.fb-comments,.fb-comments span,.fb-comments span iframe[style]{min-width:100%!important;width:100%!important}
Nos últimos anos, as plataformas de educação on-line viram um aumento na adoção e um aumento na demanda por aprendizados baseados em vídeo porque oferecem um meio eficaz para envolver os alunos. Para expandir para mercados internacionais e atender a uma população cultural e linguísticamente diversificada, as empresas também estão buscando diversificar suas ofertas de aprendizado, localizando o conteúdo em vários idiomas. Essas empresas estão procurando maneiras confiáveis e econômicas de resolver seus casos de uso de localização.
A localização de conteúdo inclui principalmente a tradução de vozes originais para novos idiomas e a adição de recursos visuais, como legendas. Tradicionalmente, esse processo é caro, manual e leva muito tempo, incluindo o trabalho com especialistas em localização. Com o poder dos serviços de machine learning (ML) da AWS, como Amazon Transcribe, Amazon Translate e Amazon Polly, você pode criar uma solução de localização viável e econômica. Você pode usar o Amazon Transcribe para criar uma transcrição de seus fluxos de áudio e vídeo existentes e, em seguida, traduzir essa transcrição para vários idiomas usando o Amazon Translate. Você pode usar o Amazon Polly, um serviço de conversão de texto em fala, para converter o texto traduzido em fala humana com som natural.
A próxima etapa da localização é adicionar legendas ao conteúdo, o que pode melhorar a acessibilidade e compreensão, além de ajudar os espectadores a entender melhor os vídeos. A criação de legendas no conteúdo de vídeo pode ser um desafio porque a fala traduzida não corresponde ao tempo da fala original. Essa sincronização entre áudio e legendas é uma tarefa crítica a ser considerada, pois pode desconectar o público do seu conteúdo se eles não estiverem sincronizados. O Amazon Polly oferece uma solução para esse desafio por meio da habilitação de marcas de fala, que você pode usar para criar um arquivo de legenda que pode ser sincronizado com a saída de fala gerada.
Nesta postagem, analisamos uma solução de localização usando a AWS Serviços de ML onde usamos um vídeo original em inglês e o convertemos em espanhol. Também nos concentramos no uso de marcas de fala para criar um arquivo de legenda sincronizado em espanhol.
Visão geral da solução
O diagrama a seguir ilustra a arquitetura da solução.
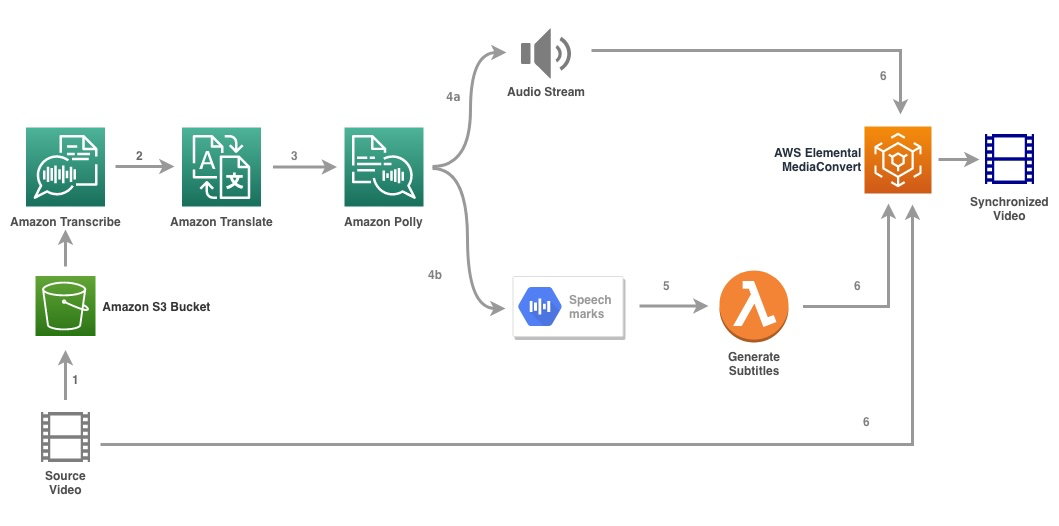
A solução usa um arquivo de vídeo e as configurações de idioma de destino como entrada e usa o Amazon Transcribe para criar uma transcrição de o vídeo. Em seguida, usamos o Amazon Translate para traduzir a transcrição para o idioma de destino. O texto traduzido é fornecido como uma entrada para o Amazon Polly para gerar o fluxo de áudio e as marcas de fala no idioma de destino. O Amazon Polly retorna a saída da marca de fala em um fluxo JSON delimitado por linha, que contém os campos como hora, tipo, início, fim e valor. O valor pode variar dependendo do tipo de marca de fala solicitada na entrada, como SSML, visema, palavra ou frase. Para fins de nosso exemplo, solicitamos o tipo de marca de fala como palavra. Com essa opção, o Amazon Polly divide uma frase em suas palavras individuais na frase e seus horários de início e término no fluxo de áudio. Com esses metadados, as marcas de fala são processadas para gerar as legendas para o fluxo de áudio correspondente gerado pelo Amazon Polly.
Por fim, usamos o AWS Elemental MediaConvert para renderizar o vídeo final com o áudio traduzido e as legendas correspondentes.
O vídeo a seguir demonstra o resultado final da solução:
Fluxo de trabalho do AWS Step Functions
Usamos o AWS Step Functions para orquestrar esse processo. A figura a seguir mostra uma visualização de alto nível do fluxo de trabalho do Step Functions (algumas etapas foram omitidas do diagrama para maior clareza).

As etapas do fluxo de trabalho são as seguintes:
Um usuário carrega o arquivo de vídeo de origem em um bucket do Amazon Simple Storage Service (Amazon S3). A notificação de evento do S3 aciona a função AWS Lambda state_machine.py (não mostrado no diagrama), que invoca a máquina de estado do Step Functions. A primeira etapa, Transcrever áudio, invoca a função Lambda transcribe.py, que usa o Amazon Transcribe para gerar uma transcrição do áudio do vídeo de origem.
O código de amostra a seguir demonstra como criar um trabalho de transcrição usando o destino Boto3 SDK do Python:
response=transcribe.start_transcription_job( TranscriptionJobName=jobName, MediaFormat=media_format, Media=”MediaFileUri”:”s3://”+bucket+”/”+mediaconvert_video_filename , OutputBucketName=bucket, OutputKey=outputKey, IdentifyLanguage=True )
Após a conclusão do trabalho, os arquivos de saída são salvos no bucket do S3 e o processo continua para a próxima etapa de tradução do conteúdo.
O Traduzir transcrição invoca a função Lambda translate.py que usa o Amazon Translate para traduzir a transcrição para o idioma de destino. Aqui, usamos a tradução síncrona/em tempo real usando o translate_text: # Resposta de tradução em tempo real=translate.translate_text( Text=transcribe_text, SourceLanguageCode=source_language_code, TargetLanguageCode=target_language_code, )
A tradução síncrona tem limites no tamanho do documento que pode traduzir; a partir desta escrita, está definido para 5.000 bytes. Para tamanhos de documentos maiores, considere usar uma rota assíncrona de criação do trabalho usando start_text_translation_job e verificar o status por meio de describe_text_translation_job.
A próxima etapa é um estado Step Functions Parallel, onde criamos ramificações paralelas em nossa máquina de estado. Na primeira ramificação, invocamos a função Lambda a função Lambda generate_polly_audio.py para gerar nosso fluxo de áudio do Amazon Polly: # Configure o cliente de serviços de polly e translate=boto3.client(‘polly’) # Use o texto traduzido para criar a resposta de fala sintetizada=client.start_speech_synthesis_task( Engine=”standard”, LanguageCode=”es”, OutputFormat=”mp3″, SampleRate=”22050″, Text=polly_text, VoiceId=”Miguel”, TextType=”text”, OutputS3BucketName=”S3-bucket-name”, OutputS3KeyPrefix=”-polly-recording”) audio_task_id=response[‘SynthesisTask’][‘TaskId’]
Aqui usamos o start_speech_synthesis_task do Amazon Polly Python SDK para acionar a síntese de fala tarefa que cria o áudio do Amazon Polly. Definimos OutputFormat como mp3, que informa ao Amazon Polly para gerar um fluxo de áudio para essa chamada de API.
Na segunda ramificação, invocamos a função Lambda generate_speech_marks.py para gerar saída de marcas de fala:…. # Use o texto traduzido para criar a resposta de marcas de fala=client.start_speech_synthesis_task( Engine=”standard”, LanguageCode=”es”, OutputFormat=”json”, SampleRate=”22050″, Text=polly_text, VoiceId=”Miguel”, TextType=”text”, SpeechMarkTypes=[‘word’], OutputS3BucketName=”S3-bucket-name”, OutputS3KeyPrefix=”-polly-speech-marks”) speechmarks_task_id=response[‘SynthesisTask’][‘TaskId’] Usamos novamente o método start_speech_synthesis_task mas especifique Fora putFormat para json, que informa ao Amazon Polly para gerar marcas de fala para essa chamada de API.
Na próxima etapa da segunda ramificação, invocamos a função Lambda generate_subtitles.py, que implementa a lógica para gerar um arquivo de legenda a partir da saída das marcas de fala.
Ele usa o módulo Python em o arquivo webvtt_utils.py. Este módulo possui múltiplas funções utilitárias para criar o arquivo de legenda; um desses métodos get_phrases_from_speechmarks é responsável por analisar o arquivo de marcas de fala. A estrutura JSON das marcas de fala fornece apenas a hora de início para cada palavra individualmente. Para criar o tempo de legenda necessário para o arquivo SRT, primeiro criamos frases de cerca de n (onde n=10) palavras da lista de palavras no arquivo de marcas de fala. Em seguida, os escrevemos no formato de arquivo SRT, tomando a hora de início da primeira palavra na frase e, para a hora de término, usamos a hora de início da palavra (n+1) e subtraímos por 1 para criar a entrada sequenciada. A função a seguir cria as frases em preparação para gravá-las no arquivo SRT:
def get_phrases_from_speechmarks(words, transcript):….. for item in items: # se for uma nova frase, obtenha o start_time do primeiro item if n_phrase: frase[“start_time”]=get_time_code(words[c][“start_time”]) n_phrase=False else: if c==len(words)-1:phrase[“end_time”]=get_time_code (words[c][“start_time”]) else:phrase[“end_time”]=get_time_code(words[c + 1][“start_time”]-1) # em ambos os casos, anexe a palavra à frase… frase[“palavras”].append(item) x +=1 # agora adicione a frase às frases, gere uma nova frase, etc. if x==10 ou c==(len(items)-1): # print c, frase if c==(len(items)-1): if frase[“end_time”]==”: start_time=words[c][“start_time”] end_time=int(start_time) + 500 frase[“end_time”]=get_time_code(end_time)phrases.append(phrase)phrase=new_phrase() n_phrase=True x=0….. frases de retorno A etapa final, Media Conver t, invoca a função Lambda create_mediaconvert_job.py para combinar o fluxo de áudio do Amazon Polly e o arquivo de legenda com o arquivo de vídeo de origem para gerar o arquivo de saída final, que é armazenado em um bucket do S3. Esta etapa usa o MediaConvert, um serviço de transcodificação de vídeo baseado em arquivo com recursos de nível de transmissão. Ele permite que você crie facilmente conteúdo de vídeo sob demanda e combina recursos avançados de vídeo e áudio com uma interface web simples. Aqui, novamente, usamos o SDK Boto3 do Python para crie um trabalho MediaConvert: …… job_metadata=’asset_id’: asset_id,’application’:”createMediaConvertJob”mc_client=boto3.client(‘mediaconvert’, region_name=region) endpoints=mc_client.describe_endpoints() mc_endpoint_url=endpoints[‘Endpoints’][0][‘Url’] mc=boto3.client(‘mediaconvert’, region_name=region, endpoint_url=mc_endpoint_url, Verify=True) mc.create_job(Role=mediaconvert_role_arn, UserMetadata=job_metadata, Settings=mc_data[“Settings”])
Pré-requisitos
Antes de começar, você deve ter os seguintes pré-requisitos:
Implantar a solução
Para implantar a solução usando o AWS CDK, conclua as etapas a seguir:
Clone o repositório: git clone https://github.com/aws-samples/localize-content-using-aws-ml-services.git Para garantir que o AWS CDK seja inicializado, execute o comando cdk bootstrap na raiz do repositório: $ cdk bootstrap ⏳ Bootstrapping environment aws://
Por padrão, as configurações de áudio de destino são definidas como espanhol dos EUA (es-US). Se você planeja testá-lo com um idioma de destino diferente, use o seguinte comando:
cdk deploy–parameters pollyLanguageCode=
O processo leva alguns minutos para ser concluído, após o qual ele exibe um link que você pode usar para visualizar o arquivo de vídeo de destino com o áudio traduzido e as legendas traduzidas.

Teste a solução
Para testar essa solução, usamos uma pequena parte do seguinte Vídeo AWS re:Invent 2017 do YouTube, onde o Amazon Transcribe foi introduzido pela primeira vez. Você também pode testar a solução com seu próprio vídeo. O idioma original do nosso vídeo de teste é o inglês. Ao implantar esta solução, você pode especificar as configurações de áudio de destino ou pode usar as configurações de áudio de destino padrão, que usam espanhol para gerar áudio e legendas. A solução cria um bucket do S3 que pode ser usado para fazer upload do arquivo de vídeo.
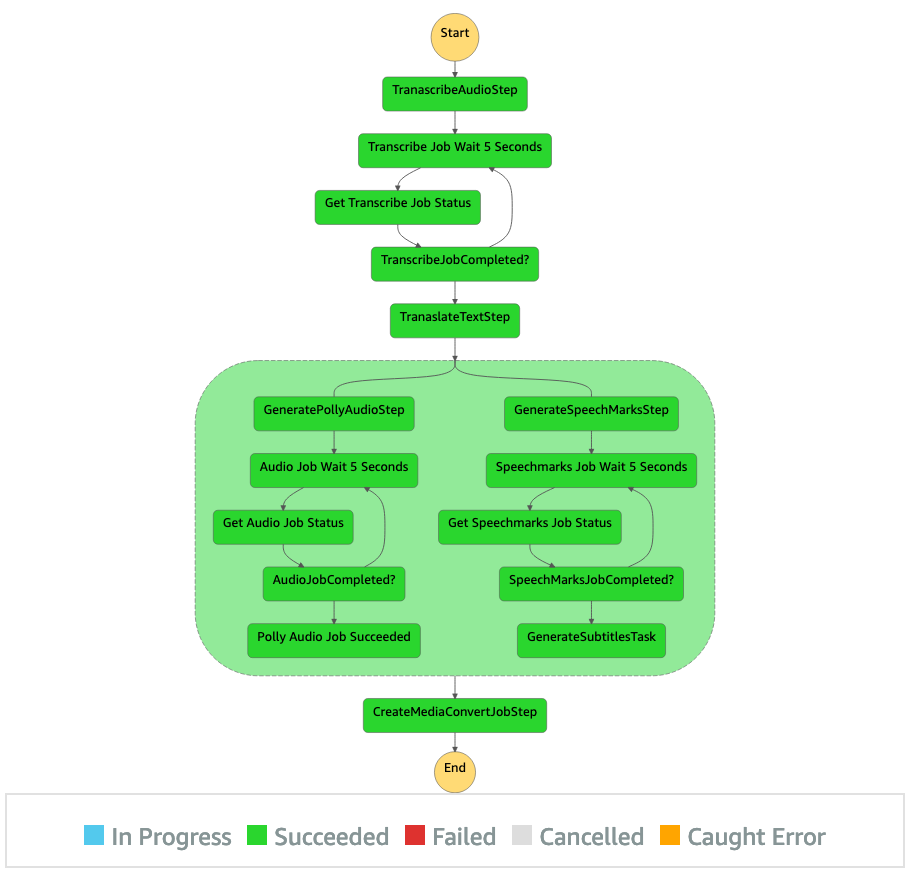
No console do Amazon S3, navegue até o bucket PollyBlogBucket. Escolha o bucket, navegue até o diretório/inputVideo e carregue o arquivo de vídeo (a solução é testada com vídeos do tipo mp4). Nesse ponto, uma notificação de evento do S3 aciona a função Lambda, que inicia a máquina de estado. No console do Step Functions, navegue até a máquina de estado (ProcessAudioWithSubtitles). Escolha uma das execuções da máquina de estado para localizar o Graph Inspector.
Escolha o bucket, navegue até o diretório/inputVideo e carregue o arquivo de vídeo (a solução é testada com vídeos do tipo mp4). Nesse ponto, uma notificação de evento do S3 aciona a função Lambda, que inicia a máquina de estado. No console do Step Functions, navegue até a máquina de estado (ProcessAudioWithSubtitles). Escolha uma das execuções da máquina de estado para localizar o Graph Inspector.
Isso mostra os resultados da execução para cada estado. O fluxo de trabalho do Step Functions leva alguns minutos para ser concluído. Depois disso, você pode verificar se todas as etapas foram concluídas com êxito.
Revisar a saída
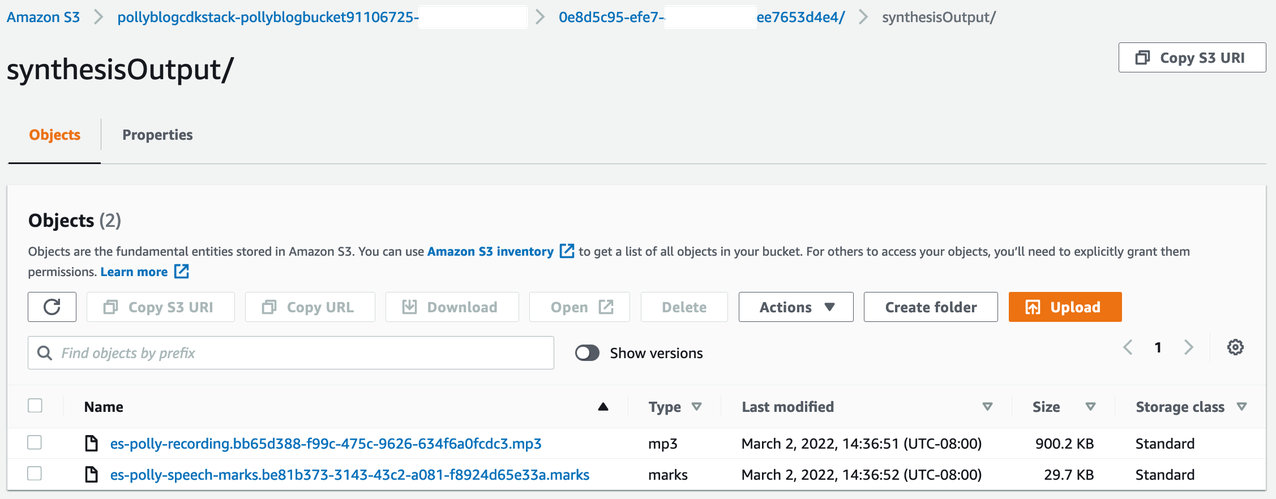
Para revisar a saída, abra o console do Amazon S3 e verifique se o arquivo de áudio (.mp3) e o arquivo de marca de fala (.marks) são armazenados no bucket do S3 em
A seguir está uma amostra do arquivo de marca de fala gerado a partir do texto traduzido xt:
“time”:6,”type”:”word”,”start”:2,”end”:6,”value”:”Qué””time”:109,”type”:”palavra”,”início”:7,”fim”:10,”valor”:”tal””tempo”:347,”tipo”:”palavra”,”início”:11,”fim”:13,”valor”:”el””time”:453,”type”:”word”,”start”:14,”end”:20,”value”:”idioma””time”:1351,”type”:”word”,”start”:22,”end”:24,”value”:”Ya””time”:1517,”type”:”word”,”start”:25,”end”:30,”value”:”sabes””tempo”:2240,”tipo”:”palavra”,”início”:32,”fim”:38,”valor”:”hablé””tempo”:2495,”tipo”:”palavra”,”start”:39,”end”:44,”value”:”antes””time”:2832,”type”:”word”,”start”:45,”end”:50,”value”:”sobre””tempo”:3125,”tipo”:”palavra”,”início”:51,”fim”:53,”valor”:”el””tempo”:3227,”tipo”:”palavra”,”start”:54,”end”:59,”value”:”hecho””time”:3464,”type”:”word”,”start”:60,”end”:62,”value”:”de”
Nesta saída, cada parte do texto é dividida em termos de marcas de fala:
tempo – O carimbo de data/hora em milissegundos do início do fluxo de áudio correspondente tipo – O tipo de marca de fala (frase, palavra, visema ou S SML) início – O deslocamento em bytes (não caracteres) do início do objeto no texto de entrada (não incluindo marcas de visema) fim – O deslocamento em bytes (não caracteres) do final do objeto no texto de entrada (sem incluir marcas de visema) valor – palavras individuais na frase
O arquivo de legenda gerado é gravado de volta no bucket do S3. Você pode encontrar o arquivo em
1 00:00:00,006–> 00:00:03,226 ¿Qué tal el idioma? Ya sabes, hablé antes sobre el 2 00:00:03,227–> 00:00:06,065 hecho de que el año pasado lanzamos Polly y Lex, 3 00:00:06,066–> 00:00:09,263 pero hay muchas otras cosas que los constructores quieren hacer 4 00:00:09,264–> 00:00:11,642 con el lenguaje. Y una de las cosas que ha 5 00:00:11,643–> 00:00:14,549 sido interessante es que ahora hay tantos dados que están
Depois que o arquivo de legendas e o arquivo de áudio são gerados, o arquivo de vídeo de origem final é criado usando o MediaConvert. Verifique o console do MediaConvert para verificar se o status do trabalho está COMPLETO.
Quando o trabalho do MediaConvert é concluído, o arquivo de vídeo final é gerado e salvo de volta no bucket do S3, que pode ser encontrado em
Como parte dessa implantação, o vídeo final é distribuído por meio de um link do Amazon CloudFront (CDN) e exibido no terminal ou no console do AWS CloudFormation.
Abra a URL em um navegador para visualizar o vídeo original com opções adicionais de áudio e legendas. Você pode verificar se o áudio e as legendas traduzidos estão sincronizados.
Conclusão
Nesta postagem, discutimos como criar novas versões de idioma de arquivos de vídeo sem a necessidade de intervenção manual. Os criadores de conteúdo podem usar esse processo para sincronizar o áudio e as legendas de seus vídeos e alcançar um público global.
Você pode integrar facilmente essa abordagem em seus próprios canais de produção para lidar com grandes volumes e dimensionar de acordo com suas necessidades. O Amazon Polly usa o Neural TTS (NTTS) para produzir vozes text-to-speech naturais e semelhantes às humanas. Ele também oferece suporte à geração de fala a partir de SSML, o que oferece controle adicional sobre como o Amazon Polly gera fala a partir do texto fornecido. O Amazon Polly também oferece uma variedade de vozes diferentes em vários idiomas para atender às suas necessidades.
Comece a usar os serviços de machine learning da AWS visitando a página do produto ou consulte a página do Amazon Machine Learning Solutions Lab, onde você pode colaborar com especialistas para trazer soluções de aprendizado de máquina para sua organização.
Recursos adicionais
Para obter mais informações sobre os serviços usados nesta solução, consulte o seguinte:
Sobre os autores
 Reagan Rosario trabalha como arquiteto de soluções na AWS com foco em empresas de tecnologia educacional. Ele adora ajudar os clientes a criar soluções escaláveis, altamente disponíveis e seguras na Nuvem AWS. Ele tem mais de uma década de experiência trabalhando em diversas funções de tecnologia, com foco em engenharia e arquitetura de software.
Reagan Rosario trabalha como arquiteto de soluções na AWS com foco em empresas de tecnologia educacional. Ele adora ajudar os clientes a criar soluções escaláveis, altamente disponíveis e seguras na Nuvem AWS. Ele tem mais de uma década de experiência trabalhando em diversas funções de tecnologia, com foco em engenharia e arquitetura de software.
 Anil Kodali é arquiteto de soluções da Amazon Web Services. Ele trabalha com clientes AWS EdTech, orientando-os com as melhores práticas de arquitetura para migrar cargas de trabalho existentes para a nuvem e projetar novas cargas de trabalho com uma abordagem que prioriza a nuvem. Antes de ingressar na AWS, ele trabalhou com grandes varejistas para ajudá-los nas migrações para a nuvem.
Anil Kodali é arquiteto de soluções da Amazon Web Services. Ele trabalha com clientes AWS EdTech, orientando-os com as melhores práticas de arquitetura para migrar cargas de trabalho existentes para a nuvem e projetar novas cargas de trabalho com uma abordagem que prioriza a nuvem. Antes de ingressar na AWS, ele trabalhou com grandes varejistas para ajudá-los nas migrações para a nuvem.
 Prasanna Saraswathi Krishnan é arquiteta de soluções da Amazon Web Services e trabalha com clientes EdTech. Ele os ajuda a conduzir sua arquitetura de nuvem e estratégia de dados usando as melhores práticas. Sua experiência é em computação distribuída, análise de big data e engenharia de dados. Ele é apaixonado por aprendizado de máquina e processamento de linguagem natural.
Prasanna Saraswathi Krishnan é arquiteta de soluções da Amazon Web Services e trabalha com clientes EdTech. Ele os ajuda a conduzir sua arquitetura de nuvem e estratégia de dados usando as melhores práticas. Sua experiência é em computação distribuída, análise de big data e engenharia de dados. Ele é apaixonado por aprendizado de máquina e processamento de linguagem natural.
Avalie esta postagem
Compartilhar é cuidar!