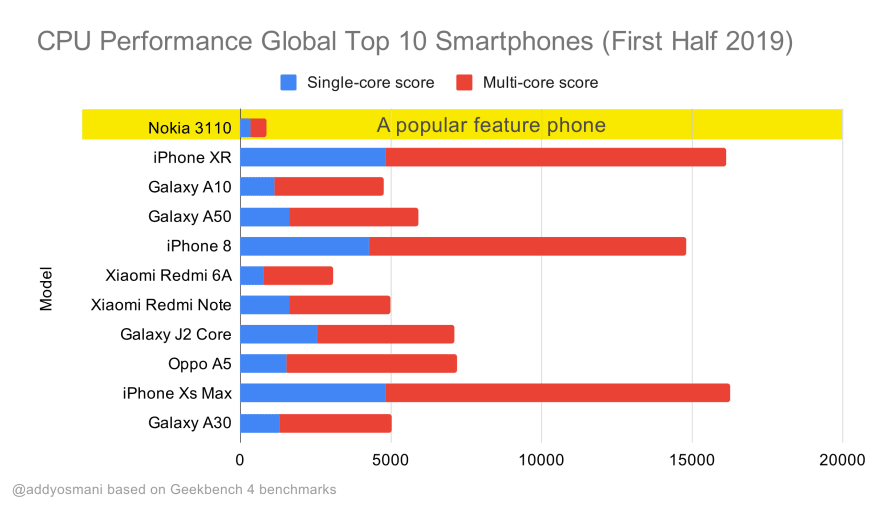
We could also go beyond the bundle size budget though. For example, we could set performance budgets based on the activities of the browser’s main thread, i.e. paint time before start render, or track down front-end CPU hogs. Tools such as Calibre, SpeedCurve and Bundlesize can help you keep your budgets in check, and can be integrated into your build process.
Finally, a performance budget probably shouldn’t be a fixed value. Depending on the network connection, performance budgets should adapt, but payload on slower connection is much more”expensive”, regardless of how they’re used.
Note: It might sound strange to set such rigid budgets in times of wide-spread HTTP/2, upcoming 5G and HTTP/3, rapidly evolving mobile phones and flourishing SPAs. However, they do sound reasonable when we deal with the unpredictable nature of the network and hardware, including everything from congested networks to slowly developing infrastructure, to data caps, proxy browsers, save-data mode and sneaky roaming charges.
 From Fast By Default: Modern loading best practices by Addy Osmani (Slide 19)
From Fast By Default: Modern loading best practices by Addy Osmani (Slide 19)
Defining The Environment
- Choose and set up your build tools.
Don’t pay too much attention to what’s supposedly cool these days. Stick to your environment for building, be it Grunt, Gulp, Webpack, Parcel, or a combination of tools. As long as you are getting results you need and you have no issues maintaining your build process, you’re doing just fine.Among the build tools, Rollup keeps gaining traction, so does Snowpack, but Webpack seems to be the most established one, with literally hundreds of plugins available to optimize the size of your builds. Watch out for the Webpack Roadmap 2021.
One of the most notable strategies that appeared recently is Granular chunking with Webpack in Next.js and Gatsby to minimize duplicate code. By default, modules that aren’t shared in every entry point can be requested for routes that do not use it. This ends up becoming an overhead as more code is downloaded than necessary. With granular chunking in Next.js, we can use a server-side build manifest file to determine which outputted chunks are used by different entry points.
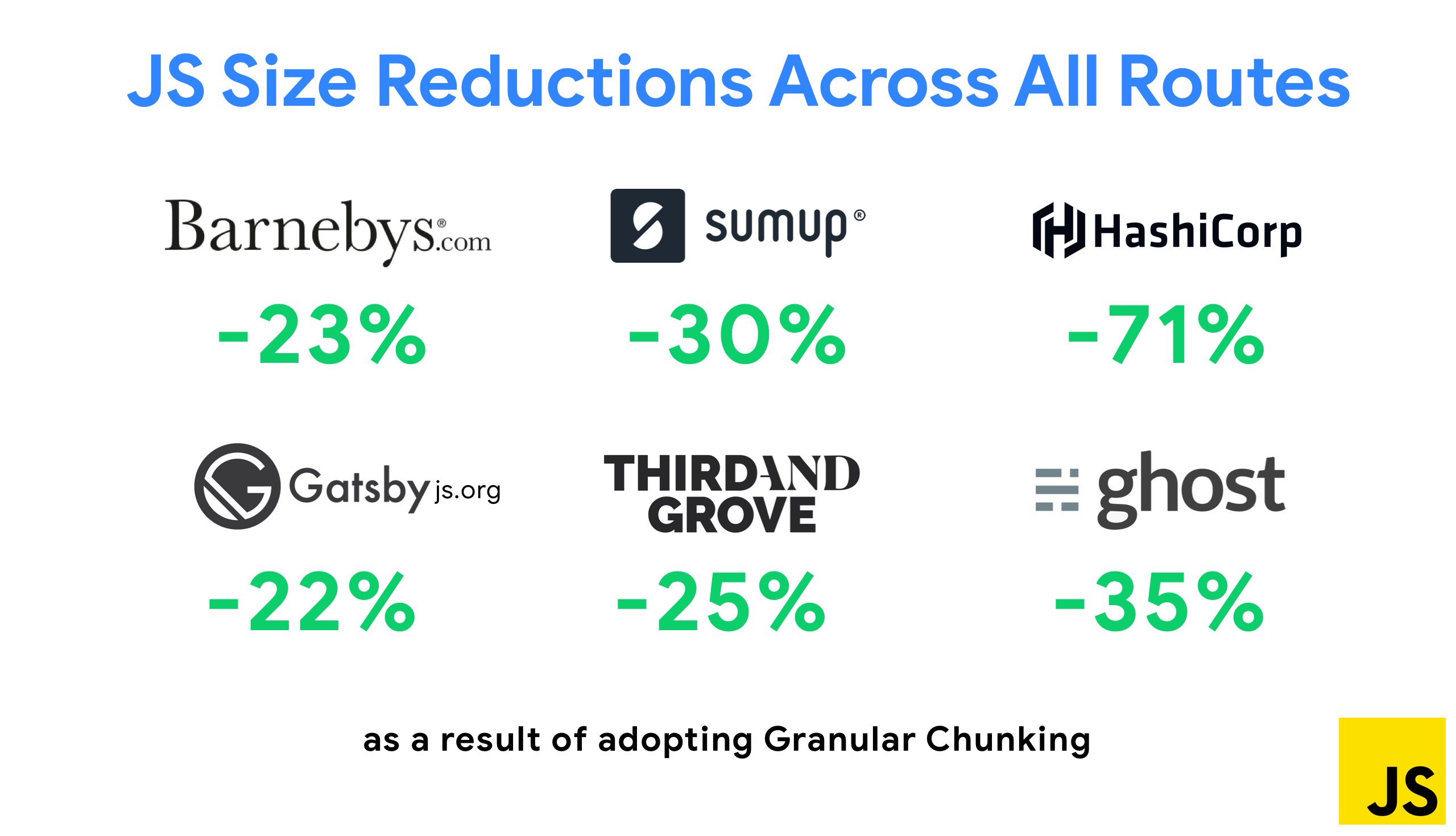
With SplitChunksPlugin, multiple split chunks are created depending on a number of conditions to prevent fetching duplicated code across multiple routes. This improves page load time and caching during navigations. Shipped in Next.js 9.2 and in Gatsby v2.20.7.
Getting started with Webpack can be tough though. So if you want to dive into Webpack, there are some great resources out there:
- Webpack documentation — obviously — is a good starting point, and so are Webpack — The Confusing Bits by Raja Rao and An Annotated Webpack Config by Andrew Welch.
- Sean Larkin has a free course on Webpack: The Core Concepts and Jeffrey Way has released a fantastic free course on Webpack for everyone. Both of them are great introductions for diving into Webpack.
- Webpack Fundamentals is a very comprehensive 4h course with Sean Larkin, released by FrontendMasters.
- Webpack examples has hundreds of ready-to-use Webpack configurations, categorized by topic and purpose. Bonus: there is also a Webpack config configurator that generates a basic configuration file.
- awesome-webpack is a curated list of useful Webpack resources, libraries and tools, including articles, videos, courses, books and examples for Angular, React and framework-agnostic projects.
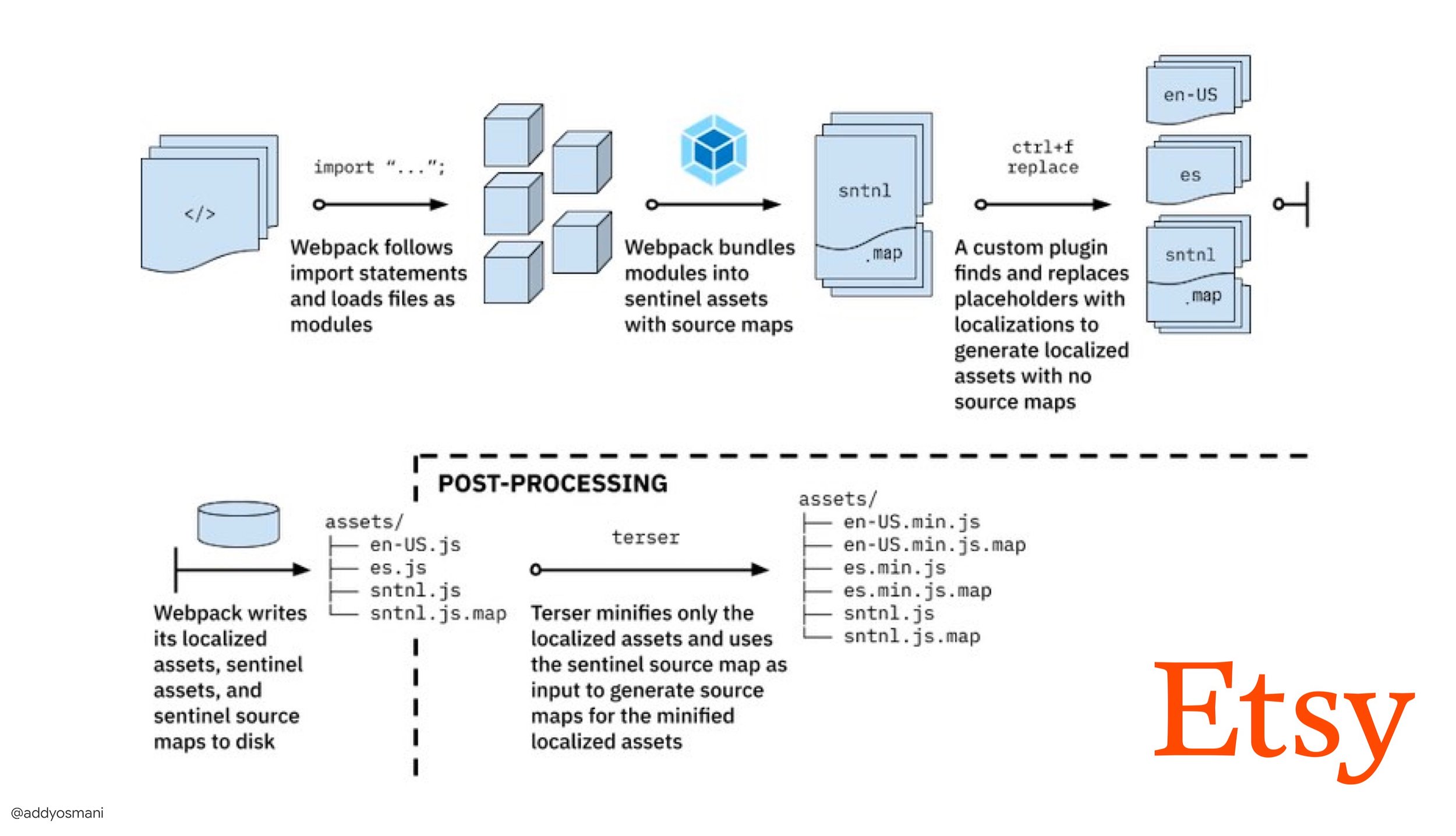
- The journey to fast production asset builds with Webpack is Etsy’s case study on how the team switched from using a RequireJS-based JavaScript build system to using Webpack and how they optimized theird builds, managing over 13,200 assets in 4 mins on average.
- Webpack performance tips is a goldmine thread by Ivan Akulov, featuring many performance-focused tips, including the ones focused specifically on Webpack.
- awesome-webpack-perf is a goldmine GitHub repo with useful Webpack tools and plugins for performance. Also maintained by Ivan Akulov.
- Use progressive enhancement as a default.
Still, after all these years, keeping progressive enhancement as the guiding principle of your front-end architecture and deployment is a safe bet. Design and build the core experience first, and then enhance the experience with advanced features for capable browsers, creating resilient experiences. If your website runs fast on a slow machine with a poor screen in a poor browser on a sub-optimal network, then it will only run faster on a fast machine with a good browser on a decent network.In fact, with adaptive module serving, we seem to be taking progressive enhancement to another level, serving”lite”core experiences to low-end devices, and enhancing with more sophisticated features for high-end devices. Progressive enhancement isn’t likely to fade away any time soon.
- Choose a strong performance baseline.
With so many unknowns impacting loading — the network, thermal throttling, cache eviction, third-party scripts, parser blocking patterns, disk I/O, IPC latency, installed extensions, antivirus software and firewalls, background CPU tasks, hardware and memory constraints, differences in L2/L3 caching, RTTS — JavaScript has the heaviest cost of the experience, next to web fonts blocking rendering by default and images often consuming too much memory. With the performance bottlenecks moving away from the server to the client, as developers, we have to consider all of these unknowns in much more detail.With a 170KB budget that already contains the critical-path HTML/CSS/JavaScript, router, state management, utilities, framework, and the application logic, we have to thoroughly examine network transfer cost, the parse/compile-time and the runtime cost of the framework of our choice. Luckily, we’ve seen a huge improvement over the last few years in how fast browsers can parse and compile scripts. Yet the execution of JavaScript is still the main bottleneck, so paying close attention to script execution time and network can be impactful.
Tim Kadlec has conduct a fantastic research on the performance of modern frameworks, and summarized them in the article “JavaScript frameworks have a cost”. We often speak about the impact of standalone frameworks, but as Tim notes, in practice, it’s not uncommon to have multiple frameworks in use. Perhaps an older version of jQuery that’s being slowly migrated to a modern framework, along with a few legacy applications using an older version of Angular. So it’s more reasonable to explore the cumulative cost of JavaScript bytes and CPU execution time that can easily make user experiences barely usable, even on high-end devices.
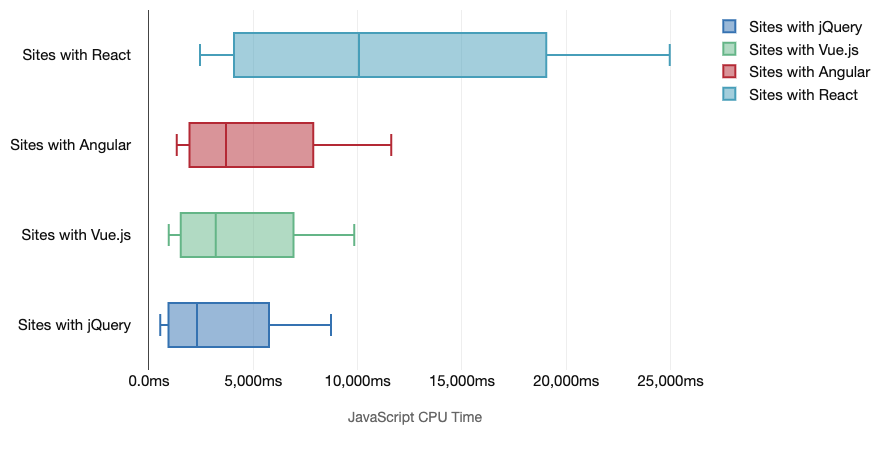
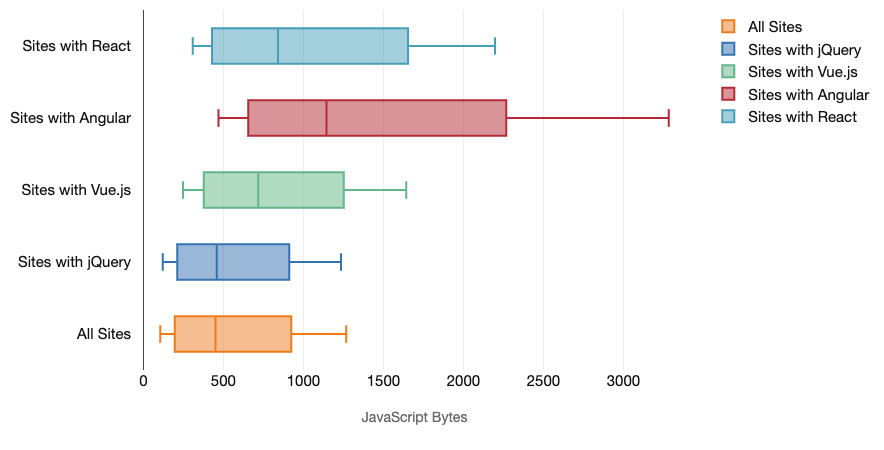
In general, modern frameworks aren’t prioritizing less powerful devices, so the experiences on a phone and on desktop will often be dramatically different in terms of performances. According to research, sites with React or Angular spend more time on the CPU than others (which of course isn’t necessarily to say that React is more expensive on the CPU than Vue.js).
According to Tim, one thing is obvious:”if you’re using a framework to build your site, you’re making a trade-off in terms of initial performance — even in the best of scenarios.”
- Evaluate frameworks and dependencies.
Now, not every project needs a framework and not every page of a single-page-application needs to load a framework. In Netflix’s case,”removing React, several libraries and the corresponding app code from the client-side reduced the total amount of JavaScript by over 200KB, causing an over-50% reduction in Netflix’s Time-to-Interactivity for the logged-out homepage.”The team then utilized the time spent by users on the landing page to prefetch React for subsequent pages that users were likely to land on (read on for details).So what if you remove an existing framework on critical pages altogether? With Gatsby, you can check gatsby-plugin-no-javascript that removes all JavaScript files created by Gatsby from the static HTML files. On Vercel, you can also allow disabling runtime JavaScript in production for certain pages (experimental).
Once a framework is chosen, we’ll be staying with it for at least a few years, so if we need to use one, we need make sure our choice is informed and well considered — and that goes especially for key performance metrics that we care about.
Data shows that, by default, frameworks are quite expensive: 58.6% of React pages ship over 1 MB of JavaScript, and 36% of Vue.js page loads have a First Contentful Paint of <1.5s. According to a study by Ankur Sethi,”your React application will never load faster than about 1.1 seconds on an average phone in India, no matter how much you optimize it. Your Angular app will always take at least 2.7 seconds to boot up. The users of your Vue app will need to wait at least 1 second before they can start using it.”You might not be targeting India as your primary market anyway, but users accessing your site with suboptimal network conditions will have a comparable experience.
Of course it is possible to make SPAs fast, but they aren’t fast out of the box, so we need to account for the time and effort required to make and keep them fast. It’s probably going to be easier by choosing a lightweight baseline performance cost early on.
So how do we choose a framework? It’s a good idea to consider at least the total cost on size + initial execution times before choosing an option; lightweight options such as Preact, Inferno, Vue, Svelte, Alpine or Polymer can get the job done just fine. The size of your baseline will define the constraints for your application’s code.
As noted by Seb Markbåge, a good way to measure start-up costs for frameworks is to first render a view, then delete it and then render again as it can tell you how the framework scales. The first render tends to warm up a bunch of lazily compiled code, which a larger tree can benefit from when it scales. The second render is basically an emulation of how code reuse on a page affects the performance characteristics as the page grows in complexity.
You could go as far as evaluating your candidates (or any JavaScript library in general) on Sacha Greif’s 12-point scale scoring system by exploring features, accessibility, stability, performance, package ecosystem, community, learning curve, documentation, tooling, track record, team, compatibility, security for example.
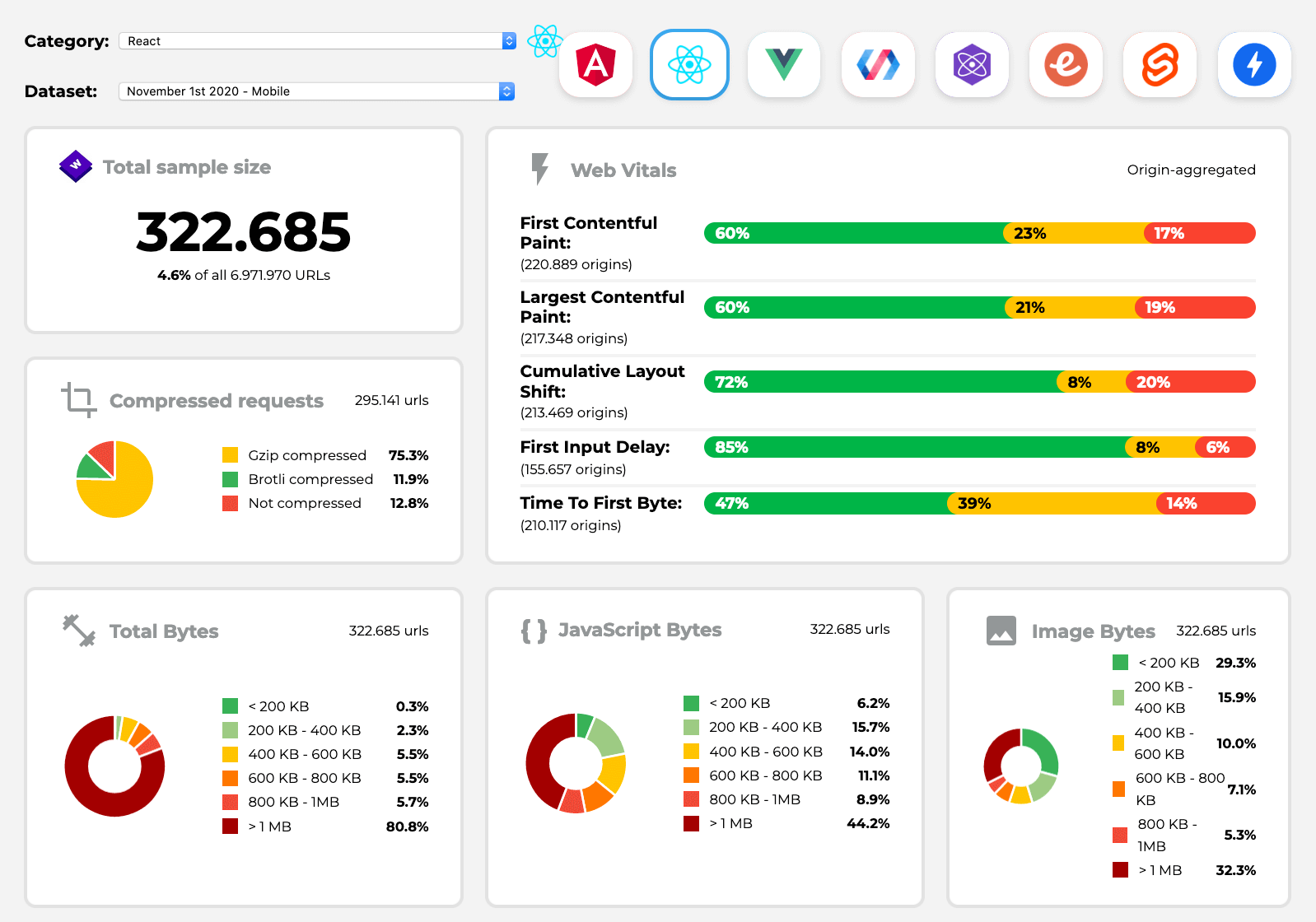
You can also rely on data collected on the web over a longer period of time. For example, Perf Track tracks framework performance at scale, showing origin-aggregated Core Web Vitals scores for websites built in Angular, React, Vue, Polymer, Preact, Ember, Svelte and AMP. You can even specify and compare websites built with Gatsby, Next.js or Create React App, as well as websites built with Nuxt.js (Vue) or Sapper (Svelte).
A good starting point is to choose a good default stack for your application. Gatsby (React), Next.js (React), Vuepress (Vue), Preact CLI, and PWA Starter Kit provide reasonable defaults for fast loading out of the box on average mobile hardware. Also, take a look at web.dev framework-specific performance guidance for React and Angular (thanks, Phillip!).
And perhaps you could take a slightly more refreshing approach to building single-page applications altogether — Turbolinks, a 15KB JavaScript-library that uses HTML instead of JSON to render views. So when you follow a link, Turbolinks automatically fetches the page, swaps in its
, and merges its, all without incurring the cost of a full page load. You can check quick detils and full documentation about the stack (Hotwire).
- Client-side rendering or server-side rendering? Both!
That’s a quite heated conversation to have. The ultimate approach would be to set up some sort of progressive booting: Use server-side rendering to get a quick First Contenful Paint, but also include some minimal necessary JavaScript to keep the time-to-interactive close to the First Contentful Paint. If JavaScript is coming too late after the FCP, the browser will lock up the main thread while parsing, compiling and executing late-discovered JavaScript, hence handcuffing the interactivity of site or application.To avoid it, always break up the execution of functions into separate, asynchronous tasks, and where possible use
requestIdleCallback. Consider lazy loading parts of the UI using WebPack’s dynamicimport()support, avoiding the load, parse, and compile cost until users really need them (thanks Addy!).As mentioned above, Time to Interactive (TTI) tells us the time between navigation and interactivity. In detail, the metric is defined by looking at the first five-second window after the initial content is rendered, in which no JavaScript tasks take longer than 50ms (Long Tasks). If a task over 50ms occurs, the search for a five-second window starts over. As a result, the browser will first assume that it reached Interactive, just to switch to Frozen, just to eventually switch back to Interactive.
Once we reached Interactive, we can then — either on demand or as time allows — boot non-essential parts of the app. Unfortunately, as Paul Lewis noticed, frameworks typically have no simple concept of priority that can be surfaced to developers, and hence progressive booting isn’t easy to implement with most libraries and frameworks.
Still, we are getting there. These days there are a couple of choices we can explore, and Houssein Djirdeh and Jason Miller provide an excellent overview of these options in their talk on Rendering on the Web and Jason’s and Addy’s write-up on Modern Front-End Architectures. The overview below is based on their stellar work.
- Full Server-Side Rendering (SSR)
In classic SSR, such as WordPress, all requests are handled entirely on the server. The requested content is returned as a finished HTML page and browsers can render it right away. Hence, SSR-apps can’t really make use of the DOM APIs, for example. The gap between First Contentful Paint and Time to Interactive is usually small, and the page can be rendered right away as HTML is being streamed to the browser.This avoids additional round-trips for data fetching and templating on the client, since it’s handled before the browser gets a response.
However, we end up with longer server think time and consequently Time To First Byte and we don’t make use of responsive and rich features of modern applications. - Static Rendering
We build out the product as a single page application, but all pages are prerendered to static HTML with minimal JavaScript as a build step. That means that with static rendering, we produce individual HTML files for every possible URL ahead of time, which is something not many applications can afford. But because the HTML for a page doesn’t have to be generated on the fly, we can achieve a consistently fast Time To First Byte. Thus, we can display a landing page quickly and then prefetch a SPA-framework for subsequent pages. Netflix has adopted this approach decreasing loading and Time-to-Interactive by 50%. - Server-Side Rendering With (Re)Hydration (Universal Rendering, SSR + CSR)
We can try to use the best of both worlds — the SSR and the CSR approches. With hydration in the mix, the HTML page returned from the server also contains a script that loads a fully-fledged client-side application. Ideally, that achieve a fast First Contentful Paint (like SSR) and then continue rendering with (re)hydration. Unfortunately, that’s rarely the case. More often, the page does look ready but it can’t respond to user’s input, producing rage clicks and abandonments.With React, we can use
ReactDOMServermodule on a Node server like Express, and then call therenderToStringmethod to render the top level components as a static HTML string.With Vue.js, we can use the vue-server-renderer to render a Vue instance into HTML using
renderToString. In Angular, we can use@nguniversalto turn client requests into fully server-rendered HTML pages. A fully server-rendered experience can also be achieved out of the box with Next.js (React) or Nuxt.js (Vue).The approach has its downsides. As a result, we do gain full flexibility of client-side apps while providing faster server-side rendering, but we also end up with a longer gap between First Contentful Paint and Time To Interactive and increased First Input Delay. Rehydration is very expensive, and usually this strategy alone will not be good enough as it heavily delays Time To Interactive.
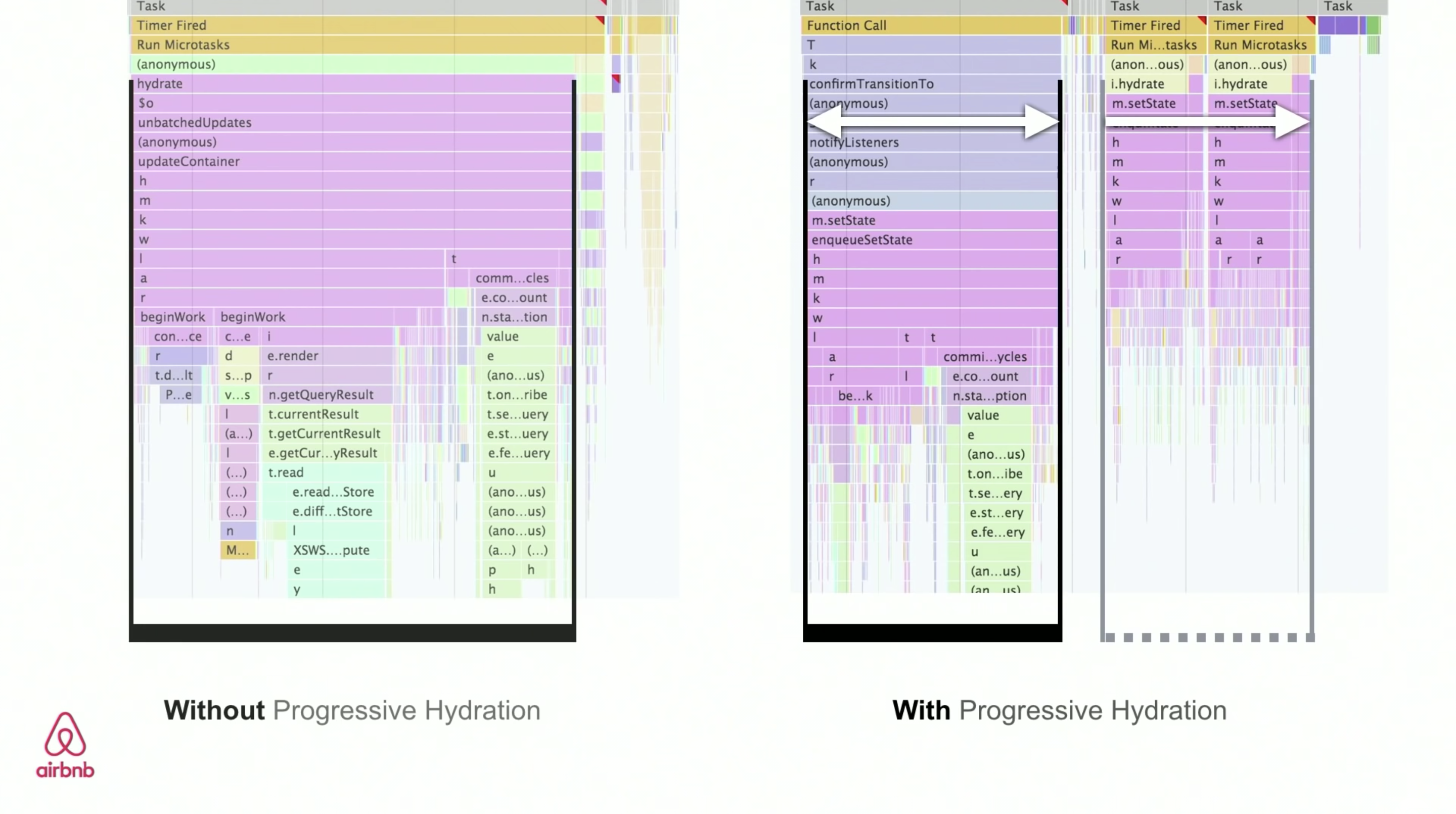
- Streaming Server-Side Rendering With Progressive Hydration (SSR + CSR)
To minimize the gap between Time To Interactive and First Contentful Paint, we render multiple requests at once and send down content in chunks as they get generated. So we don’t have to wait for the full string of HTML before sending content to the browser, and hence improve Time To First Byte.In React, instead of
renderToString(), we can use renderToNodeStream() to pipe the response and send the HTML down in chunks. In Vue, we can use renderToStream() that can be piped and streamed. With React Suspense, we might use asynchronous rendering for that purpose, too.On the client-side, rather than booting the entire application at once, we boot up components progressively. Sections of the applications are first broken down into standalone scripts with code splitting, and then hydrated gradually (in order of our priorities). In fact, we can hydrate critical components first, while the rest could be hydrated later. The role of client-side and server-side rendering can then be defined differently per component. We can then also defer hydration of some components until they come into view, or are needed for user interaction, or when the browser is idle.
For Vue, Markus Oberlehner has published a guide on reducing Time To Interactive of SSR apps using hydration on user interaction as well as vue-lazy-hydration, an early-stage plugin that enables component hydration on visibility or specific user interaction. The Angular team works on progressive hydration with Ivy Universal. You can implement partial hydration with Preact and Next.js, too.
- Trisomorphic Rendering
With service workers in place, we can use streaming server rendering for initial/non-JS navigations, and then have the service worker taking on rendering of HTML for navigations after it has been installed. In that case, service worker prerenders content and enables SPA-style navigations for rendering new views in the same session. Works well when you can share the same templating and routing code between the server, client page, and service worker.
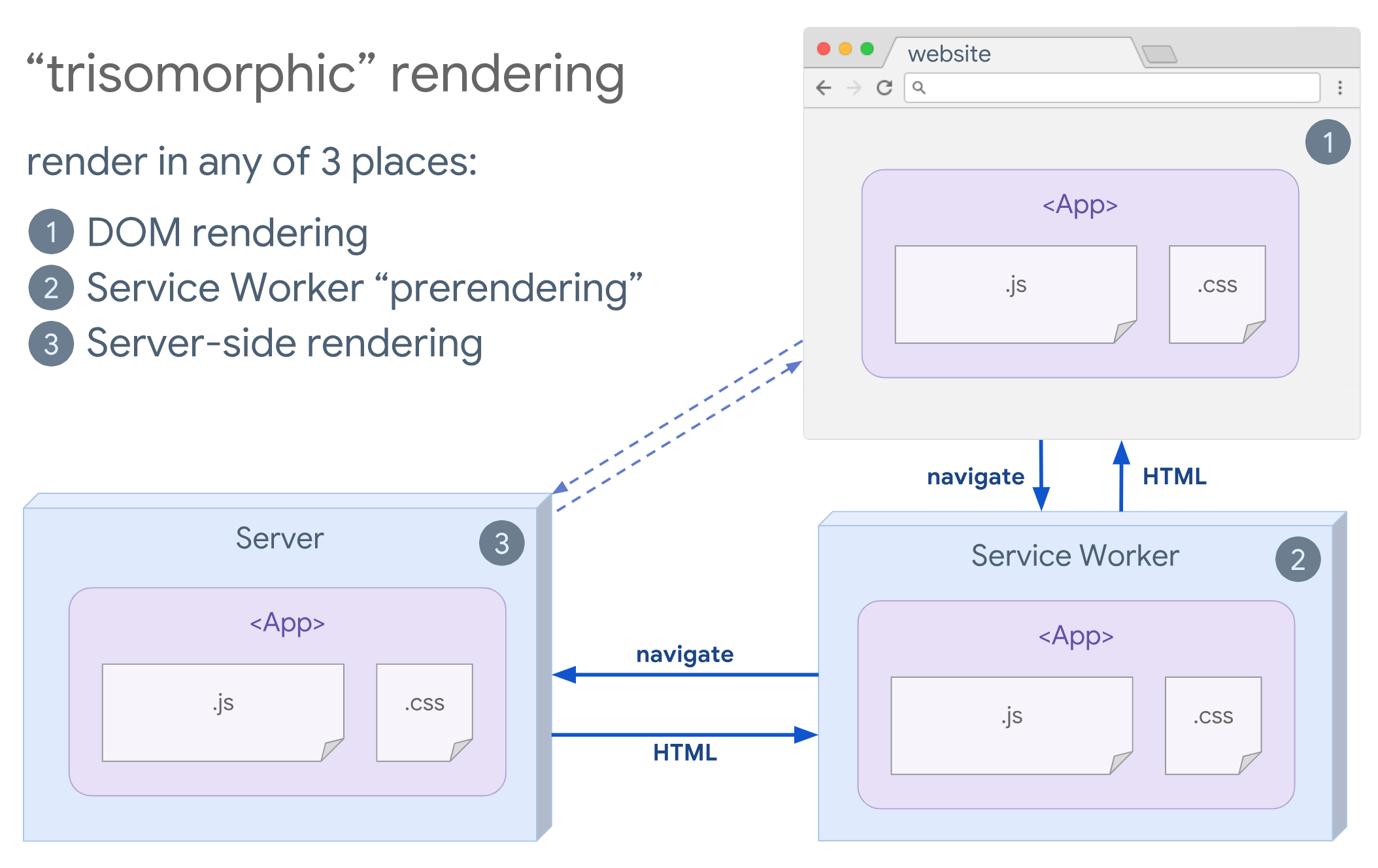
- CSR With Prerendering
Prerendering is similar to server-side rendering but rather than rendering pages on the server dynamically, we render the application to static HTML at build time. While static pages are fully interactive without much client-side JavaScript, prerendering works differently. Basically it captures the initial state of a client-side application as static HTML at build time, while with prerendering the application must be booted on the client for the pages to be interactive.With Next.js, we can use static HTML export by prerendering an app to static HTML. In Gatsby, an open source static site generator that uses React, uses
renderToStaticMarkupmethod instead ofrenderToStringmethod during builds, with main JS chunk being preloaded and future routes are prefetched, without DOM attributes that aren’t needed for simple static pages.For Vue, we can use Vuepress to achieve the same goal. You can also use prerender-loader with Webpack. Navi provides static rendering as well.
The result is a better Time To First Byte and First Contentful Paint, and we reduce the gap between Time To Interactive and First Contentful Paint. We can’t use the approach if the content is expected to change much. Plus, all URLs have to be known ahead of time to generate all the pages. So some components might be rendered using prerendering, but if we need something dynamic, we have to rely on the app to fetch the content.
- Full Client-Side Rendering (CSR)
All logic, rendering and booting are done on the client. The result is usually a huge gap between Time To Interactive and First Contentful Paint. As a result, applications often feel sluggish as the entire app has to be booted on the client to render anything.As JavaScript has a performance cost, as the amount of JavaScript grow with an application, aggressive code-splitting and deferring JavaScript will be absolutely necessarily to tame the impact of JavaScript. For such cases, a server-side rendering will usually be a better approach in case not much interactivity is required. If it’s not an option, consider using The App Shell Model.
In general, SSR is faster than CSR. Yet still, it’s a quite frequent implementation for many apps out there.
So, client-side or server-side? In general, it’s a good idea to limit the use of fully client-side frameworks to pages that absolutely require them. For advanced applications, it’s not a good idea to rely on server-side rendering alone either. Both server-rendering and client-rendering are a disaster if done poorly.
Whether you are leaning towards CSR or SSR, make sure that you are rendering important pixels as soon as possible and minimize the gap between that rendering and Time To Interactive. Consider prerendering if your pages don’t change much, and defer the booting of frameworks if you can. Stream HTML in chunks with server-side rendering, and implement progressive hydration for client-side rendering — and hydrate on visibility, interaction or during idle time to get the best of both worlds.
- Full Server-Side Rendering (SSR)
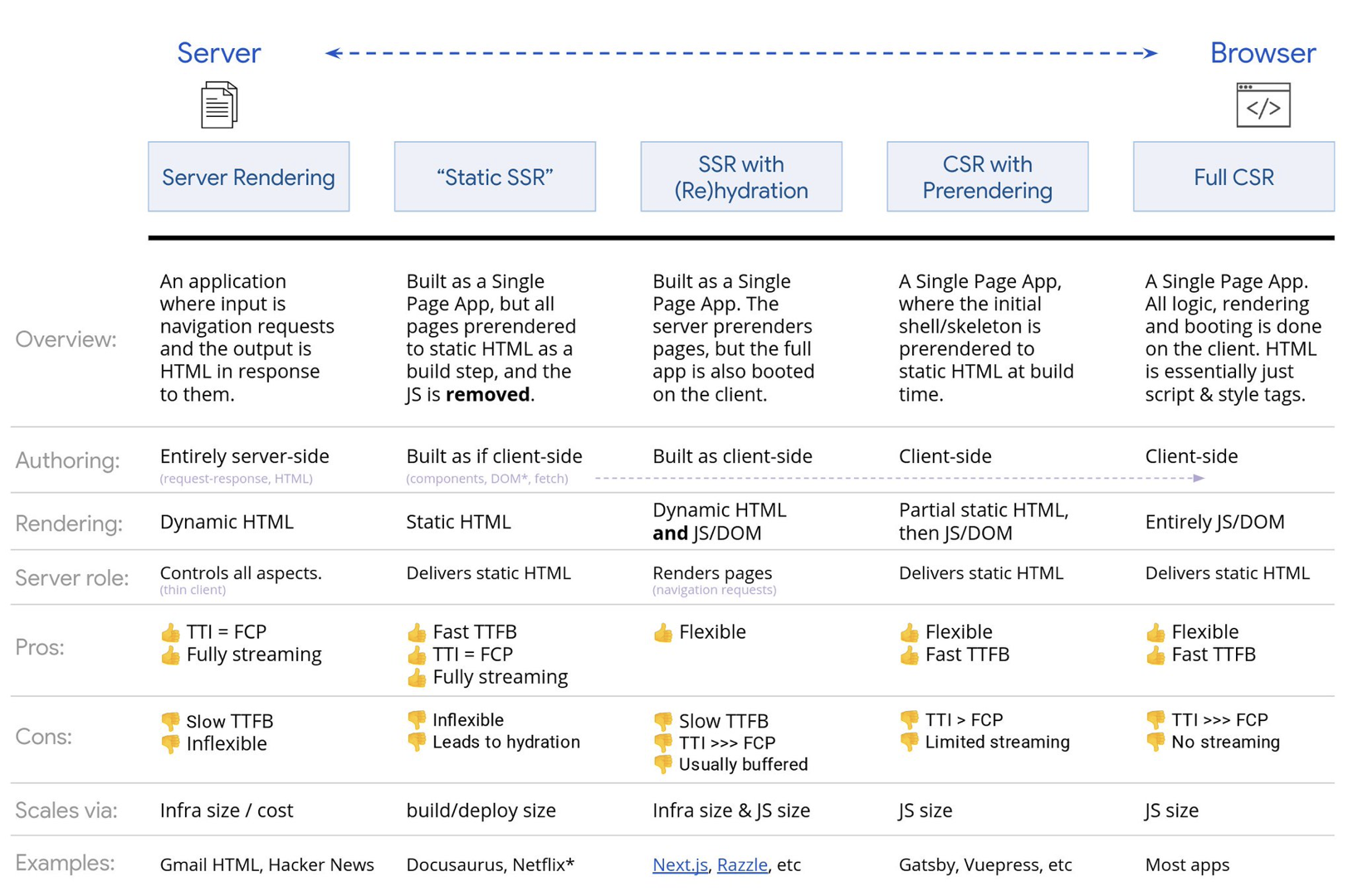
- How much can we serve statically?
Whether you’re working on a large application or a small site, it’s worth considering what content could be served statically from a CDN (i.e. JAM Stack), rather than being generated dynamically on the fly. Even if you have thousands of products and hundreds of filters with plenty of personalization options, you might still want to serve your critical landing pages statically, and decouple these pages from the framework of your choice.There are plenty of static-site generators and the pages they generate are often very fast. The more content we can pre-build ahead of time instead of generating page views on a server or client at request time, the better performance we will achieve.
In Building Partially Hydrated, Progressively Enhanced Static Websites, Markus Oberlehner shows how to build out websites with a static site generator and an SPA, while achieving progressive enhancement and a minimal JavaScript bundle size. Markus uses Eleventy and Preact as his tools, and shows how to set up the tools, add partial hydration, lazy hydration, client entry file, configure Babel for Preact and bundle Preact with Rollup — from start to finish.
With JAMStack used on large sites these days, a new performance consideration appeared: the build time. In fact, building out even thousands of pages with every new deploy can take minutes, so it’s promising to see incremental builds in Gatsby which improve build times by 60 times, with an integration into popular CMS solutions like WordPress, Contentful, Drupal, Netlify CMS and others.
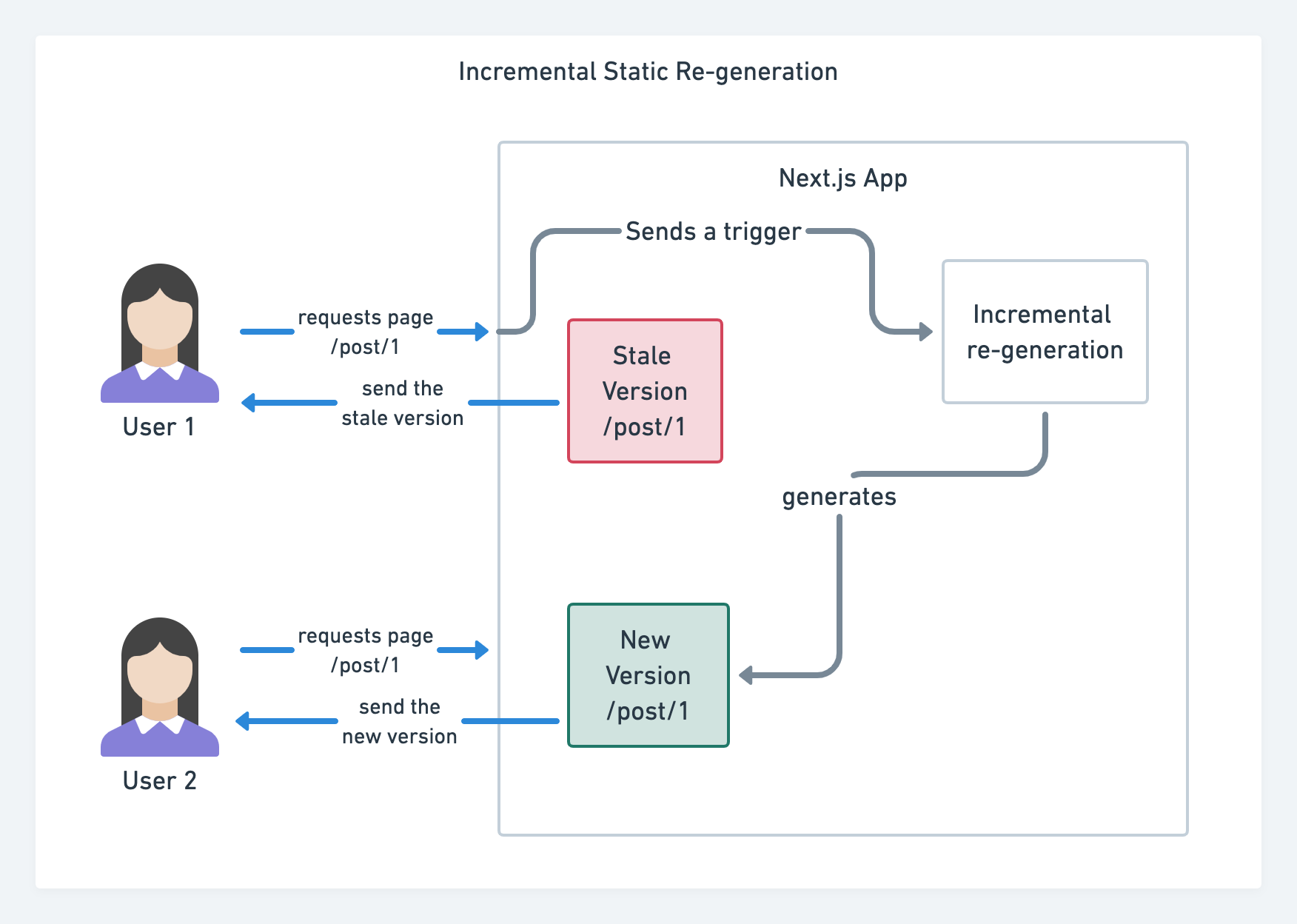
Also, Next.js announced ahead-of-time and incremental static generation, which allows us to add new static pages at runtime and update existing pages after they’ve been already built, by re-rendering them in the background as traffic comes in.
Need an even more lightweight approach? In his talk on Eleventy, Alpine and Tailwind: towards a lightweight Jamstack, Nicola Goutay explains the differences between CSR, SSR and everything-in-between, and shows how to use a more lightweight approach — along with a GitHub repo that shows the approach in practice.
- Consider using PRPL pattern and app shell architecture.
Different frameworks will have different effects on performance and will require different strategies of optimization, so you have to clearly understand all of the nuts and bolts of the framework you’ll be relying on. When building a web app, look into the PRPL pattern and application shell architecture. The idea is quite straightforward: Push the minimal code needed to get interactive for the initial route to render quickly, then use service worker for caching and pre-caching resources and then lazy-load routes that you need, asynchronously.
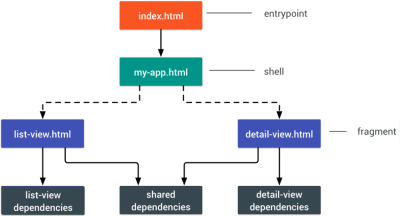 PRPL stands for Pushing critical resource, Rendering initial route, Pre-caching remaining routes and Lazy-loading remaining routes on demand.
PRPL stands for Pushing critical resource, Rendering initial route, Pre-caching remaining routes and Lazy-loading remaining routes on demand.  An application shell is the minimal HTML, CSS, and JavaScript powering a user interface.
An application shell is the minimal HTML, CSS, and JavaScript powering a user interface.
- Have you optimized the performance of your APIs?
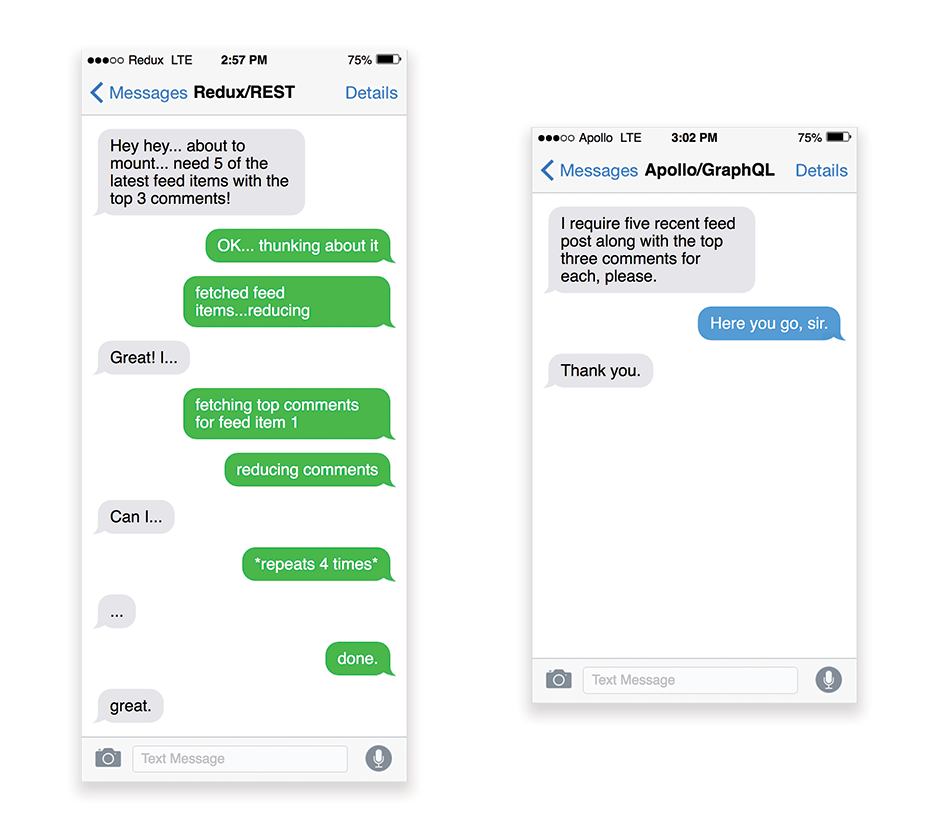
APIs are communication channels for an application to expose data to internal and third-party applications via endpoints. When designing and building an API, we need a reasonable protocol to enable the communication between the server and third-party requests. Representational State Transfer (REST) is a well-established, logical choice: it defines a set of constraints that developers follow to make content accessible in a performant, reliable and scalable fashion. Web services that conform to the REST constraints, are called RESTful web services.As with good ol’HTTP requests, when data is retrieved from an API, any delay in server response will propagate to the end user, hence delaying rendering. When a resource wants to retrieve some data from an API, it will need to request the data from the corresponding endpoint. A component that renders data from several resources, such as an article with comments and author photos in each comment, may need several roundtrips to the server to fetch all the data before it can be rendered. Furthermore, the amount of data returned through REST is often more than what is needed to render that component.
If many resources require data from an API, the API might become a performance bottleneck. GraphQL provides a performant solution to these issues. Per se, GraphQL is a query language for your API, and a server-side runtime for executing queries by using a type system you define for your data. Unlike REST, GraphQL can retrieve all data in a single request, and the response will be exactly what is required, without over or under-fetching data as it typically happens with REST.
In addition, because GraphQL is using schema (metadata that tells how the data is structured), it can already organize data into the preferred structure, so, for example, with GraphQL, we could remove JavaScript code used for dealing with state management, producing a cleaner application code that runs faster on the client.
If you want to get started with GraphQL or encounter performance issues, these articles might be quite helpful:
- A GraphQL Primer: Why We Need A New Kind Of API by Eric Baer,
- A GraphQL Primer: The Evolution Of API Design by Eric Baer,
- Designing a GraphQL server for optimal performance by Leonardo Losoviz,
- GraphQL performance explained by Wojciech Trocki.
- Will you be using AMP or Instant Articles?
Depending on the priorities and strategy of your organization, you might want to consider using Google’s AMP or Facebook’s Instant Articles or Apple’s Apple News. You can achieve good performance without them, but AMP does provide a solid performance framework with a free content delivery network (CDN), while Instant Articles will boost your visibility and performance on Facebook.The seemingly obvious benefit of these technologies for users is guaranteed performance, so at times they might even prefer AMP-/Apple News/Instant Pages-links over”regular”and potentially bloated pages. For content-heavy websites that are dealing with a lot of third-party content, these options could potentially help speed up render times dramatically.
Unless they don’t. According to Tim Kadlec, for example,”AMP documents tend to be faster than their counterparts, but they don’t necessarily mean a page is performant. AMP is not what makes the biggest difference from a performance perspective.”
A benefit for the website owner is obvious: discoverability of these formats on their respective platforms and increased visibility in search engines.
Well, at least that’s how it used to be. As AMP is no longer a requirement for Top Stories, publishers might be moving away from AMP to a traditional stack instead (thanks, Barry!).
Still, you could build progressive web AMPs, too, by reusing AMPs as a data source for your PWA. Downside? Obviously, a presence in a walled garden places developers in a position to produce and maintain a separate version of their content, and in case of Instant Articles and Apple News without actual URLs (thanks Addy, Jeremy!).
- Choose your CDN wisely.
As mentioned above, depending on how much dynamic data you have, you might be able to”outsource”some part of the content to a static site generator, pushing it to a CDN and serving a static version from it, thus avoiding requests to the server. In fact, some of those generators are actually website compilers with many automated optimizations provided out of the box. As compilers add optimizations over time, the compiled output gets smaller and faster over time.Notice that CDNs can serve (and offload) dynamic content as well. So, restricting your CDN to static assets is not necessary. Double-check whether your CDN performs compression and conversion (e.g. image optimization and resizing at the edge), whether they provide support for servers workers, A/B testing, as well as edge-side includes, which assemble static and dynamic parts of pages at the CDN’s edge (i.e. the server closest to the user), and other tasks. Also, check if your CDN supports HTTP over QUIC (HTTP/3).
Katie Hempenius has written a fantastic guide to CDNs that provides insights on how to choose a good CDN, how to finetune it and all the little things to keep in mind when evaluating one. In general, it’s a good idea to cache content as aggressively as possible and enable CDN performance features like Brotli, TLS 1.3, HTTP/2, and HTTP/3.
Note: based on research by Patrick Meenan and Andy Davies, HTTP/2 prioritization is effectively broken on many CDNs, so be careful when choosing a CDN. Patrick has more details in his talk on HTTP/2 Prioritization (thanks, Barry!).
When choosing a CDN, you can use these comparison sites with a detailed overview of their features:
- CDN Comparison, a CDN comparison matrix for Cloudfront, Aazure, KeyCDN, Fastly, Verizon, Stackpach, Akamai and many others.
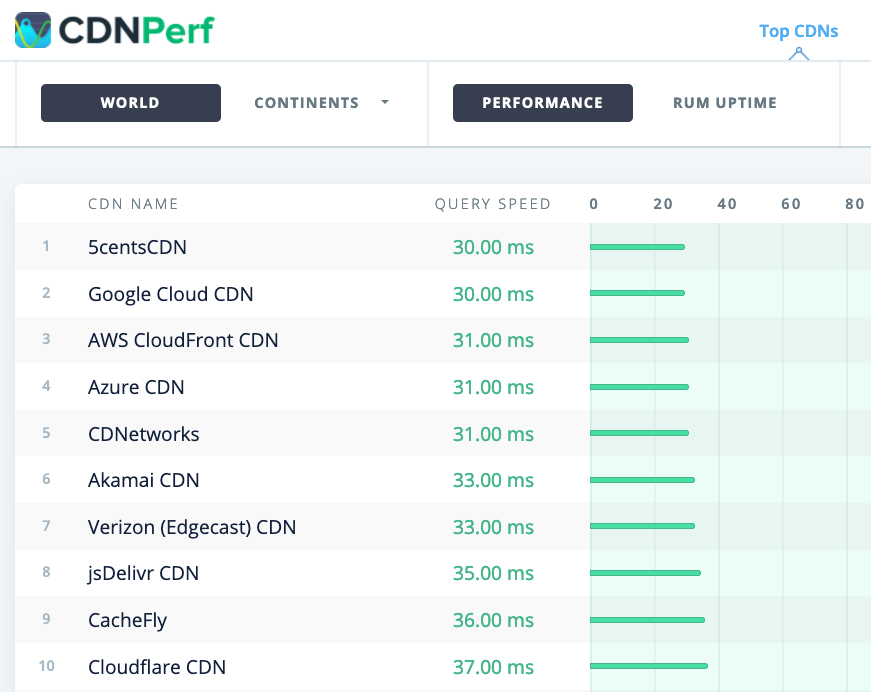
- CDN Perf measures query speed for CDNs by gathering and analyzing 300 million tests every day, with all results based on RUM data from users all over the world. Also check DNS Performance comparison and Cloud Peformance Comparison.
- CDN Planet Guides provides an overview of CDNs for specific topics, such as Serve Stale, Purge, Origin Shield, Prefetch and Compression.
- Web Almanac: CDN Adoption and Usage provides insights on top CDN providers, their RTT and TLS management, TLS negotiation time, HTTP/2 adoption and others. (Unfortunately, the data is only from 2019).
Assets Optimizations
- Use Brotli for plain text compression.
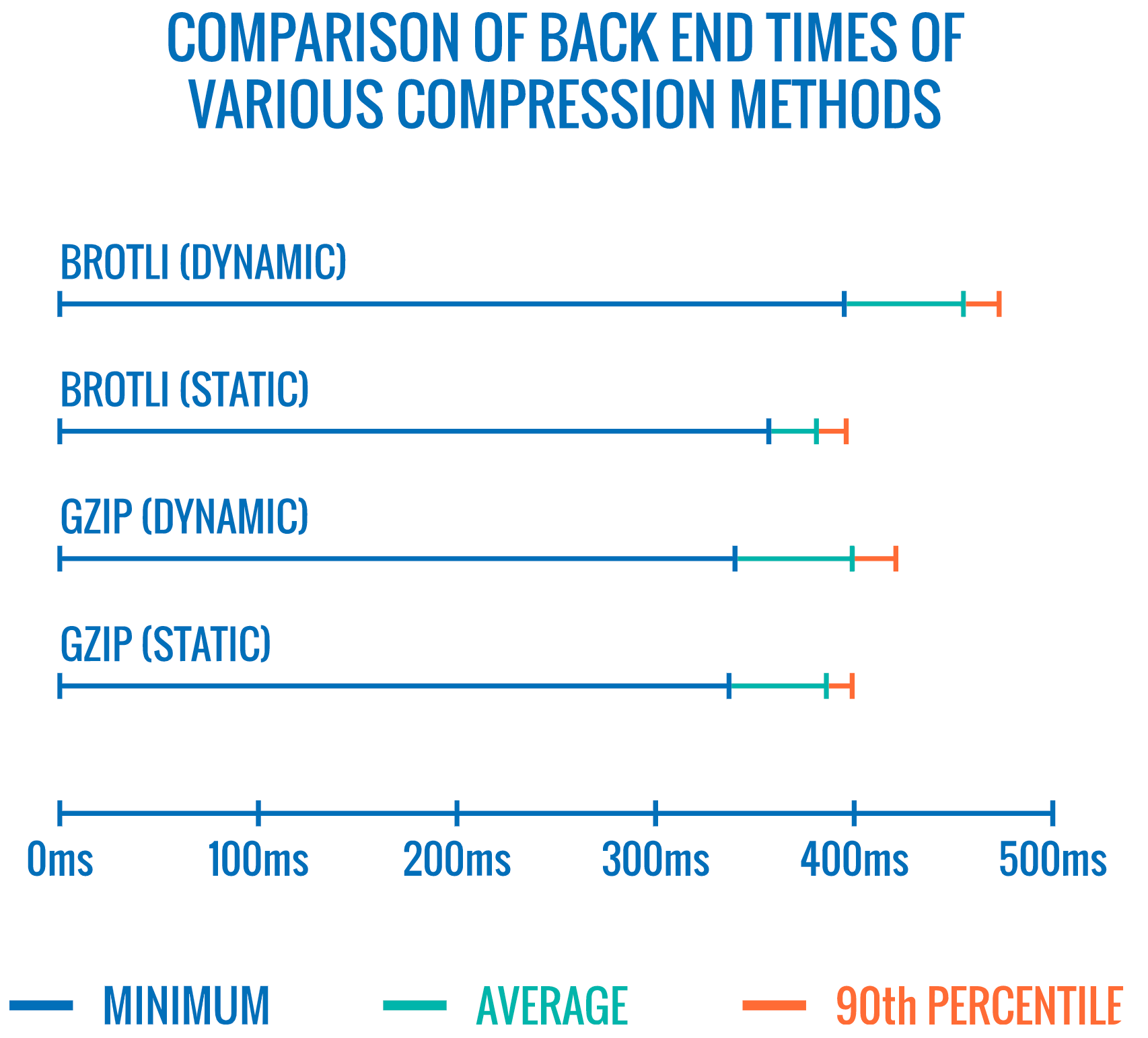
In 2015, Google introduced Brotli, a new open-source lossless data format, which is now supported in all modern browsers. The open sourced Brotli library, that implements an encoder and decoder for Brotli, has 11 predefined quality levels for the encoder, with higher quality level demanding more CPU in exchange for a better compression ratio. Slower compression will ultimately lead to higher compression rates, yet still, Brotli decompresses fast. It’s worth noting though that Brotli with the compression level 4 is both smaller and compresses faster than Gzip.In practice, Brotli appears to be much more effective than Gzip. Opinions and experiences differ, but if your site is already optimized with Gzip, you might be expecting at least single-digit improvements and at best double-digits improvements in size reduction and FCP timings. You can also estimate Brotli compression savings for your site.
Browsers will accept Brotli only if the user is visiting a website over HTTPS. Brotli is widely supported, and many CDNs support it (Akamai, Netlify Edge, AWS, KeyCDN, Fastly (currently only as a pass-through), Cloudflare, CDN77) and you can enable Brotli even on CDNs that don’t support it yet (with a service worker).
The catch is that because compressing all assets with Brotli at a high compression level is expensive, many hosting providers can’t use it at fule scall just because of the huge cost overhead it produces. In fact, at the highest level of compression, Brotli is so slow that any potential gains in file size could be nullified by the amount of time it takes for the server to begin sending the response as it waits to dynamically compress the asset. (But if you have time during the build time with static compression, of course, higher compression settings are preferred.)
This might be changing though. The Brotli file format includes a built-in static dictionary, and in addition to containing various strings in multiple languages, it also supports the option to apply multiple transformations to those words, increasing its versatility. In his research, Felix Hanau has discovered a way to improve the compression at levels 5 through 9 by using”a more specialized subset of the dictionary than the default”and relying on the
Content-Typeheader to tell the compressor if it should use a dictionary for HTML, JavaScript or CSS. The result was a”negligible performance impact (1% to 3% more CPU compared to 12% normally) when compressing web content at high compression levels, using a limited dictionary use approach.”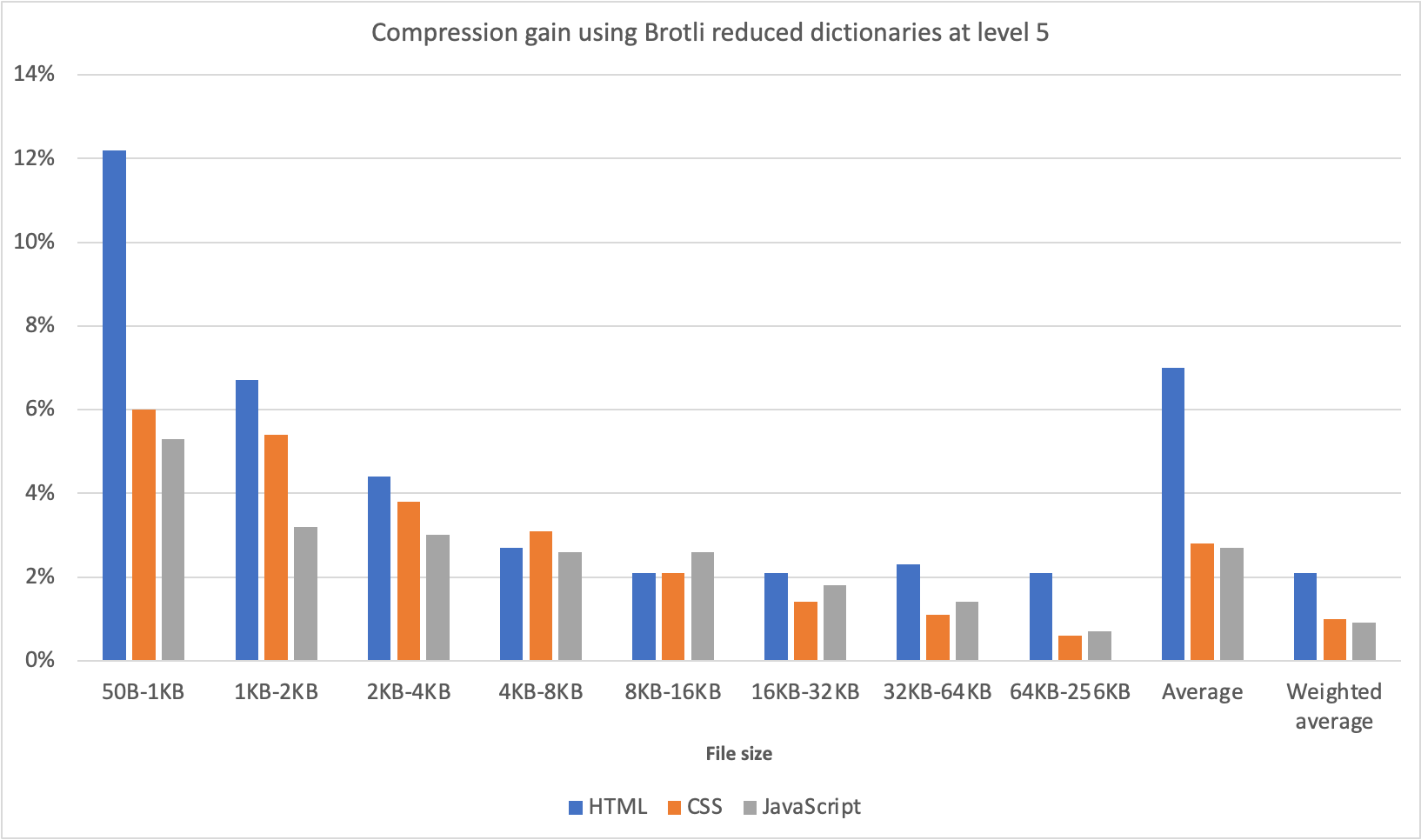
On top of that, with Elena Kirilenko’s research, we can achieve fast and efficient Brotli recompression using previous compression artifacts. According to Elena,”once we have an asset compressed via Brotli, and we’re trying to compress dynamic content on-the-fly, where the content resembles content available to us ahead of time, we can achieve significant improvements in compression times.”
How often is it the case? Por exemplo. with delivery of JavaScript bundles subsets (e.g. when parts of the code are already cached on the client or with dynamic bundle serving with WebBundles). Or with dynamic HTML based on known-in-advance templates, or dynamically subsetted WOFF2 fonts. According to Elena, we can get 5.3% improvement on compression and 39% improvement on compression speed when removing 10% of the content, and 3.2% better compression rates and 26% faster compression, when removing 50% of the content.
Brotli compression is getting better, so if you can bypass the cost of dynamically compressing static assets, it’s definitely worth the effort. It goes without saying that Brotli can be used for any plaintext payload — HTML, CSS, SVG, JavaScript, JSON, and so on.
Note: as of early 2021, approximately 60% of HTTP responses are delivered with no text-based compression, with 30.82% compressing with Gzip, and 9.1% compressing with Brotli (both on mobile and on desktop). E.g., 23.4% of Angular pages are not compressed (via gzip or Brotli). Yet often turning on compression is one of the easiest wins to improve performance with a simple flip of a switch.
The strategy? Pre-compress static assets with Brotli+Gzip at the highest level and compress (dynamic) HTML on the fly with Brotli at level 4–6. Make sure that the server handles content negotiation for Brotli or Gzip properly.
- Do we use adaptive media loading and client hints?
It’s coming from the land of old news, but it’s always a good reminder to use responsive images withsrcset,sizesand theThe future of responsive images might change dramatically with the wider adoption of client hints. Client hints are HTTP request header fields, e.g.
DPR,Viewport-Width,Width,Save-Data,Accept(to specify image format preferences) and others. They are supposed to inform the server about the specifics of user’s browser, screen, connection etc.As a result, the server can decide how to fill in the layout with appropriately sized images, and serve only these images in desired formats. With client hints, we move the resource selection from HTML markup and into the request-response negotiation between the client and server.
As Ilya Grigorik noted a while back, client hints complete the picture — they aren’t an alternative to responsive images.”The
A service worker could, for example, append new client hints headers values to the request, rewrite the URL and point the image request to a CDN, adapt response based on connectivity and user preferences, etc. It holds true not only for image assets but for pretty much all other requests as well.
For clients that support client hints, one could measure 42% byte savings on images and 1MB+ fewer bytes for 70th+ percentile. On Smashing Magazine, we could measure 19-32% improvement, too. Client hints are supported in Chromium-based browsers, but they are still under consideration in Firefox.
However, if you supply both the normal responsive images markup and the
tag for Client Hints, then a supporting browser will evaluate the responsive images markup and request the appropriate image source using the Client Hints HTTP headers. - Do we use responsive images for background images?
We surely should! Withimage-set, now supported in Safari 14 and in most modern browsers except Firefox, we can serve responsive background images as well:background-image: url("fallback.jpg"); background-image: image-set("photo-small.jpg"1x, "photo-large.jpg"2x, "photo-print.jpg"600dpi);Basically we can conditionally serve low-resolution background images with a
1xdescriptor, and higher-resolution images with2xdescriptor, and even a print-quality image with600dpidescriptor. Beware though: browsers do not provide any special information on background images to assistive technology, so ideally these photos would be merely decoration. - Do we use WebP?
Image compression is often considered a quick win, yet it’s still heavily underutilized in practice. Of course images do not block rendering, but they contribute heavily to poor LCP scores, and very often they are just too heavy and too large for the device they are being consumed on.So at the very least, we could explore using the WebP format for our images. In fact, the WebP saga has been nearing the end last year with Apple adding support for WebP in Safari 14. So after many years of discussions and debates, as of today, WebP is supported in all modern browsers. So we can serve WebP images with the
Acceptheaders).WebP isn’t without its downsides though. While WebP image file sizes compared to equivalent Guetzli and Zopfli, the format doesn’t support progressive rendering like JPEG, which is why users might see the finished image faster with a good ol’JPEG although WebP images might be getting faster through the network. With JPEG, we can serve a”decent”user experience with the half or even quarter of the data and load the rest later, rather than have a half-empty image as it is in the case of WebP.
Your decision will depend on what you are after: with WebP, you’ll reduce the payload, and with JPEG you’ll improve perceived performance. You can learn more about WebP in WebP Rewind talk by Google’s Pascal Massimino.
For conversion to WebP, you can use WebP Converter, cwebp or libwebp. Ire Aderinokun has a very detailed tutorial on converting images to WebP, too — and so does Josh Comeau in his piece on embracing modern image formats.

Sketch natively supports WebP, and WebP images can be exported from Photoshop using a WebP plugin for Photoshop. But other options are available, too.
If you’re using WordPress or Joomla, there are extensions to help you easily implement support for WebP, such as Optimus and Cache Enabler for WordPress and Joomla’s own supported extension (via Cody Arsenault). You can also abstract away the
Ah — shameless plug! — Jeremy Wagner even published a Smashing book on WebP which you might want to check if you are interested about everything around WebP.
- Do we use AVIF?
You might have heard the big news: AVIF has landed. It’s a new image format derived from the keyframes of AV1 video. It’s an open, royalty-free format that supports lossy and lossless compression, animation, lossy alpha channel and can handle sharp lines and solid colors (which was an issue with JPEG), while providing better results at both.In fact, compared to WebP and JPEG, AVIF performs significantly better, yielding median file size savings for up to 50% at the same DSSIM ((dis)similarity between two or more images using an algorithm approximating human vision). In fact, in his thorough post on optimizing image loading, Malte Ubl notes that AVIF”very consistently outperforms JPEG in a very significant way. This is different from WebP which doesn’t always produce smaller images than JPEG and may actually be a net-loss due to lack of support for progressive loading.”

Ironically, AVIF can perform even better than large SVGs although of course it shouldn’t be seen as a replacement to SVGs. It is also one of the first image formats to support HDR color support; offering higher brightness, color bit depth, and color gamuts. The only downside is that currently AVIF doesn’t support progressive image decoding (yet?) and, similarly to Brotli, a high compression rate encoding is currently quite slow, although decoding is fast.
AVIF is currently supported in Chrome, Firefox and Opera, and the support in Safari expected to be coming soon (as Apple is a member of the group that created AV1).
What’s the best way to serve images these days then? For illustrations and vector images, (compressed) SVG is undoubtedly the best choice. For photos, we use content negotiation methods with the
pictureelement. If AVIF is supported, we send an AVIF image; if it’s not the case, we fall back to WebP first, and if WebP isn’t supported either, we switch to JPEG or PNG as fallback (applying@mediaconditions if needed):
Frankly, it’s more likely that we’ll be using some conditions within the
pictureelement though:
You can go even further by swapping animated images with static images for customers who opt-in for less motion with
prefers-reduced-motion:
Over the couple of months, AVIF has gained quite some traction:
- We can test WebP/AVIF fallbacks in the Rendering panel in DevTools.
- We can use Squoosh, AVIF.io and libavif to encode, decode, compress and convert AVIF files.
- We can use Jake Archibald’s AVIF Preact component that decodes an AVIF-file in a worker and displays the result on a canvas,
- To deliver AVIF only to supporting browsers, we can use a PostCSS plugin along with a 315B-script to use AVIF in your CSS declarations.
- We can progressively deliver new image formats with CSS and Cloudlare Workers to dynamically alter the returned HTML document, inferring information from the
acceptheader, and then add thewebp/avifetc. classes as appropriate. - AVIF is already available in Cloudinary (with usage limits), Cloudflare supports AVIF in Image Resizing, and you can enabled AVIF with Custom AVIF Headers in Netlify.
- When it comes to animation, AVIF performs as well as Safari’s
- In general, for animations, AVC1 (h264) > HVC1 > WebP > AVIF > GIF, assuming that Chromium-based browsers will ever support
- You can find more details about AVIF in AVIF for Next Generation Image Coding talk by Aditya Mavlankar from Netflix, and The AVIF Image Format talk by Cloudflare’s Kornel Lesiński.
- A great reference for everything AVIF: Jake Archibald’s comprehensive post on AVIF has landed.
So is the future AVIF then? Jon Sneyers disagrees: AVIF performs 60% worse than JPEG XL, another free and open format developed by Google and Cloudinary. In fact, JPEG XL seems to be performing way better across the board. However, JPEG XL is still only in the final stages of standardization, and does not yet work in any browser. (Not to mix up with Microsoft’s JPEG-XR coming from good ol’Internet Explorer 9 times).


 The Responsive Image Breakpoints Generator automates images and markup generation.
The Responsive Image Breakpoints Generator automates images and markup generation.
- Are JPEG/PNG/SVGs properly optimized?
When you’re working on a landing page on which it’s critical that a hero image loads blazingly fast, make sure that JPEGs are progressive and compressed with mozJPEG (which improves the start rendering time by manipulating scan levels) or Guetzli, Google’s open-source encoder focusing on perceptual performance, and utilizing learnings from Zopfli and WebP. The only downside: slow processing times (a minute of CPU per megapixel).For PNG, we can use Pingo, and for SVG, we can use SVGO or SVGOMG. And if you need to quickly preview and copy or download all the SVG assets from a website, svg-grabber can do that for you, too.
Every single image optimization article would state it, but keeping vector assets clean and tight is always worth mentioning. Make sure to clean up unused assets, remove unnecessary metadata and reduce the number of path points in artwork (and thus SVG code). (Thanks, Jeremy!)
There are also useful online tools available though:
- Use Squoosh to compress, resize and manipulate images at the optimal compression levels (lossy or lossless),
- Use Guetzli.it to compress and optimize JPEG images with Guetzli, which works well for images with sharp edges and solid colors (but might be quite a bit slower)).
- Use the Responsive Image Breakpoints Generator or a service such as Cloudinary or Imgix to automate image optimization. Also, in many cases, using
srcsetandsizesalone will reap significant benefits. - To check the efficiency of your responsive markup, you can use imaging-heap, a command line tool that measure the efficiency across viewport sizes and device pixel ratios.
- You can add automatic image compression to your GitHub workflows, so no image can hit production uncompressed. The action uses mozjpeg and libvips that work with PNGs and JPGs.
- To optimize storage interally, you could use Dropbox’s new Lepton format for losslessly compressing JPEGs by an average of 22%.
- Use BlurHash if you’d like to show a placeholder image early. BlurHash takes an image, and gives you a short string (only 20-30 characters!) that represents the placeholder for this image. The string is short enough that it can easily be added as a field in a JSON object.
Sometimes optimizing images alone won’t do the trick. To improve the time needed to start the rendering of a critical image, lazy-load less important images and defer any scripts to load after critical images have already rendered. The most bulletproof way is hybrid lazy-loading, when we utilize native lazy-loading and lazyload, a library that detects any visibility changes triggered through user interaction (with IntersectionObserver which we’ll explore later). Additionally:
- Consider preloading critical images, so a browser doesn’t discover them too late. For background images, if you want to be even more aggressive than that, you can add the image as a regular image with
- Consider Swapping Images with the Sizes Attribute by specifying different image display dimensions depending on media queries, e.g. to manipulate
sizesto swap sources in a magnifier component. - Review image download inconsistencies to prevent unexpected downloads for foreground and background images. Watch out for images that are loaded by default, but might never be displayed — e.g. in carousels, accordions and image galleries.
- Make sure to always set
widthandheighton images. Watch out for theaspect-ratioproperty in CSS andintrinsicsizeattribute which will allow us to set aspect ratios and dimensions for images, so browser can reserve a pre-defined layout slot early to avoid layout jumps during the page load.

If you feel adventurous, you could chop and rearrange HTTP/2 streams using Edge workers, basically a real-time filter living on the CDN, to send images faster through the network. Edge workers use JavaScript streams that use chunks which you can control (basically they are JavaScript that runs on the CDN edge that can modify the streaming responses), so you can control the delivery of images.
With a service worker, it’s too late as you can’t control what’s on the wire, but it does work with Edge workers. So you can use them on top of static JPEGs saved progressively for a particular landing page.
Not good enough? Well, you can also improve perceived performance for images with the multiple background images technique. Keep in mind that playing with contrast and blurring out unnecessary details (or removing colors) can reduce file size as well. Ah, you need to enlarge a small photo without losing quality? Consider using Letsenhance.io.
These optimizations so far cover just the basics. Addy Osmani has published a very detailed guide on Essential Image Optimization that goes very deep into details of image compression and color management. For example, you could blur out unnecessary parts of the image (by applying a Gaussian blur filter to them) to reduce the file size, and eventually you might even start removing colors or turn the picture into black and white to reduce the size even further. For background images, exporting photos from Photoshop with 0 to 10% quality can be absolutely acceptable as well.
On Smashing Magazine, we use the postfix
-optfor image names — for example,brotli-compression-opt.png; whenever an image contains that postfix, everybody on the team knows that the image has already been optimized.Ah, and don’t use JPEG-XR on the web —”the processing of decoding JPEG-XRs software-side on the CPU nullifies and even outweighs the potentially positive impact of byte size savings, especially in the context of SPAs”(not to mix up with Cloudinary/Google’s JPEG XL though).

- Are videos properly optimized?
We covered images so far, but we’ve avoided a conversation about good ol’GIFs. Despite our love for GIFs, it’s really the time to abandon them for good (at least in our websites and apps). Instead of loading heavy animated GIFs which impact both rendering performance and bandwidth, it’s a good idea to switch either to animated WebP (with GIF being a fallback) or replace them with looping HTML5 videos altogether.Unlike with images, browsers do not preload
content, but HTML5 videos tend to be much lighter and smaller than GIFs. Not an option? Well, at least we can add lossy compression to GIFs with Lossy GIF, gifsicle or giflossy.Tests by Colin Bendell show that inline videos within
imgtags in Safari Technology Preview display at least 20× faster and decode 7× faster than the GIF equivalent, in addition to being a fraction in file size. However, it’s not supported in other browsers.In the land of good news, video formats have been advancing massively over the years. For a long time, we had hoped that WebM would become the format to rule them all, and WebP (which is basically one still image inside of the WebM video container) will become a replacement for dated image formats. Indeed, Safari is now supporting WebP, but despite WebP and WebM gaining support these days, the breakthrough didn’t really happen.
Still, we could use WebM for most modern browsers out there:
Then we can target specifically browsers that actually support AV1:
We then could re-add the
autoplayover a certain threshold (e.g. 1000px):/ By Doug Sillars. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ /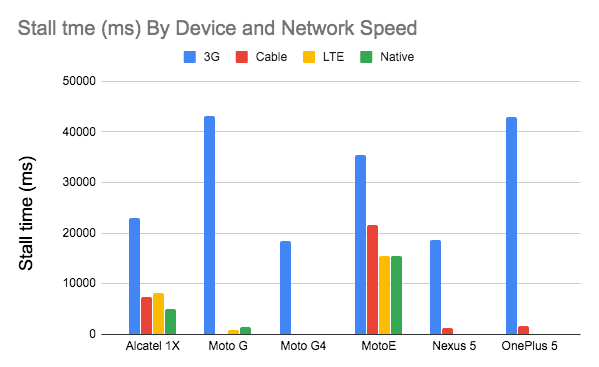
Video playback performance is a story on its own, and if you’d like to dive into it in details, take a look at another Doug Sillars’series on The Current State of Video and Video Delivery Best Practices that include details on video delivery metrics, video preloading, compression and streaming. Finally, you can check how slow or fast your video streaming will be with Stream or Not.
- Is web font delivery optimized?
The first question that’s worth asking is if we can get away with using UI system fonts in the first place — we just need to make sure to double check that they appear correctly on various platforms. If it’s not the case, chances are high that the web fonts we are serving include glyphs and extra features and weights that aren’t being used. We can ask our type foundry to subset web fonts or if we are using open-source fonts, subset them on our own with Glyphhanger or Fontsquirrel. We can even automate our entire workflow with Peter Müller’s subfont, a command line tool that statically analyses your page in order to generate the most optimal web font subsets, and then inject them into our pages.WOFF2 support is great, and we can use WOFF as fallback for browsers that don’t support it — or perhaps legacy browsers could be served system fonts. There are many, many, many options for web font loading, and we can choose one of the strategies from Zach Leatherman’s”Comprehensive Guide to Font-Loading Strategies,”(code snippets also available as Web font loading recipes).
Probably the better options to consider today are Critical FOFT with
preloadand “The Compromise”method. Both of them use a two-stage render for delivering web fonts in steps — first a small supersubset required to render the page fast and accurately with the web font, and then load the rest of the family async. The difference is that”The Compromise”technique loads polyfill asynchronously only if font load events are not supported, so you don’t need to load the polyfill by default. Need a quick win? Zach Leatherman has a quick 23-min tutorial and case study to get your fonts in order.In general, it might be a good idea to use the
preloadresource hint to preload fonts, but in your markup include the hints after the link to critical CSS and JavaScript. Withpreload, there is a puzzle of priorities, so consider injectingrel="preload"elements into the DOM just before the external blocking scripts. According to Andy Davies,”resources injected using a script are hidden from the browser until the script executes, and we can use this behaviour to delay when the browser discovers thepreloadhint.”Otherwise, font loading will cost you in the first render time.
It’s a good idea to be selective and choose files that matter most, e.g. the ones that are critical for rendering or that would help you avoiding visible and disruptive text reflows. In general, Zach advises to preload one or two fonts of each family — it also makes sense to delay some font loading if they are less critical.
It has become quite common to use
local()value (which refers to a local font by name) when defining afont-familyin the@font-facerule:/ Warning! Not a good idea! / @font-face { font-family: Open Sans; src: local('Open Sans Regular'), local('OpenSans-Regular'), url('opensans.woff2') format ('woff2'), url('opensans.woff') format('woff'); }The idea is reasonable: some popular open-source fonts such as Open Sans are coming pre-installed with some drivers or apps, so if the font is available locally, the browser doesn’t need to download the web font and can display the local font immediately. As Bram Stein noted,”though a local font matches the name of a web font, it most likely isn’t the same font. Many web fonts differ from their”desktop”version. The text might be rendered differently, some characters may fall back to other fonts, OpenType features can be missing entirely, or the line height may be different.”
Also, as typefaces evolve over time, the locally installed version might be very different from the web font, with characters looking very different. So, according to Bram, it’s better to never mix locally installed fonts and web fonts in
@font-facerules. Google Fonts has followed suit by disablinglocal()on the CSS results for all users, other than Android requests for Roboto.Nobody likes waiting for the content to be displayed. With the
font-displayCSS descriptor, we can control the font loading behavior and enable content to be readable immediately (withfont-display: optional) or almost immediately (with a timeout of 3s, as long as the font gets successfully downloaded — withfont-display: swap). (Well, it’s a bit more complicated than that.)However, if you want to minimize the impact of text reflows, we could use the Font Loading API (supported in all modern browsers). Specifically that means for every font, we’d creata a
FontFaceobject, then try to fetch them all, and only then apply them to the page. This way, we group all repaints by loading all fonts asynchronously, and then switch from fallback fonts to the web font exactly once. Take a look at Zach’s explanation, starting at 32:15, and the code snippet):/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ //Remove existing @font-face blocks //Create two let font=new FontFace("Noto Serif",/*... */); let fontBold=new FontFace("Noto Serif,/*... */); //Load two fonts let fonts=await Promise.all([ font.load(), fontBold.load() ]) //Group repaints and render both fonts at the same time! fonts.forEach(font=> documents.fonts.add(font));To initiate a very early fetch of the fonts with Font Loading API in use, Adrian Bece suggests to add a non-breaking space
nbsp;at the top of thebody, and hide it visually witharia-visibility: hiddenand a.hiddenclass:This goes along with CSS that has different font families declared for different states of loading, with the change triggered by Font Loading API once the fonts have successfully loaded:
body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; / Fallback font styles / } .wf-merriweather--loaded, .no-js { font-family:"[web-font-name]"; / Webfont styles / } / Accessible hiding / .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); altura: 1px; width: 1px; margin:-1px; padding: 0; border: 0; }If you ever wondered why despite all your optimizations, Lighthouse still suggests to eliminate render-blocking resources (fonts), in the same article Adrian Bece provides a few techniques to make Lighthouse happy, along with a Gatsby Omni Font Loader, a performant asynchronous font loading and Flash Of Unstyled Text (FOUT) handling plugin for Gatsby.
Now, many of us might be using a CDN or a third-party host to load web fonts from. In general, it’s always better to self-host all your static assets if you can, so consider using google-webfonts-helper, a hassle-free way to self-host Google Fonts. And if it’s not possible, you can perhaps proxy the Google Font files through the page origin.
It’s worth noting though that Google is doing quite a bit of work out of the box, so a server might need a bit of tweaking to avoid delays (thanks, Barry!)
This is quite important especially as since Chrome v86 (released October 2020), cross-site resources like fonts can’t be shared on the same CDN anymore — due to the partitioned browser cache. This behavior was a default in Safari for years.
But if it’s not possible at all, there is a way to get to the fastest possible Google Fonts with Harry Roberts’snippet:
https://fonts.gstatic.com" crossorigin/>Harry’s strategy is to pre-emptively warm up the fonts’ origin first. Then we initiate a high-priority, asynchronous fetch for the CSS file. Afterwards, we initiate a low-priority, asynchronous fetch that gets applied to the page only after it’s arrived (with a print stylesheet trick). Finally, if JavaScript isn’t supported, we fall back to the original method.
Ah, talking about Google Fonts: you can shave up to 90% of the size of Google Fonts requests by declaring only characters you need with
&text. Plus, the support for font-display was added recently to Google Fonts as well, so we can use it out of the box.A quick word of caution though. If you use
font-display: optional, it might be suboptimal to also usepreloadas it will trigger that web font request early (causing network congestion if you have other critical path resources that need to be fetched). Usepreconnectfor faster cross-origin font requests, but be cautious withpreloadas preloading fonts from a different origin wlll incur network contention. All of these techniques are covered in Zach’s Web font loading recipes.On the other hand, it might be a good idea to opt out of web fonts (or at least second stage render) if the user has enabled Reduce Motion in accessibility preferences or has opted in for Data Saver Mode (see
Save-Dataheader), or when the user has a slow connectivity (via Network Information API).We can also use the
prefers-reduced-dataCSS media query to not define font declarations if the user has opted into data-saving mode (there are other use-cases, too). The media query would basically expose if theSave-Datarequest header from the Client Hint HTTP extension is on/off to allow for usage with CSS. Currently supported only in Chrome and Edge behind a flag.Metrics? To measure the web font loading performance, consider the All Text Visible metric (the moment when all fonts have loaded and all content is displayed in web fonts), Time to Real Italics as well as Web Font Reflow Count after first render. Obviously, the lower both metrics are, the better the performance is.
What about variable fonts, you might ask? It’s important to notice that variable fonts might require a significant performance consideration. They give us a much broader design space for typographic choices, but it comes at the cost of a single serial request opposed to a number of individual file requests.
While variable fonts drastically reduce the overall combined file size of font files, that single request might be slow, blocking the rendering of all content on a page. So subsetting and splitting the font into character sets still matter. On the good side though, with a variable font in place, we’ll get exactly one reflow by default, so no JavaScript will be required to group repaints.
Now, what would make a bulletproof web font loading strategy then? Subset fonts and prepare them for the 2-stage-render, declare them with a
font-displaydescriptor, use Font Loading API to group repaints and store fonts in a persistent service worker’s cache. On the first visit, inject the preloading of scripts just before the blocking external scripts. You could fall back to Bram Stein’s Font Face Observer if necessary. And if you’re interested in measuring the performance of font loading, Andreas Marschke explores performance tracking with Font API and UserTiming API.Finally, don’t forget to include
unicode-rangeto break down a large font into smaller language-specific fonts, and use Monica Dinculescu’s font-style-matcher to minimize a jarring shift in layout, due to sizing discrepancies between the fallback and the web fonts.Alternatively, to emulate a web font for a fallback font, we can use @font-face descriptors to override font metrics (demo, enabled in Chrome 87). (Note that adjustments are complicated with complicated font stacks though.)
Does the future look bright? With progressive font enrichment, eventually we might be able to”download only the required part of the font on any given page, and for subsequent requests for that font to dynamically ‘patch’ the original download with additional sets of glyphs as required on successive page views”, as Jason Pamental explains it. Incremental Transfer Demo is already available, and it’s work in progress.
Build Optimizations
- Have we defined our priorities?
It’s a good idea to know what you are dealing with first. Run an inventory of all of your assets (JavaScript, images, fonts, third-party scripts and”expensive”modules on the page, such as carousels, complex infographics and multimedia content), and break them down in groups.Set up a spreadsheet. Define the basic core experience for legacy browsers (i.e. fully accessible core content), the enhanced experience for capable browsers (i.e. an enriched, full experience) and the extras (assets that aren’t absolutely required and can be lazy-loaded, such as web fonts, unnecessary styles, carousel scripts, video players, social media widgets, large images). Years ago, we published an article on”Improving Smashing Magazine’s Performance,”which describes this approach in detail.
When optimizing for performance we need to reflect our priorities. Load the core experience immediately, then enhancements, and then the extras.
- Do you use native JavaScript modules in production?
Remember the good ol’cutting-the-mustard technique to send the core experience to legacy browsers and an enhanced experience to modern browsers? An updated variant of the technique could use ES2017+
In a fantastic post on "Reducing the Site-Speed Impact of Third-Party Tags", Andy Davies explores a strategy of minimizing the footprint of third-parties — from identifying their costs towards reducing their impact.
According to Andy, there are two ways tags impact site-speed — they compete for network bandwidth and processing time on visitors’ devices, and depending on how they’re implemented, they can delay HTML parsing as well. So the first step is to identify the impact that third-parties have, by testing the site with and without scripts using WebPageTest. With Simon Hearne’s Request Map, we can also visualize third-parties on a page along with details on their size, type and what triggered their load.
Preferably self-host and use a single hostname, but also use a request map to exposes fourth-party calls and detect when the scripts change. You can use Harry Roberts'approach for auditing third parties and produce spreadsheets like this one (also check Harry's auditing workflow).
Afterwards, we can explore lightweight alternatives to existing scripts and slowly replace duplicates and main culprits with lighter options. Perhaps some of the scripts could be replaced with their fallback tracking pixel instead of the full tag.
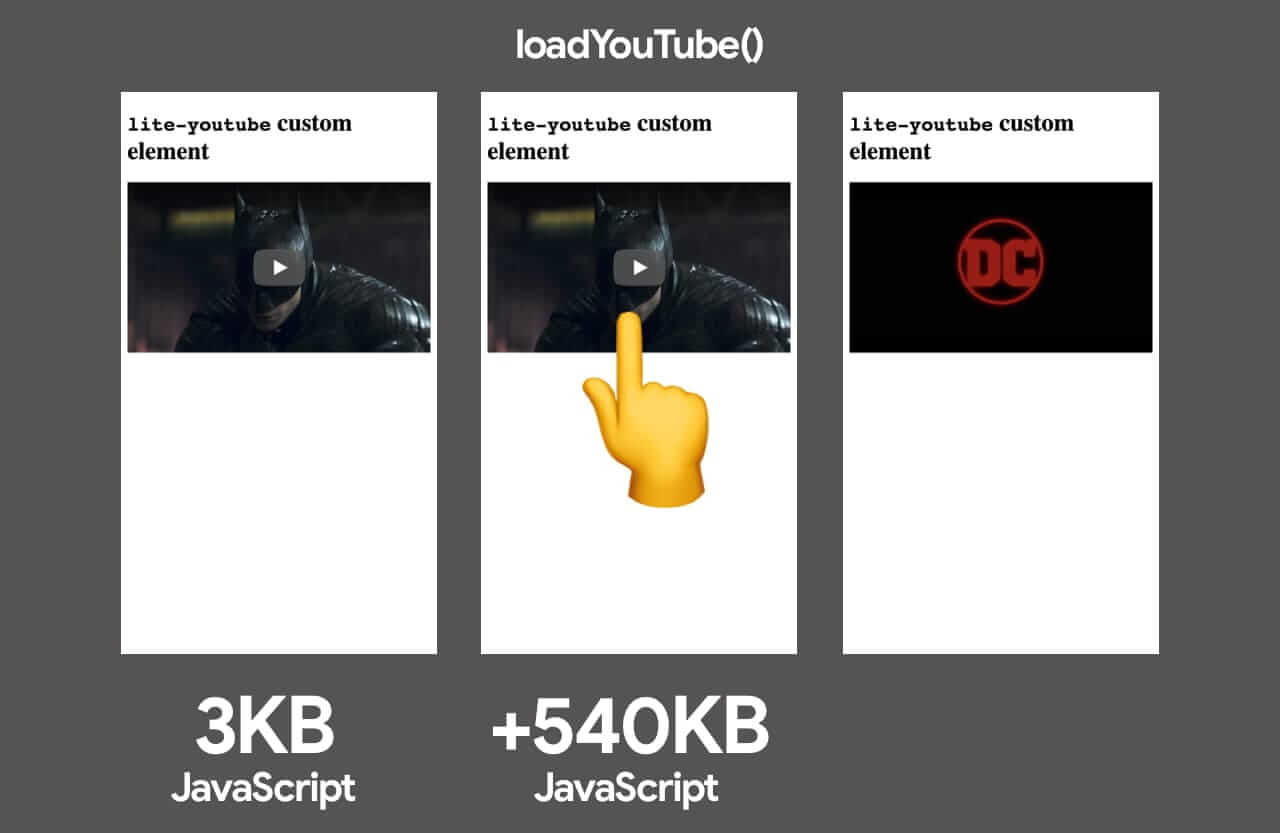
If it’s not viable, we can at least lazy load third-party resources with facades, i.e. a static element which looks similar to the actual embedded third-party, but is not functional and therefore much less taxing on the page load. The trick, then, is to load the actual embed only on interaction.
For example, we can use:
- lite-vimeo-embed for the Vimeo player,
- lite-vimeo for the Vimeo player,
- lite-youtube-embed for the YouTube player,
- react-live-chat-loader for a live chat (case study, and another case-study),
- lazyframe for iframes.
One of the reasons why tag managers are usually large in size is because of the many simultaneous experiments that are running at the same time, along with many user segments, page URLs, sites etc., so according to Andy, reducing them can reduce both the download size and the time it takes to execute the script in the browser.
And then there are anti-flicker snippets. Third-parties such as Google Optimize, Visual Web Optimizer (VWO) and others are unanimous in using them. These snippets are usually injected along with running A/B tests: to avoid flickering between the different test scenarios, they hide the body of the document with opacity: 0, then adds a function that gets called after a few seconds to bring the opacity back. This often results in massive delays in rendering due to massive client-side execution costs.
Therefore keep track how often the anti-flicker timeout is triggered and reduce the timeout. Default blocks display of your page by up to 4s which will ruin conversion rates. According to Tim Kadlec,"Friends don’t let friends do client side A/B testing". Server-side A/B testing on CDNs (e.g. Edge Computing, or Edge Slice Rerendering) is always a more performant option.
If you have to deal with almighty Google Tag Manager, Barry Pollard provides some guidelines to contain the impact of Google Tag Manager. Also, Christian Schaefer explores strategies for loading ads.
Watch out: some third-party widgets hide themselves from auditing tools, so they might be more difficult to spot and measure. To stress-test third parties, examine bottom-up summaries in Performance profile page in DevTools, test what happens if a request is blocked or it has timed out — for the latter, you can use WebPageTest’s Blackhole server blackhole.webpagetest.org that you can point specific domains to in your hosts file.
What options do we have then? Consider using service workers by racing the resource download with a timeout and if the resource hasn’t responded within a certain timeout, return an empty response to tell the browser to carry on with parsing of the page. You can also log or block third-party requests that aren’t successful or don’t fulfill certain criteria. If you can, load the 3rd-party-script from your own server rather than from the vendor’s server and lazy load them.
Another option is to establish a Content Security Policy (CSP) to restrict the impact of third-party scripts, e.g. disallowing the download of audio or video. The best option is to embed scripts via