Hoje em dia, você não precisa saber como configurar um servidor e banco de dados do zero para construir aplicativos full-stack. O surgimento da tecnologia sem servidor tornou mais fácil dimensionar seu aplicativo sem o incômodo de gerenciar a infraestrutura manualmente. No mundo moderno da tecnologia, tudo é orientado por API.
Existem muitas ferramentas disponíveis para ajudá-lo a criar aplicativos escaláveis sem a complexidade e os custos operacionais normalmente associados ao desenvolvimento full-stack. Escolher a solução mais adequada com base nos requisitos do seu projeto pode evitar muitas dores de cabeça e dívidas técnicas no futuro.
Neste guia, compararemos Firebase e Fauna, avaliando cada ferramenta quanto à curva de aprendizado, complexidade, escalabilidade, desempenho e preços.
O que é Firebase?
Firebase é uma ferramenta de backend como serviço (BaaS) que oferece uma variedade de serviços, incluindo autenticação, bancos de dados em tempo real, crashlytics, armazenamento e funções de nuvem sem servidor, para citar alguns.
- Realtime Database e Cloud Firestore são usados para armazenar dados estruturados de documentos e sincronizar aplicativos
- Cloud Functions são funções sem servidor para implantar lógica de negócios personalizada
- Firebase Hosting permite que você implante conteúdo estático e dinâmico
- Cloud Storage é para armazenar e servir grandes volumes de dados gerados pelo usuário conteúdo, como fotos e vídeos
O que é Fauna?
Fauna (anteriormente FaunaDB) é uma estrutura de aplicativo sem servidor que fornece uma camada de API GraphQL sobre o bases de dados tradicionais. Além disso, ele transforma o DBMS em uma API de dados que oferece todos os recursos de que você precisa para operar o banco de dados.
Fauna fornece:
- Vários modelos para manipular dados
- Várias APIs para acesso a dados, incluindo GraphQL nativo
- Forte consistência de dados
- Autenticação integrada
Para demonstrar as vantagens e desvantagens de usar Firebase e Fauna, mostraremos como criar um aplicativo de exemplo com cada banco de dados.
Abaixo está uma rápida demonstração do que iremos construir:
React e Firebase
No mundo do front-end, é comum usar React com Firebase porque permite que os desenvolvedores de front-end criem aplicativos full-stack. Firebase é uma ferramenta BaaS que torna mais fácil para desenvolvedores da web e de dispositivos móveis implementar funcionalidades comuns, como autenticação, armazenamento de arquivos e operações do banco de dados CRUD .
Para um mergulho mais profundo, incluindo a configuração do Firebase e a configuração inicial, consulte “ Primeiros passos com react-redux-firebase . ”
Diagrama de componentes do Firebase
Vamos começar com os diagramas de entidade/relacionamento e componentes:

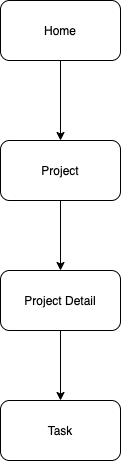
Primeiro, crie firebase.js no diretório raiz e adicione o seguinte código:
importar firebase de"firebase";
const config={ apiKey:"API_KEY", authDomain:"AUTH_DOMAIN", databaseURL:"DATABASE_URL", projectId:"PROJECT_ID", storageBucket:"STORAGE_BUCKET", messagingSenderId:"MESSAGING_SENDER_ID", appId:"APP ID",
};
//Inicialize o Firebase
firebase.initializeApp (config);
exportar firebase padrão;
Depois de configurar o Firebase, você pode usá-lo diretamente em seus componentes.
Lendo dados do Firebase
Para a próxima etapa, buscaremos todos os dados do projeto no Firebase:
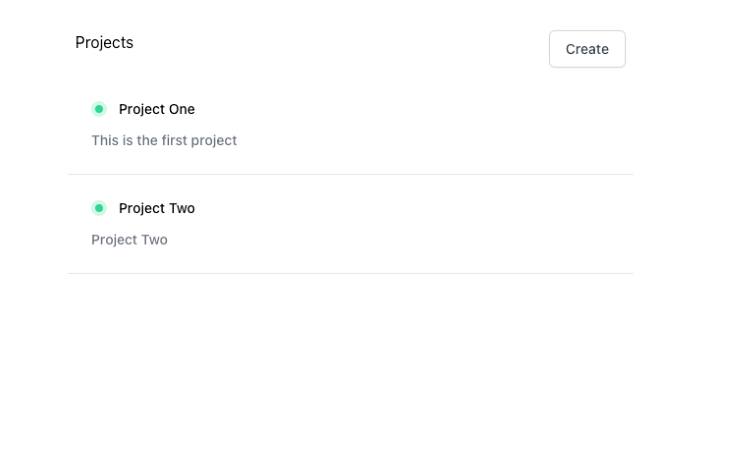
useEffect (()=> { const fetchData=async ()=> { setLoading (true); const db=firebase.firestore (); const data=await db.collection ("projetos"). get (); setProjects (data.docs.map ((doc)=> ({... doc.data (), id: doc.id}))); setLoading (false); }; fetchData (); }, []);
Conecte-se ao Firebase usando o seguinte código:
const db=firebase.firestore ();
Depois que o Firebase estabelece uma conexão de banco de dados, podemos buscar os dados de uma coleção específica usando o código abaixo:
const data=await db.collection ("projects"). get ();
Gravando dados no Firebase
Inserir dados no Firebase é tão simples quanto ler dados. Primeiro, crie um projeto:
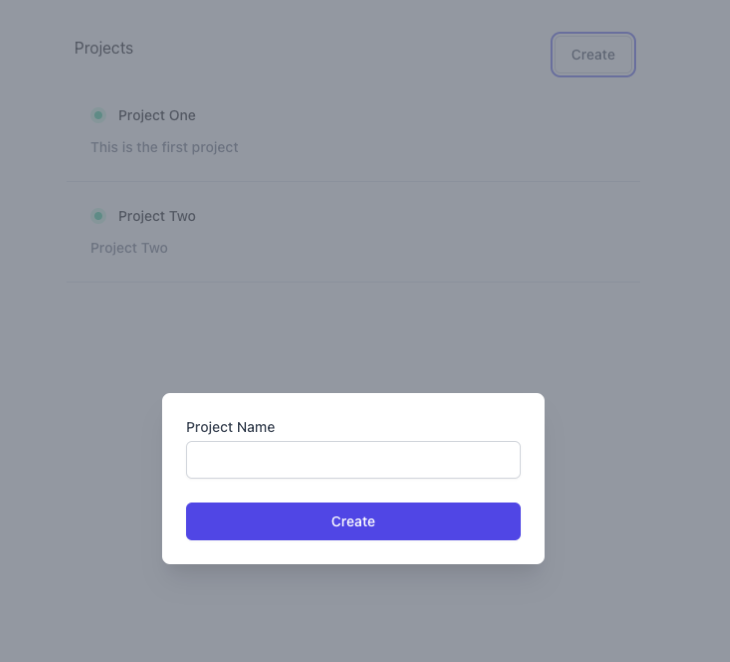
Adicione o seguinte código ao onClick função :
const db=firebase.firestore ();
db.collection ("projetos") .add ({nome}) .então (assíncrono (res)=> { //a lógica do componente vem aqui// setModalState (! modalState); toast.success ("Projeto criado com sucesso"); }) .catch ((errar)=> { toast.error ("Ops! Algo deu errado"); console.log ("errar", errar); });
Podemos usar a função add do Firebase para adicionar dados à coleção especificada.
Atualização de dados no Firebase
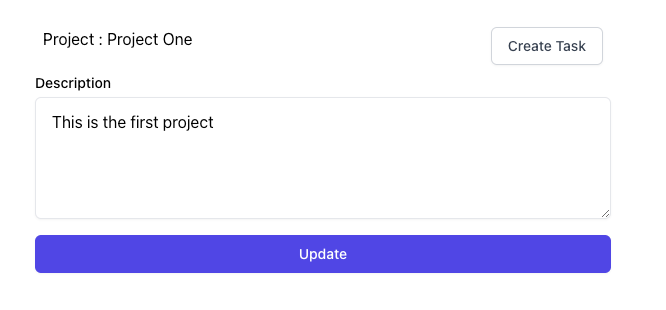
Para atualizar os dados no Firebase, use a função set :
const db=firebase.firestore (); db.collection ("projetos") .doc (id) .definir( { descrição: project.description, }, {mesclar: verdadeiro} ) .então ((res)=> { toast.success ("Projeto atualizado com sucesso"); }) .catch ((err)=> { toast.error ("Ops! Algo deu errado"); console.log ("Erro ao atualizar o projeto", err); });
A opção merge nos permite adicionar os novos dados junto com os dados existentes. Caso contrário, ele substituiria os dados.
Transação do Firebase ACID
Transações de suporte do Firebase. Você pode agrupar uma operação de configuração para manter a consistência dos dados. Por exemplo, se você excluir um projeto, também precisará excluir todas as tarefas associadas a ele. Portanto, você precisa executá-lo como uma transação.
Existem algumas coisas importantes a serem observadas sobre as transações:
- As operações de leitura devem vir antes das operações de gravação
- Uma função que chama uma transação (função de transação) pode ser executada mais de uma vez se uma edição simultânea afetar um documento lido pela transação
- As funções de transação não devem modificar diretamente o estado do aplicativo
- As transações falharão quando o cliente estiver offline
var sfDocRef=db.collection ("projetos"). doc (); return db.runTransaction ((transação)=> { //Este código pode ser executado novamente várias vezes se houver conflitos. retornar transaction.get (sfDocRef).then ((sfDoc)=> { if (! sfDoc.exists) { lance"O documento não existe!"; } //exclua tarefas aqui });
}). então (()=> { console.log ("Transação confirmada com sucesso!");
}). catch ((erro)=> { console.log ("Falha na transação:", erro);
});
Configuração de fauna
Antes de começarmos a configurar o Fauna para nosso aplicativo de exemplo, devemos criar uma conta, banco de dados e coleção em Painel .
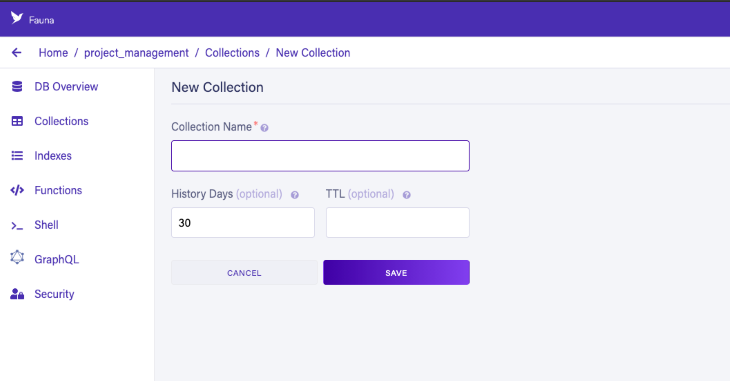
Agora é hora de configurar o Fauna. Estruturaremos nosso aplicativo da seguinte maneira:
configcomponentsapi
config terá Fauna configurada e api conterá todas as consultas para db . Crie db.js e adicione o seguinte:
importar Fauna de"Fauna";
const client=new Fauna.Client ({ segredo: process.env.REACT_APP_Fauna_KEY,
});
const q=Fauna.query;
exportar {cliente, q};
Criação de dados na Fauna
A seguir, criaremos APIs para as operações de leitura, inserção e atualização.
import {client, q} from"../config/db";
const createProject=(nome)=> cliente .inquerir( q.Create (q.Collection ("projetos"), { dados: { nome, }, }) ) .então ((ret)=> ret) .catch ((err)=> console.error (err));
exportar createProject padrão;
Cada consulta no Fauna começa com client.query . Para inserir dados no banco de dados, use q.Create para envolver a coleção e os dados:
q.Create (, {})
Lendo dados da Fauna
Existem duas maneiras de ler os dados da Fauna:
- Busque todos os dados usando índices
- Busque os dados diretamente da coleção, desde que você tenha o
id
A busca de dados usando índices é recomendada quando você precisa buscar todos os dados, ao invés de algo específico.
import {client, q} from"../config/db";
const getAllProjects=client .query (q.Paginate (q.Match (q.Ref ("indexes/all_projects")))) .então ((resposta)=> { console.log ("resposta", resposta); const notesRefs=response.data; const getAllProjectsDataQuery=notesRefs.map ((ref)=> { return q.Get (ref); }); //consulta os refs retornar client.query (getAllProjectsDataQuery).then ((dados)=> dados); }) .catch ((erro)=> console.warn ("erro", erro.mensagem));
exportar getAllProjects padrão;
Aqui, buscamos todos os dados do projeto usando o índice de coleção. Por padrão, podemos paginar os dados usando q.Paginate e buscar todos os dados que correspondem a indexes/all_projects .
Se tivermos o id , podemos buscar os dados da seguinte maneira:
client.query ( q.Get (q.Ref (q.Collection ('projetos'), ))
)
.então ((ret)=> console.log (ret))
Relações um-para-muitos na Fauna
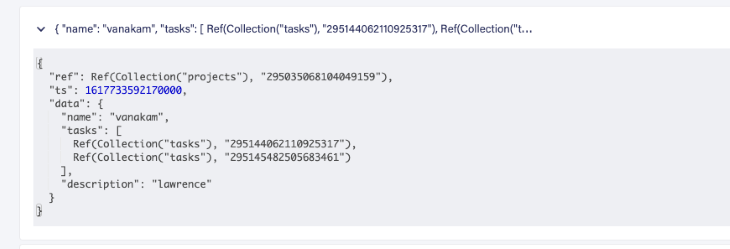
Um relacionamento é um conceito crucial ao projetar o banco de dados e seu esquema. Aqui, temos uma entidade projeto e tarefa com um relacionamento um-para-muitos. Existem duas maneiras de projetar nosso banco de dados para esse relacionamento: você pode adicionar IDs de tarefa à coleção de projetos como uma matriz ou adicionar a ID de projeto aos dados de cada tarefa.
Veja como adicionar IDs de tarefa à coleção do projeto como uma matriz:
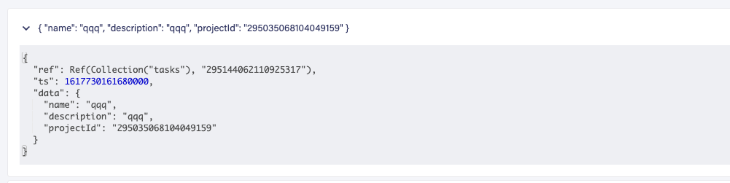
E aqui está como adicionar o ID do projeto aos dados de cada tarefa:
Vamos seguir o primeiro método e adicionar os IDs das tarefas à coleção do projeto:
import {client, q} from"../config/db";
const createTask=async (projectId, nome, descrição)=> { tentar { const taskData=await client.query ( q.Create (q.Collection ("tasks"), { dados: { nome, Descrição, projectId, }, }) ); deixe res=await client.query ( q.Deixe ( { projectRef: q.Ref (q.Collection ("projects"), projectId), projectDoc: q.Get (q.Var ("projectRef")), array: q.Select (["data","tasks"], q.Var ("projectDoc"), []), }, q.Update (q.Var ("projectRef"), { dados: { tarefas: q.Append ( [q.Ref (q.Collection ("tarefas"), taskData.ref.value.id)], q.Var ("matriz") ), }, }) ) ); return taskData; } catch (errar) { console.error (err); }
};
exportar criarTask padrão;
Primeiro, insira os dados na coleção de tarefas:
const taskData=await client.query ( q.Create (q.Collection ("tasks"), { dados: { nome, Descrição, projectId, }, }) );
Em seguida, adicione o ID da tarefa à coleção do projeto:
deixe res=esperar client.query ( q.Deixe ( { projectRef: q.Ref (q.Collection ("projects"), projectId), projectDoc: q.Get (q.Var ("projectRef")), array: q.Select (["data","tasks"], q.Var ("projectDoc"), []), }, q.Update (q.Var ("projectRef"), { dados: { tarefas: q.Append ( [q.Ref (q.Collection ("tarefas"), taskData.ref.value.id)], q.Var ("matriz") ), }, }) ) );
O Let função vincula uma ou mais variáveis em um único valor ou expressão.
Atualizando dados na Fauna
Para atualizar os dados na Fauna, use a seguinte consulta:
aguarde client.query ( q.Update (q.Ref (q.Collection ("projects"), projectId), { descrição de dados }, }) );
Cobrimos todas as funcionalidades envolvidas em um aplicativo CRUD usando Firebase e Fauna. Você pode encontrar o código-fonte completo para este exemplo no GitHub .
Agora que entendemos como eles funcionam, vamos comparar Firebase x Fauna e avaliar seus prós e contras.
Firebase vs Fauna
Antes de começarmos a comparar Firebase e Fauna, é importante notar que essas são apenas minhas opiniões com base em preferências pessoais, minha própria análise e minha experiência ao construir o aplicativo de exemplo, conforme descrito acima. Outros podem discordar e você pode expressar sua opinião nos comentários.
Curva de aprendizado
O Firebase é fácil de aprender e adaptar porque a maioria de suas funções são semelhantes às funções JavaScript. Por exemplo:
-
get ()recupera dados do Firebase -
set ()insere dados no Firebase -
update ()atualiza dados no Firebase
A fauna, por outro lado, tem uma curva de aprendizado bastante íngreme. Você pode usar GraphQL ou Fauna Query Language (FQL). Leva algum tempo para entender os conceitos e aprender como funciona o FQL. Mas, uma vez que você tenha uma boa compreensão disso, torna-se fácil escrever consultas complexas em muito menos tempo,
Configuração e escalabilidade
A configuração do Firebase e do Fauna no lado do cliente é simples e direta. Ambos os bancos de dados são projetados para construir soluções de back-end escalonáveis. Na minha opinião, Fauna é a melhor escolha para a construção de aplicações complexas. Vou explicar o porquê em breve.
O Fauna funciona bem com GraphQL e pode ser servido com CDNs globais de baixa latência. O Firebase é rápido, ágil e fácil de configurar em comparação com o Fauna.
Consultas e operações complexas
Conforme seu aplicativo cresce, você pode encontrar a necessidade de escrever algumas consultas complexas para coisas como:
- Buscando dados agregados para gerar relatórios
- Tratamento de pagamentos
- Consultas transacionais
- agregação
Como você pode ver em nosso exemplo acima, o Fauna pode lidar com consultas e operações complexas de maneira eficiente. Fauna é um banco de dados distribuído que pode ser um banco de dados relacional, de documentos e gráficos.
Uma das principais características do Fauna é sua capacidade de lidar com transações ACID, e é por isso que pode lidar facilmente com consultas complexas.
As funções no Fauna, como Lambda () , Let () e Select () , por exemplo, permitem que você escreva consultas poderosas com menos código.
Preços
O nível gratuito da Fauna inclui 100.000 leituras, 50.000 gravações e 500.000 operações de computação. Para empresas individuais, US $ 23 por mês cobrem a maioria das operações.
O Firebase inclui 50.000 leituras, 20.000 gravações e 1 GB de armazenamento, que cobre a operação. É baseado no modelo de pagamento conforme o crescimento.
Suporte e comunidade
Tanto o Firebase quanto o Fauna têm suporte e documentação excelentes. A comunidade Firebase é madura e grande em comparação com o Fauna, pois tanto os desenvolvedores da Web quanto os de dispositivos móveis a utilizam amplamente. O Fauna tem uma documentação particularmente boa que ajuda você a entender os conceitos básicos facilmente.
Firebase vs. Fauna: qual é melhor?
O Firebase é mais adequado se você planeja usar menos consultas complexas e precisa criar um aplicativo rapidamente. Portanto, é uma boa escolha quando seu aplicativo tem um nível limitado de integração. Da mesma forma, se você precisa desenvolver um protótipo rápido ou um aplicativo em pequena escala em um curto prazo, o Firebase é a melhor solução porque vem com baterias incluídas.
Fauna é ideal quando seu aplicativo requer um alto grau de escalabilidade para lidar com consultas complexas. Ele pode lidar com um banco de dados multimodelo com todos os modelos disponíveis a partir de uma única consulta. O Fauna é especialmente útil se você precisar construir um aplicativo escalonável que possa lidar com uma estrutura de banco de dados relacional. Observe, no entanto, que o Fauna não oferece um banco de dados local.
A postagem Firebase e Fauna: Comparando ferramentas de banco de dados para desenvolvedores de front-end apareceram primeiro no LogRocket Blog .