O aprendizado de máquina é um tópico muito interessante. Quando se trata de aprendizado de máquina em Rust, eu já mergulhei no assunto antes e o tópico continua a me fascinar.
Sempre que estou aprendendo uma nova linguagem de programação, depois de um tempo, me pergunto:”Posso fazer aprendizado de máquina com isso?”Claro, você pode “fazer aprendizado de máquina” com qualquer linguagem de programação. Portanto, a questão é: até que ponto isso funciona?
Neste tutorial, mostraremos como criar um aplicativo básico de aprendizado de máquina em Rust usando Linfa. No processo, abordaremos o seguinte:
- Rust é bom para aprendizado de máquina?
- O que é Linfa?
- O que é regressão logística?
- Criação de um aplicativo de aprendizado de máquina simples em Rust
- Carregando os dados
- Traçando os dados
- Treinamento e validação do modelo
- O futuro do aprendizado de máquina em Rust
O Rust é bom para aprendizado de máquina?
No espaço de aprendizado de máquina, linguagens como Python, R e, recentemente, Julia, reinam supremas porque têm bibliotecas, ferramentas e estruturas realmente boas que fazem grande parte do trabalho pesado associado à ciência de dados. A parte crítica do desempenho geralmente é tratada por bibliotecas BLAS/Lapack de baixo nível de qualquer maneira, então a sobrecarga de uma linguagem dinâmica não é tão dolorosa nesta área como poderia ser em, digamos, programação de jogos .
Qual é o status quo em relação ao aprendizado de máquina no Rust? Você pode verificar Já estamos aprendendo? para uma atualização de progresso contínuo no ecossistema de aprendizado de máquina Rust. No momento em que este artigo foi escrito, a comunidade estava ativa e progredindo rapidamente. No entanto, se você planeja fazer mais do que experimentar o aprendizado de máquina no Rust, deve esperar ter que construir algumas coisas por conta própria, dada a imaturidade do ecossistema.
Dito isso, já existem ótimas bibliotecas e kits de ferramentas de baixo nível disponíveis, incluindo o kit de ferramentas Linfa .
O que é Linfa?
Linfa é uma metacaixa de nível superior que inclui auxiliares comuns para processamento de dados e algoritmos para muitas áreas da máquina aprendizagem , incluindo:
- regressão linear
- Agrupamento de dados
- Métodos de kernel
- Regressão logística
- Bayes
- SVMs
Pelo que eu posso dizer, o kit de ferramentas é bem documentado e possui uma API intuitiva. O objetivo ambicioso do projeto é chegar perto da amplitude de funcionalidade do scikit. Se continuarem como no ano passado, posso ver isso acontecendo.
Em um experimento anterior , tentei construir um pequeno classificador em Go que usava regressão logística para classificar resultados de exames dos alunos e suas chances de serem aceitos na escola. Para este tutorial, tentaremos construir algo semelhante usando Rust e Linfa.
Começaremos carregando e plotando os dados para ter uma ideia. Em seguida, treinaremos modelos de regressão logística com vários parâmetros e selecionaremos aquele que executa melhor no conjunto de teste.
O que é regressão logística?
Como nosso foco é como abordar problemas de aprendizado de máquina usando Rust, não vamos nos aprofundar muito em como funciona exatamente a regressão logística. No entanto, devemos estabelecer pelo menos uma compreensão básica do que isso significa.
A regressão logística é um modelo estatístico para medir a probabilidade de um resultado, como verdadeiro/falso, aceito/negado, etc., que também pode ser estendido a várias dessas classes.
Dentro, o modelo usa uma função logística (curva S). A regressão logística é o processo de encontrar os parâmetros que se ajustam a um determinado conjunto de dados da melhor maneira. Simplificando, ele modela a probabilidade da variável aleatória em que estamos interessados (0 ou 1) em nossos dados.
No aprendizado de máquina, encontrar o modelo ideal geralmente é feito usando gradiente desce nt , uma otimização para encontrar mínimos locais. O objetivo geralmente é calcular um erro e minimizar esse erro.
Existem muitos recursos muito bons por aí para aprender mais sobre regressão logística e algoritmos de aprendizado de máquina em geral. Se você estiver interessado em mergulhar mais fundo, Awesome Machine Learning é um ótimo ponto de partida para aprender recursos, frameworks e bibliotecas e muito mais.
Criação de um aplicativo de aprendizado de máquina simples no Rust
O objetivo deste tutorial é demonstrar uma das muitas maneiras de criar um aplicativo de aprendizado de máquina simples em Rust. Como não pretendemos obter insights de dados reais, usaremos um conjunto de dados muito pequeno contendo apenas 100 registros.
Também pularemos a preparação de dados para fazer aprendizado de máquina, que pode incluir etapas de pré-processamento, como eliminação de valores discrepantes, normalização, limpeza de dados etc. Essa é uma parte muito importante da ciência de dados, mas simplesmente não está em escopo para este tutorial.
Os dados reais que usaremos em nosso exemplo têm a seguinte aparência:
32.72283304060323,43.30717306430063,0 64.0393204150601,78.03168802018232,1
Na primeira coluna, temos a pontuação do aluno no primeiro exame e, na segunda, o resultado de um segundo exame. Esses são nossos recursos . A terceira coluna, chamada de target , denota se o aluno foi aceito na escola com esses resultados. Um 1 significa aceito e um 0 significa que eles foram negados.
Nosso objetivo é treinar um modelo que possa prever com segurança, com base em duas pontuações de testes, se um aluno será aceito na escola. O conjunto de dados é dividido em 65 linhas de dados de treinamento, que usaremos para treinar o modelo, e 35 linhas de dados de teste, que usaremos para validar o modelo treinado. Por fim, determinaremos se nosso modelo tem um bom desempenho com dados que ainda não viu.
Você pode acessar os arquivos de dados de treinamento e teste como CSV no GitHub .
Para acompanhar, você só precisa de uma instalação recente do Rust (1,51 no momento da redação). Primeiro, crie um novo projeto Rust: Em seguida, edite o arquivo Usaremos Também usaremos o recurso Além do Linfa, também usaremos a fantástica caixa Finalmente, usaremos Para começar, carregue os dados dos arquivos CSV em No A biblioteca Os documentos do Rust oferecem uma explicação detalhada sobre o fatiamento em Nossos dois recursos são identificados como Podemos chamar isso de A seguir, veremos como criar um gráfico de dispersão usando Para criar um gráfico de dispersão, usaremos O primeiro passo é colocar nossos dados no formato correto. Para criar um gráfico de dispersão, precisamos criar dois gráficos: um para os pontos de dados positivos (aceitos) e um para os pontos de dados negativos (negados). Neste ponto, podemos finalmente criar plotagens reais. Definiremos estilos de pontos diferentes para diferenciar entre positivos e negativos e colocá-los dentro de uma Basta salvar o gráfico como um arquivo SVG. O resultado deve ser assim: Como você pode ver, os dados são bem separados visualmente, então esperamos obter um bom resultado ajustando um modelo a esses dados. Podemos chamar a função A etapa final é treinar e validar o modelo. Para conseguir isso, teremos que concluir as seguintes etapas: Uma matriz de confusão é essencialmente uma tabela que mostra verdadeiros positivos, falsos positivos, verdadeiros negativos e falsos negativos e permite você pode calcular métricas, como a exatidão ou precisão de um modelo. Concluiremos as etapas acima várias vezes. Existem dois parâmetros no modelo que tentaremos otimizar: a quantidade de iterações e o limite de decisão. Primeiro, crie um método auxiliar para fazer uma iteração do modelo, calculando e retornando uma matriz de confusão: A próxima etapa é passar no teste e treinar os dados. Ignore os tipos longos-este é um efeito colateral do agrupamento Linfa e A seguir, crie o modelo Chame Isso testará nosso modelo treinado nos dados de teste. Podemos posteriormente produzir uma matriz de confusão a partir do resultado. Para alterar os parâmetros e encontrar o modelo ideal, criaremos um loop aninhado em Esta certamente não é a maneira mais eficiente de abordar isso. Lembre-se de que isso pode ser paralelizado na mesma máquina ou em um cluster em um cenário real. A próxima etapa é calcular uma matriz de confusão ótima inicial e definir intervalos para os parâmetros Assim que tivermos um resultado, compare a precisão do modelo com o melhor modelo anterior e salve os parâmetros se houver um modelo melhor. A etapa final é imprimir os parâmetros e métricas de desempenho para nosso modelo ideal. Executar todo esse aplicativo com Funciona! Como você pode ver, apenas dois pontos de dados foram classificados incorretamente, o que nos dá uma precisão de aproximadamente 94 por cento. Nada mal! Você deve obter os resultados desta experiência com uma pedra gigante de sal; ciência de dados em um conjunto de dados de 100 entradas não é ciência de dados, apenas ruído de dados. No entanto, você pode ver que nossa abordagem funcionou. Você também pode brincar com os parâmetros e imprimi-los dentro do loop para ver o desempenho em diferentes estágios do processo Você pode encontrar o exemplo de código completo no GitHub . O ecossistema de aprendizado de máquina de Rust deu grandes passos desde que o verifiquei pela primeira vez, e não parece que a comunidade planeja desacelerar tão cedo. Estou animado para ver onde isso vai dar e se Rust pode ser um sério competidor para as linguagens e plataformas estabelecidas neste espaço. Olhando para os pontos fortes do Rust, por ser uma linguagem de sistemas muito rápida, segura e de baixo nível, pode ser uma ótima opção para criar aplicativos de aprendizado de máquina escalonáveis no futuro-ou seja, se se tornar ergonômico o suficiente para ser usado com as plataformas e ferramentas existentes. A postagem Aprendizado de máquina em Rust usando Linfa apareceu primeiro no LogRocket Blog . cargo new rust-ml-example
cd rust-ml-example
Cargo.toml e adicione as dependências de que você precisará: [dependências]
linfa={version="0.3.1", features=["openblas-system"]}
linfa-logistic="0.3.1"
ndarray={version="0.13", default-features=false}
ndarray-csv="0,4"
csv="1,1"
plotlib="0.5.1"
linfa e as caixas linfa-logistic , que fornecem o kit de ferramentas básico do Linfa e o algoritmo de regressão logística. openblas-system , o que significa que contaremos com libopenblas para os cálculos de baixo nível. Existem algumas outras opções para o back-end BLAS/Lapack (baixo nível, bibliotecas de álgebra linear altamente otimizadas) que o Linfa pode usar. ndarray , que é o padrão de fato em Rust para vetores n-dimensionais. Para carregar os conjuntos de dados no aplicativo e convertê-los em um ndarray , usaremos o csv e ndarray-csv engradados, que também são usados internamente no Linfa para carregar conjuntos de dados nos exemplos. plotlib para criar uma dispersão SVG inicial traçar os dados para ter uma ideia de como os pontos de dados são distribuídos. Carregando os dados
./data/test.csv e ./data/train.csv , converta-os em um ndarray , e crie um Linfa Dataset a partir dele: fn load_data (path: & str)-> Conjunto de dados
csv:: ReaderBuilder , definimos has_headers como false uma vez que não temos uma linha de cabeçalho, definimos o delimitador e caminho e recuperou um leitor dele. ndarray-csv tem um método utilitário para criar um ndarray:: Array2 , um array bidimensional, deste leitor, que posteriormente dividimos usando a macro do construtor de argumento de fatia ndarray:: s! . Esta macro usa intervalos como uma entrada para argumentos de saída para o método array.slice para dividir os dados brutos nas partes que precisamos. ndarray se você quiser se aprofundar. A ideia é essencialmente cortar as duas primeiras colunas em nosso array data e a terceira coluna no array targets porque é isso que linfa:: Dataset espera criar um novo conjunto de dados. teste 1 e teste 2 , respectivamente, retornando o conjunto de dados concluído ao chamador. main para nossos dados de treinamento e teste: fn main () { let train=load_data ("data/train.csv"); deixe test=load_data ("data/test.csv"); ...
}
plotlib . Plotagem dos dados
plotlib , um leve e fácil de usar-usar a biblioteca para plotagem em Rust. fn plot_data ( train: & DatasetBase < ArrayBase
plotlib espera dados na forma de um Vec <(f64, f64)> , então precisamos primeiro massagear nosso ndarray -apoiou o conjunto de dados Linfa de volta a esta forma, iterando os registros (recursos) e alvos e coletando-os em vetores. Então, devemos iterar esses vetores e adicionar os pontos de dados positivos a um vetor positivo e os negativos a um vetor negativo . ContinuousView , onde definiremos valores de rótulo e intervalos máximos de eixo. 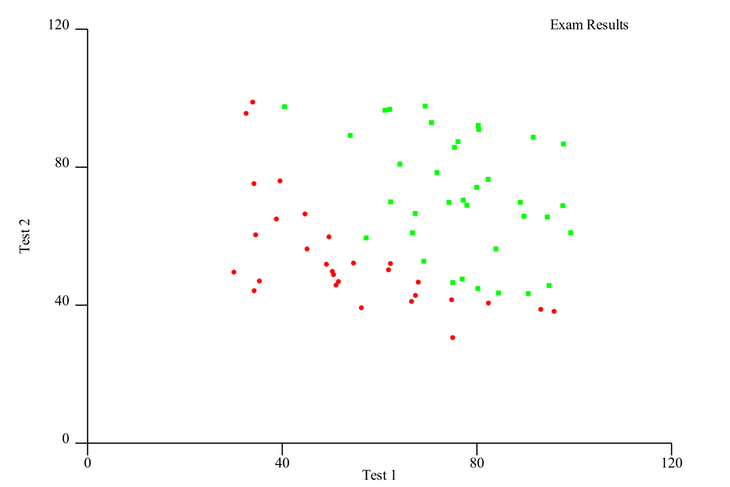
plot_data com alguma impressão inicial de metadados sobre nossos dados, como este em main : ... let features=train.nfeatures (); let targets=train.ntargets (); println! ( "treinamento com {} amostras, teste com {} amostras, {} recursos e {} destino", train.nsamples (), test.nsamples (), recursos, alvos ); println! ("plotagem de dados..."); plot_data (& train);
...
Treinamento e validação do modelo
fn iterate_with_values ( train: & DatasetBase < ArrayBase
n``darray . Em um projeto maior, simplesmente criaríamos aliases de tipo aqui, bem como os valores para o limite de decisão e as iterações máximas. LogisticRegression com as max_iterations fornecidas. O gradiente_tolerância é definido como 0,0001 , que é o valor padrão, apenas para mostrar que também pode ser definido. Esta é a taxa de aprendizado para descida de gradiente. Manipular esse valor pode acelerar ou desacelerar seu cálculo com o preço potencial de ficar preso em um mínimo local com valores mais altos. .fit (train) no modelo para treiná-lo em nossos dados de treinamento. Depois disso, crie um modelo de validação definindo o limite de decisão e chamando .predict (test) nos dados de teste. main no qual chamaremos o auxiliar iterate_with_values : println! ("modelo de treinamento e teste..."); deixe mut max_accuracy_confusion_matrix=iterate_with_values (& train, & test, 0,01, 100); deixe mut best_threshold=0,0; deixe mut best_max_iterations=0; deixe limite de mut=0,02; para max_iterations em (1000..5000).step_by (500) { enquanto limiar <1.0 { deixe confusão_matriz=iterar_com_valores (& treinar, & testar, limite, max_iterações); if confused_matrix.accuracy ()> max_accuracy_confusion_matrix.accuracy () { max_accuracy_confusion_matrix=confusão_matrix; best_threshold=threshold; best_max_iterations=max_iterations; } limiar +=0,01; } limiar=0,02; } println! ( "matriz de confusão mais precisa: {:?}", max_accuracy_confusion_matrix ); println! ( "com max_iterations: {}, limite: {}", best_max_iterations, best_threshold ); println! ("precisão {}", max_accuracy_confusion_matrix.accuracy (),); println! ("precisão {}", max_accuracy_confusion_matrix.precision (),); println! ("recall {}", max_accuracy_confusion_matrix.recall (),);
max_iterations e threshold , iterar por meio deles e calcular nosso modelo para cada um. cargo run resulta no seguinte: treinamento com 65 amostras, teste com 35 amostras, 2 recursos e 1 alvo
plotando dados...
modelo de treinamento e teste...
matriz de confusão mais precisa:
aulas | negado | aceitaram
negado | 11 0
aceito | 2 | 22 com max_iterations: 1000, limite: 0,37000000000000016
precisão 0,94285715
precisão 0,84615386
lembre-se de 1
O futuro do aprendizado de máquina em Rust