Linhas duplicadas:
Em tabelas SQL, pode haver linhas duplicadas, o que freqüentemente leva à inconsistência de dados. Esses problemas podem ser superados com uma chave primária, mas às vezes, quando essas regras não são seguidas ou ocorre uma exceção, o problema se torna mais assustador. É uma prática melhor usar as chaves e restrições relevantes para remover o risco de linhas duplicadas. Para limpar dados duplicados, você deve usar alguns procedimentos especiais.
Excluindo linhas duplicadas no SQL
Em uma tabela do SQL Server, registros duplicados podem ser um problema sério. Dados duplicados podem resultar em pedidos processados várias vezes, relatórios de resultados incorretos e muito mais. No SQL Server, existem muitas opções para lidar com registros duplicados em uma tabela, dependendo das circunstâncias. São eles:
- Restrições exclusivas na tabela
- Sem restrições exclusivas na tabela
Restrições exclusivas na tabela
De acordo com Excluir linhas duplicadas em SQL, uma tabela com um índice exclusivo pode usar o índice para identificar dados duplicados e, em seguida, excluir os registros duplicados. Auto-joins, ordenando os dados pelo valor máximo, usando a função RANK ou usando a lógica NOT IN é usado para realizar a identificação.
Sem restrições exclusivas na tabela
Em Excluir linhas duplicadas em SQL, é um pouco difícil para tabelas sem um índice especial. A função ROW NUMBER () pode ser usada em conexão com uma expressão de tabela comum (CTE) para classificar os dados e, em seguida, remover os registros duplicados.
SQL Excluir linhas duplicadas usando Group By e tendo cláusula
De acordo com Excluir linhas duplicadas em SQL, para localizar linhas duplicadas, você precisa usar o cláusula SQL GROUP BY . A função COUNT pode ser usada para verificar a ocorrência de uma linha usando a cláusula Group by, que agrupa os dados de acordo com as colunas fornecidas.
Código:
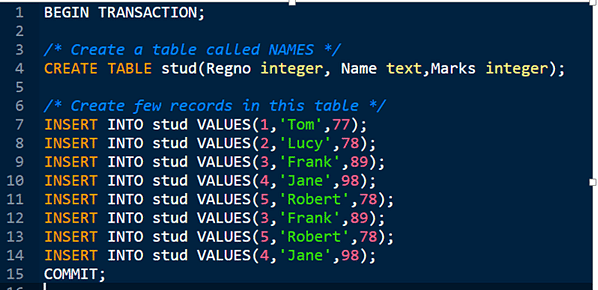
Criação e inserção de dados na tabela:
Primeiro, você precisa criar uma tabela da seguinte maneira:
CREATE TABLE stud (Regno integer, Name text, Marks integer);
/* Crie alguns registros nesta tabela */
INSERT INTO stud VALUES (1,’Tom’, 77);
INSERT INTO Stud VALUES (2,’Lucy’, 78);
INSERT INTO Stud VALUES (3,’Frank’, 89);
INSERT INTO stud VALUES (4,’Jane’, 98);
INSERT INTO Stud VALUES (5,’Robert’, 78);
INSERT INTO Stud VALUES (3,’Frank’, 89);
INSERT INTO Stud VALUES (5,’Robert’, 78);
INSERT INTO stud VALUES (4,’Jane’, 98);
COMPROMETE-SE;
Curso GRATUITO: Introdução à Análise de Dados
O domínio da análise de dados está à distância de um clique! Começar a aprender
Buscando e identificando as linhas duplicadas no SQL
/* Exibir todos os registros da tabela */
SELECT * FROM stud;
Entrada

Saída
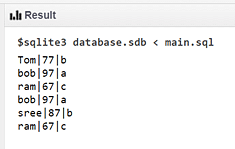
A tabela ilustrada acima, que consiste em repetição de dados, ou seja, dados duplicados, pode ser excluída usando a cláusula group by da seguinte forma:
Excluindo linhas duplicadas da tabela usando a cláusula agrupar por e tendo
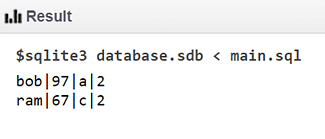
No SQL, a exclusão de linhas duplicadas no SQL é feita com a cláusula Group by e Having. Isso é feito da seguinte maneira:
Código:
selecione Nome, Marcas, nota, contagem (*) como cnt do grupo de reprodutores por Nome, Marcas, nota tendo contagem (*)> 1;
Entrada:

Resultado:
SQL Excluir Linhas Duplicadas Usando Expressões de Tabela Comuns (CTE)
Expressão de tabela comum
Ao excluir linhas duplicadas em SQL, a sigla CTE significa”expressão de tabela comum”. É um conjunto de resultados temporário nomeado criado por uma consulta simples e especificado no escopo de uma única expressão SELECT, INSERT, UPDATE ou DELETE. Você pode escrever consultas recursivas complexas usando CTE. Tem muito mais tração do que mesas temporárias.
Sintaxe
COM [CTEName]
Como
(Selecione col1, col2, col3 de [tablename] onde [condição]
Selecione col1, col2, col3 de [CTEName]
Procedimento para remover as linhas duplicadas usando CTE
Primeiro, você precisa criar um script de tabela Employ_DB para o SQL Server e executá-lo no banco de dados necessário.
Criando a tabela
Criar a tabela Employ_DB (emp_no number (10), emp_name varchar (20), emp_address varchar (25), emp_eoj date);
Entrada:

Saída

Inserindo dados na tabela
Depois que a tabela foi estabelecida, você deve inserir alguns registros nela, incluindo algumas duplicatas.
Código:
Insira os valores Employ_DB (11,’Mohith’,’tokya’,’12 de maio de 2000′);
Entrada:
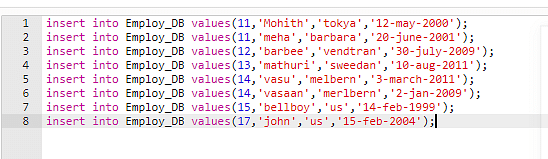
Resultado:
(8) linhas inseridas
Pesquisa de dados da tabela
Em seguida, execute o script anterior e use a consulta a seguir para pesquisar os dados na tabela.
Para imprimir os registros do Employ_EB em uma lista classificada, use o nome do campo e o endereço de um funcionário.
Código:
Selecione * no pedido Employ_DB por emp_name, emp_address;
Entrada:

Resultado:
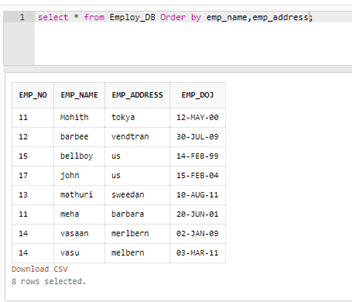
Excluindo linhas duplicadas em SQL usando CTE
De acordo com Excluir linhas duplicadas no SQL, o código acima contém muitos dos registros duplicados que foram fixados na tabela. Para numerar registros de cidades duplicados por estado, você usará o recurso de número de linha do CTE (). CTE pode gerar um conjunto de resultados temporário que você pode usar para remover registros redundantes da tabela real com uma única pergunta.
Código:
Com CTE como (Selecione emp_no, emp_name, row_number ()
Acima (partição por emp_no e ordem por emp_no) como numero_de_emplantar
De Employ_DB) Selecione * do pedido CTE por emp_name, emp_no;
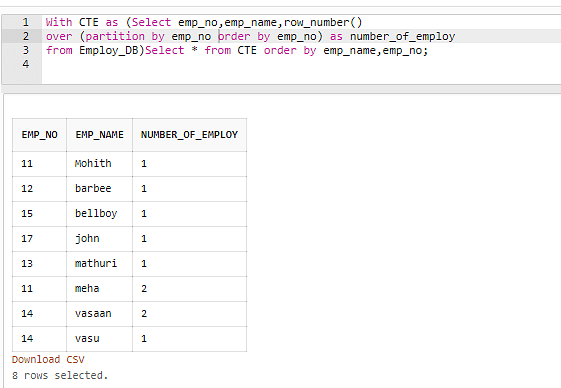
Finalmente, exclua o registro duplicado usando a expressão de tipo comum da seguinte maneira:
Código:
Com CTE como (Selecione emp_no, emp_name, row_number ()
Acima (partição por emp_no e ordem por emp_no) como numero_de_emplantar
De Employ_DB)
Selecione * em CTE onde número de funcionários> 1 pedido por emp_no;
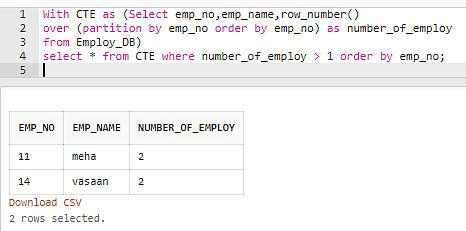
De acordo com Excluir linhas duplicadas no SQL, na tabela acima, apenas dois dos registros são duplicados com base no emp_no. Portanto, agora você vai excluir esse registro duplicado da tabela Employ_DB usando o código a seguir.

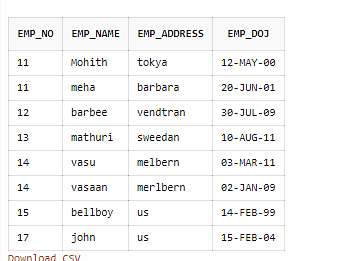
Função de classificação para SQL excluir linhas duplicadas
De acordo com Excluir linhas duplicadas no SQL, você também pode usar o recurso SQL RANK para se livrar das linhas duplicadas. Independentemente de linhas duplicadas, a função SQL RANK retorna um ID de linha exclusivo para cada linha.
Você precisa usar funções agregadas como Max, Min e AVG para realizar cálculos nos dados. Usando essas funções, você obtém uma única linha de saída. As funções SQL RANK no SQL Server permitem que você especifique uma classificação para campos individuais com base em categorizações. Para cada linha participante, ele retorna um valor agregado. As funções RANK em SQL são frequentemente chamadas de funções de janela.
Você pode implementar funções de classificação de quatro maneiras.
- ROW_NUMBER ()
- RANK ()
- DENSE_RANK ()
- NTILE ()
De acordo com Excluir linhas duplicadas em SQL, a cláusula PARTITION BY é usada com a função RANK na consulta a seguir. A cláusula PARTITION BY divide os dados em subconjuntos para as colunas listadas e atribui uma classificação a cada partição.
Código:
Selecione *,
RANK () OVER (PARTITION BY Animal_id, Animal_name ORDER BY sno DESC) rank
Dos Animais) T em A.sno=T.sno
Onde T.Rank> 1
Animais de mesa alterados
Soltar coluna sno
Selecione * entre os animais
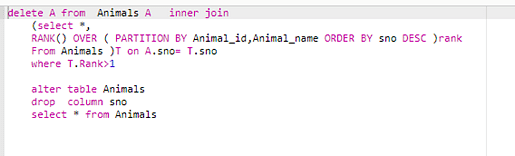
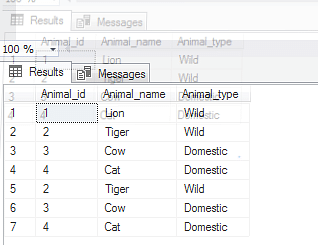
Você pode ver na captura de tela que a linha com uma classificação maior que um precisa ser removida. Vamos usar a seguinte pergunta para nos livrar dessas linhas.
Programa de Pós-Graduação em Análise de Negócios
Em parceria com a Purdue University VER CURSO
Use o pacote SSIS para SQL excluir linhas duplicadas
O serviço de integração do SQL Server inclui várias transformações e operadores que ajudam administradores e desenvolvedores a reduzir o trabalho manual e otimizar tarefas. O pacote SSIS também pode ser usado para excluir linhas duplicadas de uma tabela SQL.
Use o operador de classificação em um pacote SSIS para remover linhas duplicadas
Um operador Classificar pode ser usado para classificar os valores em uma tabela SQL. Você pode estar se perguntando como a classificação de dados o ajudará a se livrar de linhas duplicadas. É assim que funciona.
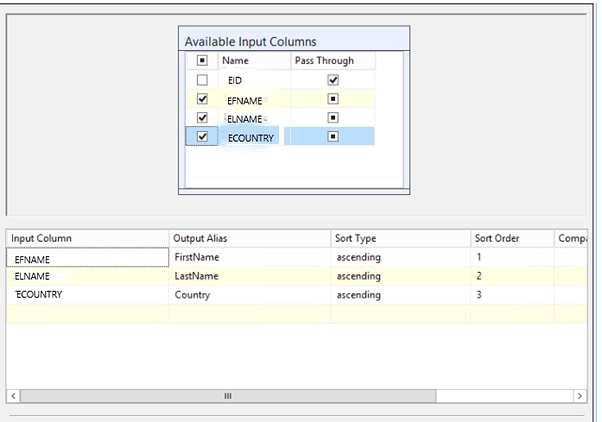
Para demonstrar esse desafio, crie um kit SSIS.
Primeiro, crie um novo kit de integração no SQL Server Data Tools. Adicione um link de fonte OLE DB ao novo pacote.
Ganhe experiência nas mais recentes ferramentas e técnicas de análise de negócios com o Programa de certificação de analista de negócios . Inscreva-se agora!
Conclusão
Neste artigo, você viu como remover linhas duplicadas em SQL usando T-SQL , CTE e o kit SSIS, entre outros métodos. Você é livre para usar qualquer abordagem que o faça se sentir mais à vontade. No entanto, é desaconselhado implementar diretamente esses procedimentos e empacotar os resultados de saída. Você deve conduzir seus testes em um ambiente menos exigente.
Para se tornar um especialista em linguagem de programação SQL, participe de nosso Simplilearn’s Curso de treinamento para certificação em SQL . Este curso de certificação em SQL fornece tudo que você precisa para começar a trabalhar com bancos de dados SQL e incorporá-los em seus aplicativos. Aprenda como organizar seu banco de dados corretamente, escrever instruções e cláusulas SQL eficazes e manter seu banco de dados SQL para escalabilidade. Este curso inclui cobertura abrangente de noções básicas de SQL, cobertura abrangente de todas as ferramentas de consulta e comandos SQL relevantes, um certificado de conclusão de curso reconhecido pelo setor e acesso vitalício ao aprendizado individualizado.
Apesar do SQL ser uma linguagem antiga, ainda é muito útil hoje, já que empresas em todo o mundo coletam grandes quantidades de dados. SQL é uma das habilidades de engenharia mais exigidas, e dominá-la melhorará muito o seu currículo.
Gerenciamento de banco de dados e relacionamento, ferramentas de consulta e comandos SQL, funções agregadas, agrupar por cláusula, tabelas e junções, subconsultas, manipulação de dados, controle de transações, visualizações e procedimentos estão entre as habilidades abordadas.
Comece a aprender gratuitamente as habilidades mais exigidas de hoje. Este curso enfatiza o desenvolvimento de boas habilidades essenciais para o avanço na carreira futura. Especialistas na área irão ensinar você. Obtenha acesso a mais de 300 habilidades prontas para o trabalho nos campos mais demandados de hoje. Aprenda de qualquer lugar, em qualquer laptop, enquanto trabalha ou estuda. Explore os cursos gratuitos aqui . Você pode encontrar guias gratuitos sobre vários planos de carreira, salários, dicas para entrevistas e muito mais.
Tem alguma pergunta para nós? Deixe-os na seção de comentários deste artigo e nossos especialistas entrarão em contato com você sobre eles, o mais rápido possível!
