Em termos simples, o Hive é uma ferramenta de infraestrutura de data warehouse usada para processar dados estruturados no Hadoop. Mas é isso? Há muito mais quando se trata de Hive, e nesta lição você terá uma visão geral dos recursos de particionamento do HIVE, que são usados para melhorar o desempenho de Consultas SQL . Você também aprenderá sobre a linguagem de consulta do Hive e como ela pode ser estendida para melhorar o desempenho da consulta e muito mais. Não apenas isso, ao final desta lição, você será capaz de:
- Melhore o desempenho da consulta com os conceitos de particionamento de arquivo de dados no hive
- Definir linguagem de consulta HIVE ou HIVEQL
- Descreva maneiras em que HIVEQL pode ser estendido
Vamos começar com o armazenamento de dados em um único Hadoop Distributed File System.
Armazenamento de dados em um único sistema de arquivos distribuídos Hadoop
HIVE é considerada uma ferramenta preferida para realizar consultas em grandes conjuntos de dados, especialmente aqueles que requerem varreduras completas da tabela. HIVE tem recursos avançados de particionamento.
O particionamento de arquivos de dados no hive é muito útil para eliminar dados durante a consulta, a fim de reduzir o tempo da consulta. Existem muitos casos em que os usuários precisam filtrar os dados em valores de coluna específicos.
- Usando o recurso de particionamento do HIVE que subdivide os dados, os usuários do HIVE podem identificar as colunas, que podem ser usadas para organizar os dados.
- Usando o particionamento, a análise pode ser feita apenas no subconjunto de dados relevante, resultando em um desempenho altamente aprimorado das consultas HIVE.
No caso de tabelas particionadas, subdiretórios são criados no diretório de dados da tabela para cada valor único de uma coluna de partição. Você aprenderá mais sobre os recursos de particionamento nas seções subsequentes. O diagrama a seguir explica o armazenamento de dados em um único Hadoop Distributed File System ou diretório HDFS.

Vamos começar com um exemplo de uma tabela não particionada.
Programa mestre de engenheiro de Big Data
Domine toda a habilidade de Big Data de que você precisa hoje Inscreva-se agora
Exemplo de uma tabela não particionada
Em tabelas não particionadas, por padrão, todas as consultas devem examinar todos os arquivos no diretório. Isso significa que o HIVE precisará ler todos os arquivos no diretório de dados de uma tabela. Este pode ser um processo muito lento e caro, especialmente quando as tabelas são grandes. No exemplo abaixo, você pode ver que há uma coluna State criada no HIVE.
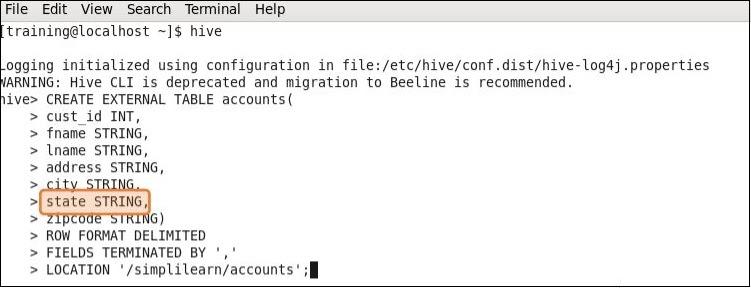
O requisito é convertê-la em uma partição de estado para que tabelas separadas sejam criadas para estados separados. Os detalhes do cliente devem ser particionados por estado para recuperação rápida dos dados do subconjunto pertencentes à categoria do cliente. Lembre-se de que você também pode realizar as mesmas consultas no Impala.
Na próxima seção, você verá um exemplo de como essa tabela é particionada por estado, de forma que uma varredura completa de toda a tabela não seja necessária.
Exemplo de uma tabela particionada
Aqui está um exemplo de uma tabela particionada. Este exemplo mostra como a tabela anteriormente não particionada agora está particionada.
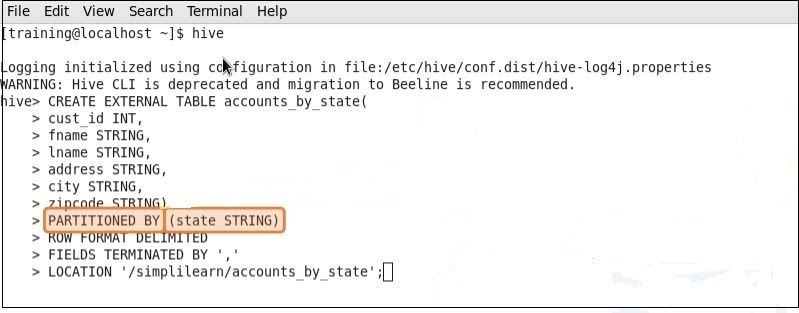
Você pode ver que a coluna de estado não está mais incluída na definição da tabela Criar, mas está incluída na definição da partição. As partições são, na verdade, fatias horizontais de dados que permitem que conjuntos maiores de dados sejam separados em blocos mais gerenciáveis. Basicamente, isso significa que você pode usar o particionamento no hive para armazenar dados em arquivos separados por estado, conforme mostrado no exemplo.
No momento da criação da tabela, as partições são definidas usando a cláusula PARTITIONED BY, com uma lista de definições de coluna para particionamento. Uma coluna de partição é uma “coluna virtual, onde os dados não são realmente armazenados no arquivo.
Na próxima seção, vamos entender como você pode inserir dados em tabelas particionadas usando particionamento dinâmico e estático no hive.
Particionamento dinâmico e estático na colmeia
A inserção de dados em tabelas particionadas pode ser feita de duas maneiras ou modos: Particionamento estático Particionamento dinâmico
Você aprenderá mais sobre esses conceitos nas seções subsequentes. Vamos começar com o particionamento estático.
Particionamento estático no Hive
No modo de particionamento estático, você pode inserir ou inserir os arquivos de dados individualmente em uma tabela de partição. Você pode criar novas partições conforme necessário e definir as novas partições usando a cláusula ADD PARTITION.
Ao carregar dados, você precisa especificar em qual partição armazenar os dados. Isso significa que, a cada carregamento, você precisa especificar o valor da coluna da partição. Você pode adicionar uma partição na tabela e mover o arquivo de dados para a partição da tabela.
Como você pode ver no exemplo abaixo, você pode adicionar uma partição para cada novo dia de dados da conta.

Particionamento dinâmico no Hive
Com o particionamento dinâmico no hive, as partições são criadas automaticamente durante o carregamento. Novas partições podem ser criadas dinamicamente a partir de dados existentes.
As partições são criadas automaticamente com base no valor da última coluna. Se a partição ainda não existir, ela será criada. Caso a partição exista, ela será substituída pela palavra-chave OVERWRITE conforme mostrado no exemplo abaixo.

Como você pode ver no exemplo, uma partição está sendo substituída. Quando você tem uma grande quantidade de dados armazenados em uma tabela, a partição dinâmica é adequada. Observe que, por padrão, o particionamento dinâmico é desabilitado no HIVE para evitar a criação acidental de partição.
Ative as seguintes configurações para usar o particionamento dinâmico:
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict ;.
Vamos dar uma olhada em alguns comandos compatíveis com tabelas particionadas do Hive, que permitem visualizar e excluir partições.
Visualizando e Excluindo Partições
Você pode ver as partições de uma tabela particionada usando o comando SHOW, conforme ilustrado na imagem.

Para excluir as partições soltas, use o comando ALTER, conforme mostrado na imagem.
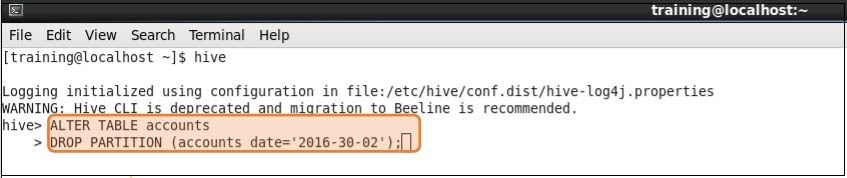
Usando o comando ALTER, você também pode adicionar ou alterar partições.
Quando usar o particionamento? Aqui estão alguns casos em que você usa o particionamento para tabelas:
- Ler todo o conjunto de dados demora muito.
- As consultas quase sempre são filtradas nas colunas de partição.
- Há um número razoável de valores diferentes para colunas de partição.
Aqui estão alguns casos em que você deve evitar o uso de particionamento:
- Evite a partição em colunas com muitas linhas exclusivas.
- Seja cauteloso ao criar uma partição dinâmica, pois isso pode levar a um grande número de partições.
- Tente limitar a partição para menos de 20k.
Vamos agora entender o que é bucketing em HIVE.
Bucketing no Hive
Você viu que o particionamento dá resultados ao segregar os dados da tabela HIVE em vários arquivos apenas quando há um número limitado de partições. No entanto, pode haver casos em que o particionamento das tabelas resulta em um grande número de partições. É aqui que entra o conceito de bucketing. Bucketing é uma técnica de otimização semelhante ao particionamento. Você pode usar bucketing se precisar executar consultas em colunas que possuem dados enormes, o que torna difícil criar partições. A técnica de otimização de Bucketing no Hive pode ser mostrada no diagrama a seguir.
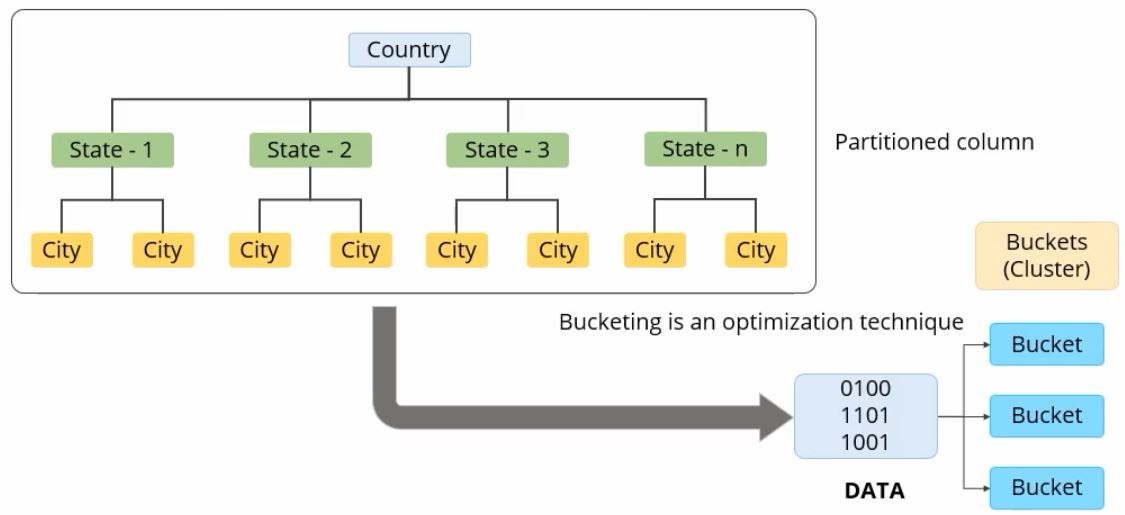
O que os intervalos fazem?
Eles distribuem a carga de dados em um conjunto de clusters definido pelo usuário, calculando o código hash da chave mencionada na consulta. Aqui está uma sintaxe para criar uma tabela de distribuição.
CRIAR TABELA page_views (user_id INT, session_id BIGINT, url
STRING)
PARTICIONADO POR (dia INT)
CLUSTERED BY (user_id) INTO 100;
De acordo com a sintaxe, os dados seriam classificados de acordo com o número de hash do ID de sublinhado do usuário em 100 depósitos. O processador calculará primeiro o número de hash do ID de sublinhado do usuário na consulta e procurará apenas por esse intervalo.
Na próxima seção, vamos examinar o conceito de HIVE Query Language ou HIVEQL, o importante princípio do HIVE chamado extensibilidade, e as maneiras pelas quais HIVEQL pode ser estendido.
Linguagem de consulta do Hive-Introdução
É a linguagem de consulta semelhante a SQL para o HIVE processar e analisar dados estruturados em um Metastore. Abaixo está um exemplo de consulta HIVEQL.
SELECIONE
dt,
COUNT (DISTINCT (user_id))
Eventos FROM
GROUP BY dt;
Um princípio importante do HIVEQL é a extensibilidade.
HIVEQL pode ser estendido de várias maneiras:
- Funções plugáveis definidas pelo usuário
- Scripts MapReduce plugáveis
- Tipos plugáveis definidos pelo usuário
- Formatos de dados plugáveis
Você aprenderá mais sobre funções definidas pelo usuário e scripts MapReduce nas seções subsequentes. Tipos e formatos de dados definidos pelo usuário estão fora do escopo da lição.
Vamos começar com a função definida pelo usuário ou UDF.

Função definida pelo usuário (UDF)
HIVE tem a capacidade de definir uma função.
- UDFs fornecem uma maneira de estender a funcionalidade do HIVE com uma função, escrita em Java que pode ser avaliado em instruções HIVEQL. Todos os UFDs estendem a classe HIVE UDF.
- Uma subclasse UDF precisa implementar um ou mais métodos chamados avaliados, que serão chamados pelo HIVE. Avaliar nunca deve ser um método vazio. No entanto, ele pode retornar nulo, se necessário.
Hive UDF Exemplo 1
Para converter qualquer valor em Celsius:

Hive UDF Exemplo 2
Para converter qualquer string em código hash:
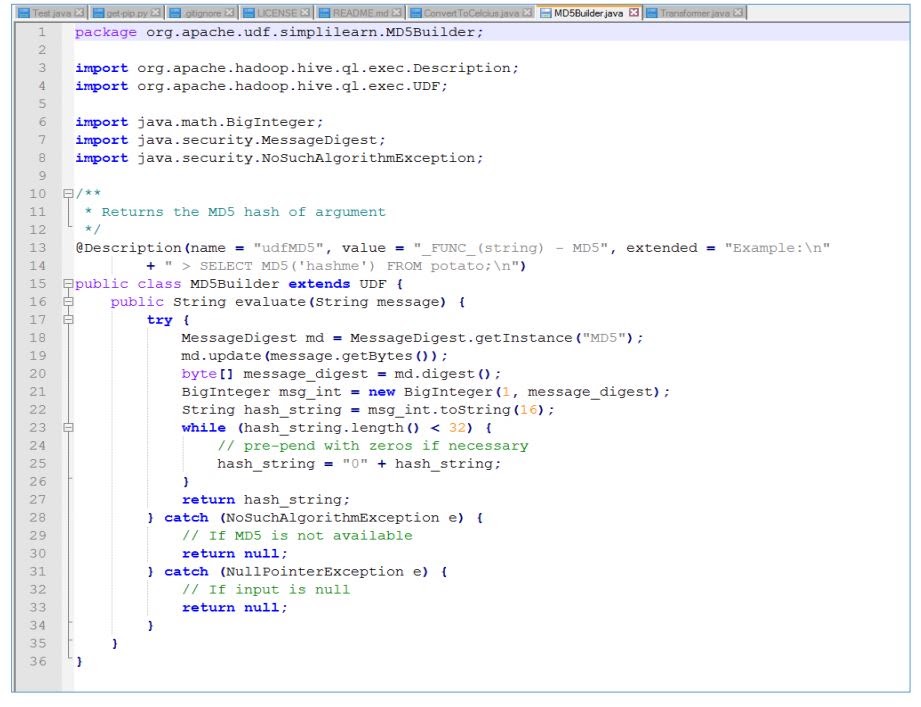
Aqui, um código hash é um número gerado a partir de qualquer objeto. Ele permite que os objetos sejam armazenados/recuperados rapidamente em uma tabela hash.
Hive UDF Exemplo 3
Para transformar o banco de dados já criado pelo método de substituição quando você precisar inserir uma nova coluna:

Agora, vamos entender um código para estender a função definida pelo usuário.
Código para estender UDF
Aqui está um código que você pode usar para estender a função definida pelo usuário.
pacote com.example.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
classe final pública Lower estende UDF {
Avaliação do texto público (Texto final) {
if (s==null) {return null; }
retornar novo Texto (s.toString (). toLowerCase ());
}
}
Códigos de função definidos pelo usuário
Depois de compilar o UDF, você deve incluí-lo no classpath HIVE. Aqui está um código que você pode usar para registrar a classe.
CRIAR FUNÇÃO my_lower AS ‘com.example.hive.udf.Lower’;
Uma vez iniciado o HIVE, você pode usar a função recém-definida em uma instrução de consulta após registrá-los. Este é um código para usar a função em uma instrução de consulta HIVE.
SELECT my_lower (title), sum (freq) FROM títulos GROUP BY my_lower (title);
Escrever as funções em JavaScript cria seu próprio UDF. O HIVE também fornece algumas funções integradas que podem ser usadas para evitar que os próprios UDFs sejam criados.
Funções integradas do Hive
Escrever as funções em scripts JAVA cria seu próprio UDF. O Hive também fornece algumas funções integradas que podem ser usadas para evitar que os próprios UDFs sejam criados.
Isso inclui Matemática, Coleção, Conversão de tipo, Data, Condicional e Sequência. Vejamos os exemplos fornecidos para cada função integrada.
- Matemática: para operações matemáticas, você pode usar os exemplos de redondo, chão e assim por diante.
- Coleção: para coleções, você pode usar tamanho, chaves de mapa e assim por diante.
- Conversão de tipo: para conversões de tipo de dados, você pode usar um elenco.
- Data: para datas, use as seguintes APIs, como ano, data-base e assim por diante.
- Condicional: para funções condicionais, use if, case e coalescence.
- String: para arquivos de string, use length, reverse e assim por diante.
Vejamos algumas outras funções no HIVE, como a função de agregação e a função de geração de tabela.
Funções de agregação
As funções de agregação criam a saída se o conjunto completo de dados for fornecido. A implementação dessas funções é complexa em comparação com a do UDF. O usuário deve implementar mais alguns métodos, no entanto, o formato é semelhante ao UDF.
Portanto, o HIVE fornece muitas funções agregadas definidas pelo usuário ou UDAF integradas.

Funções de geração de tabela
Funções normais definidas pelo usuário, nomeadamente concat, obtêm uma única linha de entrada e fornecem uma única linha de saída. Em contraste, as funções de geração de tabela transformam uma única linha de entrada em várias linhas de saída. Considere a tabela base denominada pageAds. Ele contém duas colunas: pageid, que é o nome da página, e adid underscore list, que é uma matriz de anúncios que aparecem na página.
Aqui é mostrada uma vista lateral usada em conjunto com as funções de geração de tabelas.

Um script SQL na visualização lateral é:
SELECIONE pageid, adid FROM pageAds
LATERAL VIEW explodir (adid_list) adTable
AS adid;
Uma visão lateral com explosão pode ser usada para converter a lista de sublinhados adid em linhas separadas usando a consulta fornecida.

Vamos dar uma olhada nos scripts MapReduce que ajudam a estender o HIVEQL.
Scripts MapReduce
Os scripts do MapReduce são escritos em linguagens de script, como Python . Os usuários podem conectar seus próprios mapeadores e redutores customizados no fluxo de dados. Para executar um script de mapeador customizado e um script de redutor, o usuário pode emitir um comando que usa a cláusula TRANSFORM para incorporar o mapeador e os scripts de redutor. Observe o script mostrado abaixo.
Exemplo: my_append.py
SELECIONE TRANSFORMAR (foo, bar) USANDO’python./my_append.py’DA amostra;
Para linha em sys.stdin:
line=line.strip ()
key=line.split (‘\ t’) [0]
value=line.split (‘\ t’) [1]
imprimir tecla + str (i) +’\ t’+ valor + str (i)
i=i + 1
Aqui, os pares de valores-chave serão transformados em STRING e delimitados por TAB antes de alimentar o script do usuário por padrão.
O método strip retorna uma cópia de todas as palavras nas quais os caracteres de espaço em branco foram retirados do início e do final da palavra. O método split retorna uma lista de todas as palavras usando TAB como separador.
Vamos comparar as funções de agregação definidas pelo usuário e as definidas pelo usuário com os scripts MapReduce.
Curso de desenvolvedor de Big Data Hadoop e Spark (GRATUITO)
Aprenda noções básicas de Big Data com os principais especialistas-GRATUITAMENTE Inscreva-se agora
UDF/UADF versus scripts MapReduce
Uma comparação das funções de agregação definidas pelo usuário e definidas pelo usuário com scripts MapReduce é mostrada na tabela fornecida abaixo.
|
Atributo |
UDF/UDAF |
Scripts MapReduce |
|
Língua |
Java |
Qualquer idioma |
|
1/1 entrada/saída |
Suportado via UDF |
Compatível |
|
n/1 entrada/saída |
Suportado via UDAF |
Compatível |
|
1/n entrada/saída |
Compatível com UDTF |
Compatível |
|
Velocidade |
Mais rápido (no mesmo processo) |
Mais lento (gera novo processo) |
Resumo
Aqui está o que aprendemos até agora:
- As partições são, na verdade, fatias horizontais de dados que permitem que conjuntos maiores de dados sejam separados em blocos mais gerenciáveis.
- No modo de particionamento estático, você pode inserir ou inserir os arquivos de dados individualmente em uma tabela de partição.
- Quando você tem uma grande quantidade de dados armazenados em uma tabela, a partição dinâmica é adequada.
- Use o comando SHOW para ver as partições.
- Para excluir ou adicionar partições, use o comando ALTER.
- Usar particionamento quando a leitura de todo o conjunto de dados demorar muito, as consultas quase sempre são filtradas nas colunas da partição e há um número razoável de valores diferentes para as colunas da partição.
- HIVEQL é uma linguagem de consulta para HIVE para processar e analisar dados estruturados em um Metastore.
- HIVEQL pode ser estendido com a ajuda de funções definidas pelo usuário, scripts MapReduce, tipos definidos pelo usuário e formatos de dados.
Ansioso para se tornar um desenvolvedor Hadoop? Confira a Certificação de Big Data Hadoop Curso de treinamento e obtenha a certificação hoje.
Conclusão
Domine o hive e outros conceitos e ferramentas essenciais de Big Data com o Treinamento de certificação em Big Data Hadoop e amplie sua carreira a partir de hoje!
