Elasticsearch é um mecanismo de pesquisa e análise de código aberto distribuído baseado em Apache Lucene . Ao contrário dos bancos de dados SQL e NoSQL típicos, cujo objetivo principal é armazenar dados, o Elasticsearch armazena e indexa dados para que possam ser pesquisados e analisados rapidamente. Ele também se integra com Logstash (um pipeline de processamento de dados que pode receber dados de várias fontes como logs e bancos de dados) e Kibana (para visualização de dados) e, juntos, eles compõem a pilha ELK.
Neste tutorial, exploraremos como combinar os poderes de Elasticsearch e Golang. Vamos construir um sistema básico de gerenciamento de conteúdo com a capacidade de criar, ler, atualizar e excluir postagens, bem como a capacidade de pesquisar as postagens por meio do Elasticsearch.
Requisitos
Para acompanhar o projeto de amostra neste tutorial, você precisará:
- Go (versão>=1.14) instalado em sua máquina
- Docker e docker-compose instalado
- Alguma familiaridade com o Docker e a linguagem de programação Go
Primeiros passos
Crie um novo diretório no local de sua preferência para hospedar o projeto (estou chamando o meu de letterpress ) e inicialize um novo módulo Go com os comandos abaixo:
$ mkdir letterpress && cd letterpress $ go mod init gitlab.com/idoko/letterpress
As dependências do aplicativo são compostas por:
- lib/pq -Um driver PostgreSQL para Go que é compatível com o pacote database/sql na biblioteca padrão Go
- elastic/go-elasticsearch -O cliente oficial Elasticsearch para Golang
- gin-gonic/gin -A estrutura HTTP que usaremos para REST de nosso aplicativo API
- rs/zerolog -Um registrador leve
Instale as dependências executando o seguinte comando em seu terminal:
$ go get github.com/lib/pq github.com/elastic/go-elasticsearch github.com/gin-gonic/gin github.com/rs/zerolog
Em seguida, crie as pastas e arquivos necessários no diretório do projeto para corresponder à estrutura abaixo:
├── cmd │ ├── api │ │ └── main.go ├── db │ ├── database.go │ └── posts.go ├──.env ├── manipulador ├── logstash │ ├── configuração │ ├── pipelines │ └── consultas └── modelos └── post.go
-
cmd-Aqui é onde ficam os binários do aplicativo (ou seja, arquivosmain.go). Também adicionamos uma subpastaapiinterna para permitir vários binários que não seriam possíveis de outra forma -
db-O pacotedbatua como uma ponte entre nosso aplicativo e o banco de dados. Também o usaremos mais tarde para armazenar os arquivos de migração do banco de dados -
.env-Contém um mapeamento de “valor-chave” de nossas variáveis de ambiente (por exemplo, as credenciais do banco de dados) -
handler-O pacotehandlerinclui os manipuladores de rota de API desenvolvidos pela estrutura gin -
logstash-Aqui é onde mantemos o código relacionado ao logstash, como configurações de pipeline e oDockerfile -
modelos-os modelos são estruturas Golang que podem ser empacotadas nos objetos JSON apropriados
que o acompanha
Abra o arquivo .env no diretório raiz do projeto e configure as variáveis de ambiente assim:
POSTGRES_USER=impressão tipográfica POSTGRES_PASSWORD=letterpress_secrets POSTGRES_HOST=postgres POSTGRES_PORT=5432 POSTGRES_DB=letterpress_db ELASTICSEARCH_URL="http://elasticsearch: 9200"
Abra o arquivo post.go (na pasta modelos ) e configure a estrutura Post :
modelos de pacote
tipo Post struct { ID int `json:"id, omitempty"` String de título `json:"title"` String do corpo `json:"body"`
}
Em seguida, adicione o código abaixo a db/database.go para gerenciar a conexão do banco de dados:
pacote db importar ( "banco de dados/sql" "fmt" _"github.com/lib/pq" "github.com/rs/zerolog"
) tipo Database struct { Con * sql.DB Logger zerolog.Logger
} tipo Config struct { String host Port int String de nome de usuário String de senha String DbName Logger zerolog.Logger
} função Init (cfg Config) (Database, error) { bd:=Banco de dados {} dsn:=fmt.Sprintf ("host=% s porta=% d usuário=% s senha=% s dbname=% s sslmode=desativar", cfg.Host, cfg.Port, cfg.Username, cfg.Password, cfg.DbName) conn, err:=sql.Open ("postgres", dsn) se errar!=nulo { return db, err } db.Conn=conn db.Logger=cfg.Logger err=db.Conn.Ping () se errar!=nulo { return db, err } return db, nil
}
No código acima, definimos a configuração do banco de dados e adicionamos um campo Logger que pode ser usado para registrar erros e eventos do banco de dados.
Além disso, abra db/posts.go e implemente as operações de banco de dados para as tabelas posts e post_logs que criaremos em breve:
pacote db importar ( "banco de dados/sql" "fmt" "gitlab.com/idoko/letterpress/models"
) var ( ErrNoRecord=fmt.Errorf ("nenhum registro correspondente encontrado") insertOp="inserir" deleteOp="deletar" updateOp="atualizar"
) função (db Database) SavePost (post * models.Post) error { var id int consulta:=`INSERT INTO posts (title, body) VALUES ($ 1, $ 2) RETURNING id` errar:=db.Conn.QueryRow (query, post.Title, post.Body).Scan (& id) se errar!=nulo { return err } logQuery:=`INSERT INTO post_logs (post_id, operação) VALUES ($ 1, $ 2)` post.ID=id _, err=db.Conn.Exec (logQuery, post.ID, insertOp) se errar!=nulo { db.Logger.Err (err).Msg ("não foi possível registrar a operação para logstash") } retornar nulo
}
Acima, implementamos uma função SavePost que insere o argumento Post no banco de dados. Se a inserção for bem-sucedida, ele registra a operação e o ID gerado para a nova postagem em uma tabela post_logs . Esses logs acontecem no nível do aplicativo, mas se você sentir que as operações do banco de dados nem sempre passarão pelo aplicativo, você pode tentar fazer isso no nível do banco de dados usando gatilhos. Logstash usará posteriormente esses logs para sincronizar nosso índice Elasticsearch com nosso banco de dados de aplicativo.
Ainda no arquivo posts.go , adicione o código abaixo para atualizar e excluir postagens do banco de dados:
func (banco de dados db) UpdatePost (postId int, post models.Post) error { consulta:="UPDATE posts SET title=$ 1, body=$ 2 WHERE id=$ 3" _, err:=db.Conn.Exec (query, post.Title, post.Body, postId) se errar!=nulo { return err } post.ID=postId logQuery:="INSERT INTO post_logs (post_id, operação) VALUES ($ 1, $ 2)" _, err=db.Conn.Exec (logQuery, post.ID, updateOp) se errar!=nulo { db.Logger.Err (err).Msg ("não foi possível registrar a operação para logstash") } retornar nulo
} função (db Database) DeletePost (postId int) error { consulta:="DELETE FROM Posts WHERE id=$ 1" _, err:=db.Conn.Exec (query, postId) se errar!=nulo { if err==sql.ErrNoRows { return ErrNoRecord } return err } logQuery:="INSERT INTO post_logs (post_id, operação) VALUES ($ 1, $ 2)" _, err=db.Conn.Exec (logQuery, postId, deleteOp) se errar!=nulo { db.Logger.Err (err).Msg ("não foi possível registrar a operação para logstash") } retornar nulo
}
Migrações de banco de dados com golang-migrate
Embora o PostgreSQL crie automaticamente nosso banco de dados do aplicativo ao configurá-lo no contêiner do Docker, precisaremos configurar as tabelas nós mesmos. Para fazer isso, usaremos golang-migrate/migrate para gerenciar nosso banco de dados migrações . Instale migrate usando este guia e execute o comando abaixo para gerar o arquivo de migração para a tabela posts :
$ migrate criar-ext sql-dir db/migrations-seq create_posts_table $ migrate create-ext sql-dir db/migrations-seq create_post_logs_table
O comando acima criará quatro arquivos SQL em db/migrations, dois dos quais têm uma extensão .up.sql , enquanto os outros dois terminam com .down.sql . As migrações para cima são executadas quando aplicamos as migrações. Como queremos criar as tabelas em nosso caso, adicione o bloco de código abaixo ao arquivo XXXXXX_create_posts_table.up.sql :
CRIAR TABELA SE NÃO EXISTIR posts ( id SERIAL PRIMARY KEY, título VARCHAR (150), Texto de corpo );
Da mesma forma, abra XXXXXX_create_post_logs_table.up.sql e direcione-o para criar a tabela posts_logs como esta:
CRIAR TABELA SE NÃO EXISTIR post_logs ( id SERIAL PRIMARY KEY, post_id INT NOT NULL, operação VARCHAR (20) NOT NULL, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP );
As migrações
para baixo são aplicadas quando queremos reverter as alterações que fizemos no banco de dados. No nosso caso, queremos deletar as tabelas que acabamos de criar. Adicione o código abaixo a XXXXXX_create_posts_table.down.sql para excluir a tabela posts :
DROP TABLE IF EXISTS posts;
Faça o mesmo para a tabela posts_logs adicionando o código abaixo a XXXXXX_create_post_logs_table.down.sql :
DROP TABLE IF EXISTS post_logs;
Elasticsearch e PostgreSQL como contêineres Docker
Crie um arquivo docker-compose.yml na raiz do projeto e declare os serviços de que nosso aplicativo precisa, como este:
versão
:"3" Serviços: postgres: imagem: postgres reiniciar: a menos que parado hostname: postgres env_file:.env portas: -"5432: 5432" volumes: -pgdata:/var/lib/postgresql/data api: Construir: contexto:. dockerfile: Dockerfile hostname: api env_file:.env portas: -"8080: 8080" depende de: -postgres elasticsearch: imagem:'docker.elastic.co/elasticsearch/elasticsearch:7.10.2' ambiente: -discovery.type=nó único -"ES_JAVA_OPTS=-Xms512m-Xmx512m" portas: -"9200: 9200" volumes: -esdata:/usr/share/elasticsearch/data volumes: pgdata: motorista: local esdata: motorista: local
Os serviços incluem:
-
postgres-O banco de dados PostgreSQL que nosso aplicativo usará. Ele também expõe a porta PostgreSQL padrão para que possamos acessar nosso banco de dados de fora do contêiner -
api-Esta é a API REST de nosso aplicativo que nos permite criar e pesquisar postagens -
elasticsearch-A imagem Elasticsearch que potencializa nosso recurso de pesquisa. Também definimos o tipo de descoberta paranó único, uma vez que estamos em um ambiente de desenvolvimento
A seguir, crie o Dockerfile do projeto na pasta do projeto e preencha-o com o código abaixo:
DE golang: 1.15.7-buster COPIAR go.mod go.sum/go/src/gitlab.com/idoko/letterpress/ WORKDIR/go/src/gitlab.com/idoko/letterpress RUN go mod download CÓPIA DE./go/src/gitlab.com/idoko/letterpress RUN go build-o/usr/bin/letterpress gitlab.com/idoko/letterpress/cmd/api EXPOSE 8080 8080 ENTRYPOINT ["/usr/bin/letterpress"]
No código acima, configuramos o Docker para construir nosso aplicativo usando a imagem buster do Debian para Go. Em seguida, ele baixa as dependências do aplicativo, constrói o aplicativo e copia o binário resultante para /usr/bin .
Embora ainda não tenhamos implementado a API REST, você pode testar o progresso até agora executando docker-compose up-build em seu terminal para iniciar os serviços.
Com o serviço PostgreSQL em execução, exporte o Nome da fonte de dados (DSN) como uma variável de ambiente e aplique as migrações que criamos executando os comandos abaixo no diretório raiz do projeto:
$ export PGURL="postgres://letterpress: letterpress_secrets @ localhost: 5432/letterpress_db? sslmode=disable" $ migrate-database $ PGURL-path db/migrations/up
NOTA: O DSN tem o formato postgres://USERNAME: PASSWORD @ HOST: PORT/DATABASE? sslmode=SSLMODE . Lembre-se de usar seus valores se eles forem diferentes daqueles que usamos no arquivo .env acima.
Rotear manipuladores com gin-gonic/gin
Para configurar nossas rotas de API, crie um novo arquivo handler.go na pasta handlers e configure-o para inicializar e registrar as rotas relevantes:
importar ( "github.com/elastic/go-elasticsearch/v7" "github.com/gin-gonic/gin" "github.com/rs/zerolog" "gitlab.com/idoko/letterpress/db"
) tipo Handler struct { DB db.Database Logger zerolog.Logger ESClient * elasticsearch.Client
} função New (database db.Database, esClient * elasticsearch.Client, logger zerolog.Logger) * Handler { return & Handler { DB: banco de dados, ESClient: esClient, Logger: logger, }
} função (h * Handler) Register (group * gin.RouterGroup) { group.GET ("/posts/: id", h.GetPost) group.PATCH ("/posts/: id", h.UpdatePost) group.DELETE ("/posts/: id", h.DeletePost) group.GET ("/posts", h.GetPosts) group.POST ("/posts", h.CreatePost) group.GET ("/search", h.SearchPosts)
}
As rotas expõem uma interface CRUD para nossas postagens, bem como um ponto de extremidade de pesquisa para permitir a pesquisa de todas as postagens usando Elasticsearch.
Crie um arquivo post.go no mesmo diretório handlers e adicione a implementação para os manipuladores de rota acima (para abreviar, veremos como criar e pesquisar postagens, embora você possa ver a implementação completa para os outros manipuladores no repositório GitLab do projeto ):
manipulador de pacote
importar ( "contexto" "codificação/json" "fmt" "github.com/gin-gonic/gin" "gitlab.com/idoko/letterpress/db" "gitlab.com/idoko/letterpress/models" "net/http" "strconv" "cordas"
) função (h * Handler) CreatePost (c * gin.Context) { var post models.Post se errar:=c.ShouldBindJSON (& post); err!=nulo { h.Logger.Err (err).Msg ("não foi possível analisar o corpo da solicitação") c.JSON (http.StatusBadRequest, gin.H {"erro": fmt.Sprintf ("corpo de solicitação inválido:% s", err.Error ())}) Retorna } err:=h.DB.SavePost (& post) se errar!=nulo { h.Logger.Err (err).Msg ("não foi possível salvar a postagem") c.JSON (http.StatusInternalServerError, gin.H {"erro": fmt.Sprintf ("não foi possível salvar a postagem:% s", err.Error ())}) } outro { c.JSON (http.StatusCreated, gin.H {"post": post}) }
} função (h * Handler) SearchPosts (c * gin.Context) { var string de consulta se consulta, _=c.GetQuery ("q"); query==""{ c.JSON (http.StatusBadRequest, gin.H {"erro":"nenhuma consulta de pesquisa presente"}) Retorna } corpo:=fmt.Sprintf ( `{"query": {"multi_match": {"query":"% s","fields": ["title","body"]}}}`, consulta) res, err:=h.ESClient.Search ( h.ESClient.Search.WithContext (context.Background ()), h.ESClient.Search.WithIndex ("posts"), h.ESClient.Search.WithBody (strings.NewReader (body)), h.ESClient.Search.WithPretty (), ) se errar!=nulo { h.Logger.Err (err).Msg ("erro de elasticsearch") c.JSON (http.StatusInternalServerError, gin.H {"erro": err.Error ()}) Retorna } adiar res.Body.Close () if res.IsError () { var e map [string] interface {} se errar:=json.NewDecoder (res.Body).Decode (& e); err!=nulo { h.Logger.Err (err).Msg ("erro ao analisar o corpo da resposta") } outro { h.Logger.Err (fmt.Errorf ("[% s]% s:% s", res.Status (), e ["erro"]. (interface do mapa [string] {}) ["tipo"], e ["erro"]. (mapa [string] interface {}) ["motivo"], )). Msg ("falha ao pesquisar consulta") } c.JSON (http.StatusInternalServerError, gin.H {"erro": e ["erro"]. (mapa [string] interface {}) ["motivo"]}) Retorna } h.Logger.Info (). Interface ("res", res.Status ()) var r map [string] interface {} se errar:=json.NewDecoder (res.Body).Decode (& r); err!=nulo { h.Logger.Err (err).Msg ("erro de elasticsearch") c.JSON (http.StatusInternalServerError, gin.H {"erro": err.Error ()}) Retorna } c.JSON (http.StatusOK, gin.H {"dados": r ["acessos"]})
}
CreatePost pega o corpo da solicitação JSON e o transforma em uma estrutura Post usando o ShouldBindJSON . O objeto resultante é então salvo no banco de dados usando a função SavePost que escrevemos anteriormente.
SearchPosts é mais envolvente. Ele usa a consulta múltipla do Elasticsearch para pesquisar as postagens. Dessa forma, podemos encontrar rapidamente as postagens cujo título e/ou corpo contém a consulta fornecida. Também verificamos e registramos qualquer erro que possa ocorrer e transformamos a resposta em um objeto JSON usando o pacote json da biblioteca padrão Go e o apresentamos ao usuário como seus resultados de pesquisa.
Sincronizar banco de dados para Elasticsearch com Logstash
Logstash é um canal de processamento de dados que recebe dados de diferentes fontes de entrada, os processa e os envia para uma fonte de saída.
Como o objetivo é tornar os dados do nosso banco de dados pesquisáveis por meio do Elasticsearch, configuraremos o Logstash para usar o banco de dados PostgreSQL como entrada e o Elasticsearch como saída.
No diretório logstash/config , crie um novo arquivo pipelines.yml para conter todos os pipelines Logstash de que precisaremos. Para este projeto, é um único pipeline que sincroniza o banco de dados com o Elasticsearch. Adicione o código abaixo no novo pipelines.yml :
-pipeline.id: sync-posts-pipeline path.config:"/usr/share/logstash/pipeline/sync-posts.conf"
Em seguida, adicione um arquivo sync-posts.conf na pasta logstash/pipeline com o código abaixo para configurar as fontes de entrada e saída:
input { jdbc { jdbc_connection_string=>"jdbc: postgresql://$ {POSTGRES_HOST}: 5432/$ {POSTGRES_DB}" jdbc_user=>"$ {POSTGRES_USER}" jdbc_password=>"$ {POSTGRES_PASSWORD}" jdbc_driver_library=>"/opt/logstash/vendor/jdbc/postgresql-42.2.18.jar" jdbc_driver_class=>"org.postgresql.Driver" statement_filepath=>"/usr/share/logstash/config/queries/sync-posts.sql" use_column_value=> true tracking_column=>"id" tracking_column_type=>"numérico" cronograma=>"*/5 * * * * *" }
} filtro { mutate { remove_field=> ["@version","@timestamp"] }
} resultado { if [operação]=="deletar"{ elasticsearch { hosts=> ["http://elasticsearch: 9200"] # URL do contêiner ES docker-o docker resolveria isso para nós. ação=>"deletar" index=>"posts" document_id=>"% {post_id}" } } else if [operação] em ["inserir","atualizar"] { elasticsearch { hosts=> ["http://elasticsearch: 9200"] ação=>"índice" index=>"posts" document_id=>"% {post_id}" } }
}
O arquivo de configuração acima é composto de três blocos:
-
input-Estabelece uma conexão com PostgreSQL usando o plugin JDBC e instrui Logstash a executar a consulta SQL especificada porstatement_filepatha cada cinco segundos (configurado peloagendamentovalor). Embora cronograma tenha uma sintaxe parecida com cron, ele também suporta intervalos de subminutos e usa rufus-scheduler nos bastidores. Você pode aprender mais sobre a sintaxe e como configurá-la aqui . Também rastreamos a colunaidpara que o Logstash busque apenas as operações que foram registradas desde a última execução do pipeline -
filtro-Remove campos desnecessários, incluindo aqueles adicionados pelo Logstash -
output-Responsável por mover os dados de entrada em nosso índice Elasticsearch. Ele usa condicionais ES para excluir um documento do índice (se o campo de operação no banco de dados for uma exclusão) ou criar/atualizar um documento (se a operação for uma inserção ou uma atualização)
Você pode explorar a documentação do Logstash em input , filtro e saída plug-ins para ver ainda mais do que é possível em cada bloco.
Em seguida, crie um arquivo sync-posts.sql em logstash/queries para abrigar a instrução SQL de nosso pipeline:
SELECT l.id, l.operation, l.post_id, p.id, p.title, p.body FROM post_logs l LEFT JOIN posts p ON p.id=l.post_id ONDE l.id>: sql_last_value ORDER BY l.id;
A instrução SELECT usa junções SQL para buscar a postagem relevante com base no post_id na tabela post_logs .
Com nosso Logstash configurado, agora podemos configurar seu Dockerfile e adicioná-lo aos nossos serviços docker-compose. Crie um novo arquivo chamado Dockerfile na pasta logstash e adicione o código abaixo a ele:
FROM docker.elastic.co/logstash/logstash:7.10.2 RUN/opt/logstash/bin/logstash-plugin install logstash-integration-jdbc EXECUTE mkdir/opt/logstash/vendor/jdbc RUN curl-o/opt/logstash/vendor/jdbc/postgresql-42.2.18.jar https://jdbc.postgresql.org/download/postgresql-42.2.18.jar ENTRYPOINT ["/usr/local/bin/docker-entrypoint"]
O Dockerfile acima pega a imagem oficial do Logstash e configura o plug-in JDBC, bem como o driver JDBC PostgreSQL de que nosso pipeline precisa.
Atualize o arquivo docker-compose.yml adicionando Logstash à lista de serviços (ou seja, antes do bloco volumes ) assim:
logstash: Construir: contexto: logstash env_file:.env volumes: -./logstash/config/pipelines.yml:/usr/share/logstash/config/pipelines.yml -./logstash/pipelines/:/usr/share/logstash/pipeline/ -./logstash/queries/:/usr/share/logstash/config/queries/ depende de: -postgres -elasticsearch
O serviço Logstash usa o diretório logstash que contém o Dockerfile como seu contexto. Ele também usa volumes para montar os arquivos de configuração anteriores nos diretórios apropriados no contêiner Logstash.
Construindo nosso binário de API
Agora estamos prontos para expor nosso projeto como uma API HTTP. Faremos isso por meio do main.go residente em cmd/api . Abra-o em seu editor e adicione o código abaixo a ele:
pacote principal importar ( "github.com/elastic/go-elasticsearch/v7" "os" "strconv" "github.com/gin-gonic/gin" "github.com/rs/zerolog" "gitlab.com/idoko/letterpress/db" "gitlab.com/idoko/letterpress/handler"
) func main () { var dbPort int var err erro logger:=zerolog.New (os.Stderr).With (). Timestamp (). Logger () porta:=os.Getenv ("POSTGRES_PORT") se dbPort, err=strconv.Atoi (porta); err!=nulo { logger.Err (err).Msg ("falha ao analisar a porta do banco de dados") os.Exit (1) } dbConfig:=db.Config { Host: os.Getenv ("POSTGRES_HOST"), Porta: dbPort, Nome de usuário: os.Getenv ("POSTGRES_USER"), Senha: os.Getenv ("POSTGRES_PASSWORD"), DbName: os.Getenv ("POSTGRES_DB"), Logger: logger, } logger.Info (). Interface ("config", & dbConfig).Msg ("config:") dbInstance, err:=db.Init (dbConfig) se errar!=nulo { logger.Err (err).Msg ("Conexão falhou") os.Exit (1) } logger.Info (). Msg ("Conexão de banco de dados estabelecida") esClient, err:=elasticsearch.NewDefaultClient () se errar!=nulo { logger.Err (err).Msg ("Conexão falhou") os.Exit (1) } h:=handler.New (dbInstance, esClient, logger) roteador:=gin.Default () rg:=router.Group ("/v1") h.Register (rg) router.Run (": 8080")
}
Primeiro, configuramos um logger e o passamos para todos os componentes do aplicativo para garantir que os erros e os logs de eventos sejam uniformes. Em seguida, estabelecemos uma conexão de banco de dados usando valores das variáveis de ambiente (gerenciadas pelo arquivo .env ). Também nos conectamos ao servidor Elasticsearch e garantimos que ele esteja acessível. Em seguida, inicializamos nosso gerenciador de rota e iniciamos o servidor API na porta 8080. Observe que também usamos os grupos de rota do gin para colocar todas as nossas rotas em um namespace v1 , dessa forma, também fornecemos um tipo de “controle de versão” para nossa API.
Testando nosso aplicativo de pesquisa
Neste ponto, podemos experimentar nosso aplicativo de pesquisa. Reconstrua e inicie os serviços docker-compose executando docker-compose up--build em seu terminal. O comando também deve iniciar o servidor API em http://localhost: 8080 .
Abra sua ferramenta de teste de API favorita (por exemplo, Postman , cURL , HTTPie , etc.) e crie alguns posts. No exemplo abaixo, usei HTTPie para adicionar cinco postagens diferentes (provenientes do blog Creative Commons) ao nosso banco de dados:
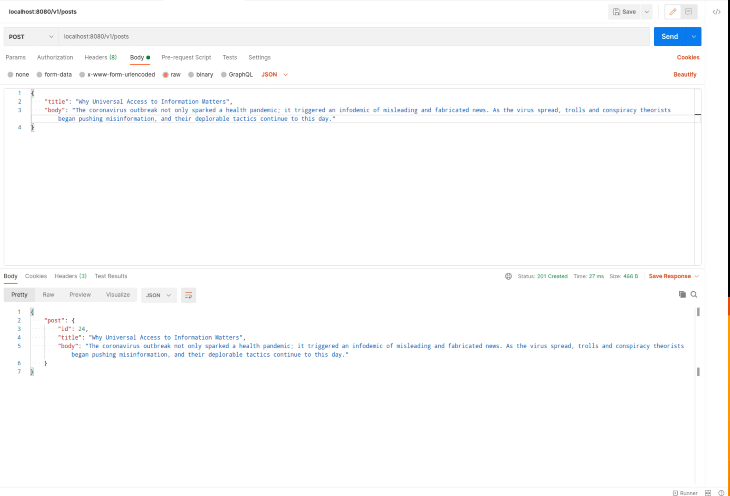
$ http POST localhost: 8080/v1/posts title="Conheça o CC da África do Sul, nosso próximo recurso para a Rede CC às sextas-feiras"body="Depois de apresentar o capítulo CC Itália a você em julho, o capítulo CC Holanda em agosto, Capítulo CC em Bangladesh em setembro, Capítulo CC Tanzânia em outubro, Capítulo CC Índia em novembro, Capítulo CC México em dezembro e Capítulo CC Argentina em janeiro, agora estamos viajando para a África ” $ http POST localhost: 8080/v1/posts title="Natureza morta: arte que traz conforto em tempos incertos"body="Há uma beleza tranquila e familiar encontrada na natureza morta, um tipo de arte que retrata principalmente objetos inanimados, como animais, alimentos ou flores. Essas imagens reconfortantes oferecem uma sensação de certeza e simplicidade em tempos incertos e complexos. Isso pode explicar por que mais de seis milhões de usuários do Instagram se apaixonaram por natureza morta" $ http POST localhost: 8080/v1/posts title="Por que o acesso universal à informação é importante"body="O surto de coronavírus não só desencadeou uma pandemia de saúde; ele desencadeou uma infodemia de notícias enganosas e fabricadas. À medida que o vírus se espalha, trolls e os teóricos da conspiração começaram a empurrar a desinformação e suas táticas deploráveis continuam até hoje."
Se preferir usar o Postman, aqui está uma captura de tela de uma solicitação do Postman semelhante às anteriores:
Você também pode verificar os registros docker-compose (se não estiver executando docker-compose em segundo plano) para ver como o Logstash indexa as novas postagens.
Para testar o endpoint de pesquisa, faça uma solicitação HTTP GET para http://localhost: 8080/v1/search conforme mostrado na captura de tela do Postman abaixo:
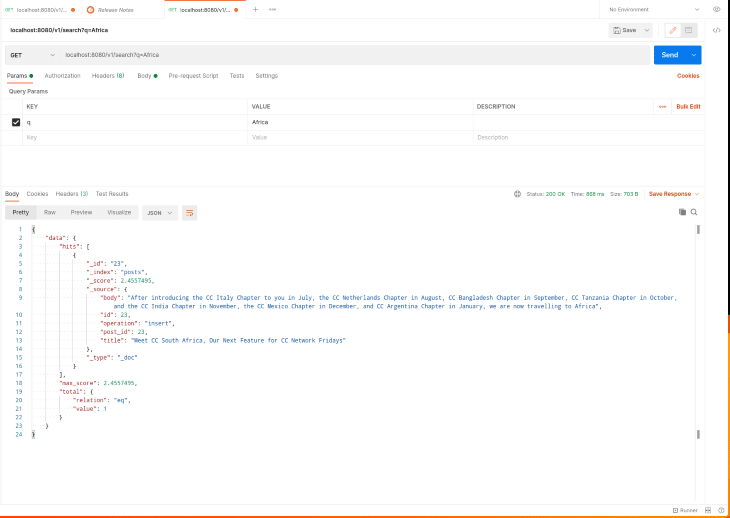
Visualize Elasticsearch com Kibana
Embora possamos sempre usar a API Elasticsearch para ver o que está acontecendo em nosso servidor Elasticsearch ou ver os documentos atualmente no índice, às vezes é útil visualizar e explorar essas informações em um painel personalizado. Kibana nos permite fazer exatamente isso. Atualize o arquivo docker-compose para incluir o serviço Kibana adicionando o código abaixo na seção serviços (ou seja, após o serviço logstash , mas antes dos volumes seção):
kibana: imagem:'docker.elastic.co/kibana/kibana:7.10.2' portas: -"5601: 5601" nome do host: kibana depende de: -elasticsearch
Tornamos o Kibana dependente do serviço Elasticsearch, pois ele será inútil se o Elasticsearch não estiver instalado e funcionando. Também expomos a porta Kibana padrão para que possamos acessar o painel de nossa máquina de desenvolvimento.
Inicie os serviços docker-compose executando docker-compose up (você terá que interrompê-los primeiro com docker-compose down se estiverem em execução). Visit http://localhost:5601 to access the Kibana dashboard.
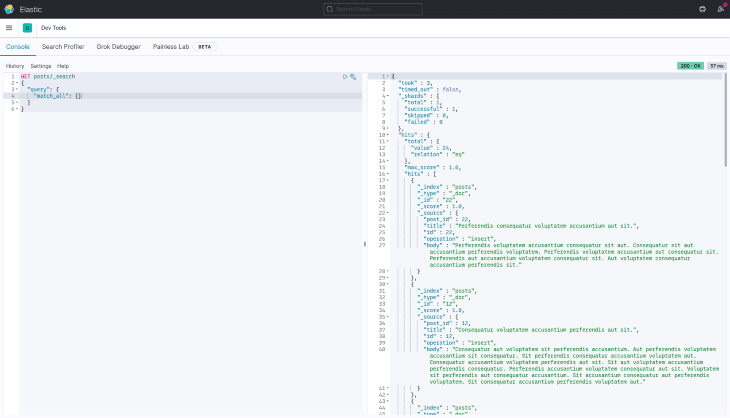
You can also use the Dev Tools to view all the documents in the posts index or to try out different search queries before using them in your application. In the screenshot below, we use match_all to list all the indexed posts:
Conclusão
In this article, we explored adding “search” to our Go application using the ELK stack. The complete source code is available on GitLab. Feel free to create an issue there if you run into a problem.
The post Using Elasticsearch, Logstash, and Kibana with Go applications appeared first on LogRocket Blog.