Introdução
Os aplicativos da web geralmente aceitam contribuições dos usuários. Na maioria dos casos, os aplicativos da web solicitam a entrada de cada usuário separadamente. Por exemplo, um aplicativo da web típico solicitará que você insira seu nome, sobrenome e endereço de e-mail durante o processo de registro.
Esse mecanismo de preenchimento de formulários veio da fase inicial da Web 2.0. Agora, para uma melhor experiência do usuário, quase todos os aplicativos estão tentando reduzir o número de entradas obrigatórias do usuário. Por exemplo, alguns aplicativos agora pedem apenas seu e-mail de login no momento do registro.
Alguns aplicativos da web realizam um processamento complexo de entrada do usuário, como analisar um arquivo de log, aceitar um texto com gramática personalizada (por exemplo, hashtags, identificadores de documentos internos e menções do usuário) e consultas de pesquisa específicas do domínio Se o requisito de correspondência de padrões for simples, podemos implementar uma solução usando expressões regulares. No entanto, se precisarmos de uma solução extensível, temos que implementar nossos próprios analisadores.
Este tutorial explicará como você pode criar um analisador para lidar com entradas de texto bruto com o kit de ferramentas ANTLR . Para demonstração, criaremos um aplicativo analisador de log simples que converterá texto bruto em saída no estilo HTML.
Conceitos de design do compilador
Antes de começar com ANTLR, devemos estar familiarizados com os seguintes princípios de design de compilador.
Tokenização
Esta é a etapa inicial genérica do processo de análise. Esta etapa aceita um fluxo de texto bruto e produz um fluxo de token. Os tokens representam a menor parte da gramática. Por exemplo, a palavra return é um token em muitas linguagens de programação.
Analisar árvore
Uma árvore de análise é uma instância de estrutura de dados em árvore que contém informações sobre os resultados analisados. Ele contém tokens e nós de analisador complexo.
Interface do compilador
Um compilador típico tem três módulos principais: front-end, middle-end e back-end. O front-end do compilador constrói uma representação interna do código-fonte usando a definição da sintaxe da linguagem.
Backend do compilador
O back-end do compilador gera o código do idioma de destino a partir da representação interna do código-fonte.
O que é ANTLR?
ANTLR (outra ferramenta para reconhecimento de linguagem) é um kit de ferramentas gerador de analisador escrito em Java. ANLTR é amplamente utilizado na indústria de desenvolvimento de software para desenvolver linguagens de programação, linguagens de consulta e correspondência de padrões. Ele gera o código do analisador a partir de sua própria gramática.
Se vamos implementar um analisador do zero, temos que escrever o código para tokenização e geração da árvore do analisador. ANTLR gera código de analisador extensível quando a especificação do idioma é fornecida. Em outras palavras, se definirmos regras explicando como precisamos analisar usando a sintaxe da gramática ANTLR, ele irá gerar automaticamente o código-fonte do analisador.
ANTLR pode gerar o código do analisador em 10 linguagens de programação diferentes . ANTLR é conhecido como código do analisador JavaScript e tempo de execução.
Tutorial ANTLR
Neste tutorial, explicarei como fazer um analisador de log simples usando ANTLR.
Vamos nomear nossa sintaxe de arquivo de log SimpleLog. Nosso programa analisador de log aceita uma entrada de log bruta. Depois disso, ele produzirá uma tabela HTML a partir do conteúdo do arquivo de log. O que significa que o tradutor SimpleLog tem um back-end de compilador para gerar uma tabela HTML a partir da árvore de análise.
Você pode seguir etapas semelhantes para fazer qualquer analisador de entrada complexo com JavaScript.
Configurando ANTLR com webpack
Se precisar usar ANTLR no back end do seu aplicativo, você pode usar o pacote npm com Node.
Caso contrário, se você precisar usar ANTLR no front end do seu aplicativo, existem várias maneiras. A maneira mais confortável e fácil é agrupar o tempo de execução ANTLR com o código-fonte do seu projeto com o webpack. Neste tutorial, vamos configurar ANTLR com webpack.
Em primeiro lugar, precisamos criar o ambiente de desenvolvimento para ANTLR. Certifique-se de instalar JRE (Java Runtime Environment) primeiro. Crie um diretório e baixe o gerador de analisador ANTLR CLI:
$ wget https://www.antlr.org/download/antlr-4.9.2-complete.jar
O comando acima é para Linux. Use um comando equivalente para fazer download do arquivo.jar para outros sistemas operacionais. Além disso, você pode baixar o arquivo específico manualmente com um navegador da web.
Crie um novo projeto npm com o comando npm init . Depois disso, adicione o seguinte conteúdo ao arquivo package.json :
{ "nome":"analisador de log", "versão":"1.0.0", "scripts": { "build":"webpack--mode=development", "gerar":"java-jar antlr-4.9.2-complete.jar SimpleLog.g4-Dlanguage=JavaScript-o src/parser" }, "dependências": { "antlr4":"^ 4.9.2", }, "devDependencies": { "@ babel/core":"^ 7.13.16", "@ babel/plugin-proposal-class-properties":"^ 7.13.0", "@ babel/preset-env":"^ 7.13.15", "babel-loader":"^ 8.2.2", "webpack":"^ 4.46.0", "webpack-cli":"^ 4.6.0" }
}
Crie webpack.config.js com o seguinte conteúdo:
const path=require ('path'); module.exports={ entrada: path.resolve (__ dirname,'./src/index.js'), módulo: { as regras: [ { teste:/\.js$/, excluir:/node_modules/, usar: { carregador:'babel-loader', opções: { presets: ['@ babel/preset-env'] } } }, ], }, resolver: { extensões: ['.js'], substituto: {fs: false} }, resultado: { nome do arquivo:'logparser.js', path: path.resolve (__ dirname,'static'), biblioteca:'LogParser', libraryTarget:'var' }
};
Precisamos ter um .babelrc também, porque ANTLR usa alguns dos recursos ECMAScript mais recentes.
Portanto, adicione o seguinte snippet a .babelrc :
{ "predefinições": [ "@ babel/preset-env" ], "plugins": [ [ "@ babel/plugin-proposal-class-properties", { "solto": verdadeiro } ] ]
}
Certifique-se de inserir npm install em seu terminal para obter as dependências necessárias, incluindo a biblioteca de tempo de execução ANTLR. Agora, nosso ambiente ANTLR tem comandos suficientes para gerar o código do analisador e construir o código-fonte final.
No entanto, ainda estamos perdendo uma peça importante. É a gramática do nosso formato de arquivo de registro. Vamos prosseguir e implementar a gramática ANTLR.
Escrevendo gramática ANTLR
Vamos supor que nosso arquivo de registro segue o seguinte formato e precisamos analisá-lo para identificar as informações necessárias:
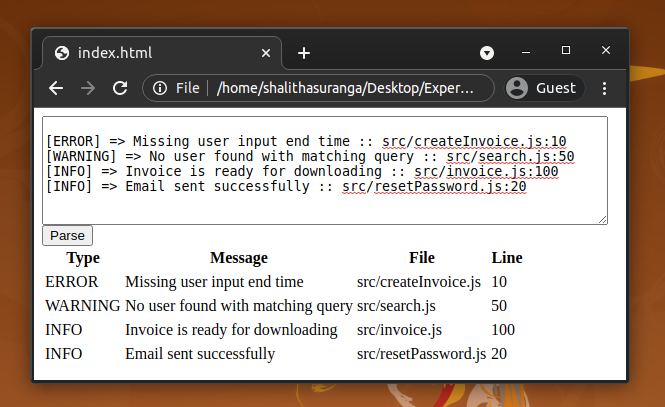
[ERROR]=> Hora de término da entrada do usuário ausente:: src/createInvoice.js: 10 [AVISO]=> Nenhum usuário encontrado com consulta correspondente:: src/search.js: 50 [INFO]=> A fatura está pronta para download:: src/invoice.js: 100 [INFO]=> Email enviado com sucesso:: src/resetPassword.js: 20
As linhas do arquivo de log acima têm três níveis de log: ERROR , WARNING e INFO . Depois disso, há uma mensagem. Por fim, temos o módulo de código e o número da linha onde o processo de registro é acionado.
Antes de escrever a gramática ANTLR para a sintaxe do arquivo de log acima, precisamos identificar os tokens. A gramática SimpleLog tem três tokens-chave, conforme mostrado abaixo:
- Tipos de registro (
ERROR,WARNINGeINFO) - Texto (
Datetime,MessageeMódulo) - dígitos (linha acionada)
Agora, temos uma ideia sobre as regras do lexer. Vamos escrever a gramática ANTLR usando os tokens acima e algumas regras de geração de árvore do analisador. Ao escrever a gramática, você pode seguir a abordagem ascendente. Em outras palavras, você pode começar com tokens e terminar com regras do analisador. Adicione a seguinte lógica gramatical a SimpleLog.g4 :
grammar SimpleLog; logEntry: logLine +; logLine:'['logType']''=>'logMessage'::'logSender; logType: (INFO | WARNING | ERROR); logMessage: TEXT + ?; logSender: logFile':'DIGITS; logFile: TEXT + ?; INFO:'INFO'; AVISO:'AVISO'; ERROR:'ERROR'; TEXTO: [a-zA-Z./]+ ?; DÍGITOS: [0-9] +; WS: [\ n \ t] +-> pular;
Palavras camelcase representam regras do analisador no arquivo de gramática SimpleLang acima. Essas regras do analisador ajudam a construir uma árvore de análise usando tokens. Bem no topo, nossa árvore de análise tem uma entrada para uma linha. Depois disso, cada nó de linha tem nós logType , logMessage e logSender .
As definições em maiúsculas são regras lexer. Essas regras lexer ajudam no processo de tokenização. Uma entrada bruta do usuário será convertida em tokens usando esses tokes, como fragmentos de texto, dígitos e tipo de registro.
Execute o seguinte comando em seu terminal a partir do diretório do projeto para acionar a geração do código do analisador:
$ npm executar gerar
Se você criar o arquivo de gramática corretamente, poderá ver o código do analisador gerado automaticamente dentro do diretório src/parser . Vamos implementar o back-end do programa tradutor SimpleLog.
Implementando um visitante da árvore
O processo de análise ANTLR irá gerar uma árvore de análise na memória. Ele também fornece uma classe de ouvinte para percorrer na árvore de análise. Precisamos criar um visitante da árvore para percorrer a árvore de análise e produzir a estrutura da tabela HTML de saída. Na teoria do compilador, isso é conhecido como processo de geração de código.
Adicione o seguinte código em src/TableGenerator.js :
import SimpleLogListener de"./parser/SimpleLogListener" classe padrão de exportação TableGenerator extends SimpleLogListener { tableSource=""; exitLogLine (ctx) { const logType=ctx.logType (). getText (); const logMessage=ctx.logMessage (). getText (); const logFile=ctx.logSender (). logFile (). getText (); const logLine=ctx.logSender (). DÍGITOS (0).getText (); this.tableSource += ` $ {logType} $ {logMessage} $ {logFile} $ {logLine} ` } getTable () { const table=` Tipo Mensagem Arquivo Linha $ {this.tableSource}
`; tabela de retorno; }
}
A classe acima estende a classe de ouvinte de base gerada automaticamente. A classe base do ouvinte possui todos os métodos relacionados à movimentação da árvore. Em nosso cenário, substituímos apenas o método exitLogLine para simplificar. Podemos obter o tipo de log, mensagem, arquivo e número de linha do método exitLogLine . O processo de escrita do código é conhecido como emissão. Aqui, estamos emitindo a sintaxe da tabela HTML da classe Tree Walker.
Finalizando a biblioteca do analisador SimpleLog
Estamos preparando uma biblioteca cliente com webpack porque precisamos usar a lógica do analisador diretamente no navegador. Agora precisamos de um ponto de entrada público para nossa biblioteca. Vamos expor o método LogParser.parse () para o navegador.
Adicione o seguinte código a src/index.js , que é nosso ponto de entrada da biblioteca do analisador:
importar antlr4 de'antlr4';
importar SimpleLogLexer de'./parser/SimpleLogLexer';
importar SimpleLogParser de'./parser/SimpleLogParser';
importar TableGenerator de'./TableGenerator'; export deixe parse=(input)=> { const chars=novo antlr4.InputStream (entrada); const lexer=novo SimpleLogLexer (chars); tokens const=novo antlr4.CommonTokenStream (lexer); const parser=new SimpleLogParser (tokens); parser.buildParseTrees=true; const tree=parser.logEntry (); const tableGenerator=new TableGenerator (); antlr4.tree.ParseTreeWalker.DEFAULT.walk (tableGenerator, árvore); return tableGenerator.getTable ();
}
O método de análise aceita uma entrada bruta e retorna a estrutura da tabela HTML de acordo. Agora, nossa biblioteca de analisadores está completa.
Execute o seguinte comando em seu terminal para criar um único arquivo-fonte JavaScript a partir do código-fonte:
$ npm run build
O arquivo JavaScript resultante será salvo em static/logparser.js .
Finalmente, podemos implementar a interface gráfica do usuário (GUI) de nosso programa analisador SimpleLog.
Desenvolvendo o aplicativo da web analisador SimpleLog
Nosso aplicativo da web tem três componentes principais: a área de texto, o botão de análise e a área de resultados. Eu construí uma interface simples usando HTML simples e JavaScript básico para este programa de exemplo.
Adicione os seguintes códigos HTML e JavaScript ao arquivo static/index.html :
Parabéns! nosso aplicativo da web analisador SimpleLog agora está pronto. O aplicativo da web pode ser iniciado por meio de um servidor de arquivos estático ou apenas clicando duas vezes no arquivo HTML. Tente copiar e colar uma entrada de amostra. Depois disso, clique no botão Analisar para obter uma versão HTML do texto bruto.
O código-fonte completo do projeto está disponível em GitHub .
Conclusão
Também podemos usar ANTLR para analisar entradas de texto bruto dos usuários. Existem vários tipos de casos de uso de ANTLR. Este tutorial explicou um exemplo simples. A mesma abordagem pode ser usada para fazer transpiladores da web, web scraping avançado, correspondência de padrões complexos e linguagens de consulta baseadas na web para construir aplicativos da web de próximo nível.
Você está tentando criar uma linguagem de consulta personalizada para seu aplicativo da web? Experimente o ANTLR.
A postagem Analisando entradas de texto bruto em aplicativos da web que usam ANTLR apareceram primeiro no LogRocket Blog .
Categories: UncategorizedWordpress
Related Posts
IT Info
Esses fundos de vídeo imersivos em 360 graus do Google Meet são incríveis
Reconhecidamente, este será um começo lento, mas o Google está lançando dois planos de fundo virtuais incrivelmente legais para o Google Meet no Android e no iOS que permitem aos usuários não apenas alterar seus Read more…
IT Info
Quase 25% das novas criptomoedas em 2022 poderiam ter sido’bombas e despejos’, revela estudo
De acordo com o estudo mais recente conduzido pela Chainalysis, usuários involuntários gastaram cerca de US$ 4,6 bilhões em criptomoedas, adquirindo-as em esquemas fraudulentos no ano passado, que resultaram na criação de mais de 1,1 Read more…
IT Info
OpenSea Anuncia Taxas de Negociação de 0% e Corta Ganhos de Criadores
O principal mercado de NFT, OpenSea, fez alguns anúncios importantes nas últimas horas. Por meio de sua conta oficial no Twitter, a OpenSea listou várias alterações em sua estrutura de taxas e royalties, que devem Read more…