Os dados são o combustível que move um negócio. A análise baseada em dados ajuda a decidir se uma organização está acompanhando a concorrência ou ficando para trás. Para descobrir o verdadeiro valor dos dados corporativos e do cliente e tomar as melhores decisões, aprendizado de máquina é a resposta.
Processo de aprendizado de máquina
Existem cinco etapas principais no processo de aprendizado de máquina:
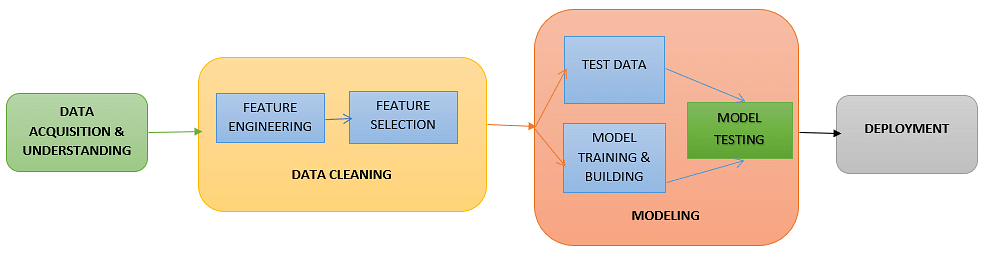
Fig: Processo de aprendizado de máquina ( fonte )
Etapa 1: Aquisição de dados
A primeira etapa no processo de aprendizado de máquina é obter os dados . Isso dependerá do tipo de dados que você está coletando e da fonte dos dados. Podem ser dados estáticos de um banco de dados existente ou dados em tempo real de um sistema IoT ou dados de outros repositórios.
Programa de pós-graduação em IA e máquina Aprendizagem
Em parceria com a Purdue University Explorar o curso
Etapa 2: Limpeza de dados
Todos os dados do mundo real geralmente são desorganizados, redundantes ou têm elementos ausentes. Para alimentar os dados no modelo de aprendizado de máquina, precisamos primeiro limpar, preparar e manipular os dados. Essa é a etapa mais importante no fluxo de trabalho do aprendizado de máquina e também ocupa a maior parte do tempo. Ter dados limpos significa que você pode obter um modelo mais preciso no futuro.
Os dados podem estar em qualquer formato-CSV, XML, JSON, etc. Depois de limpar os dados, você precisa convertê-los em formatos válidos que podem ser alimentados no plataforma de aprendizado de máquina . Por fim, esses conjuntos de dados são divididos em conjuntos de dados de treinamento e teste. O conjunto de dados de treinamento é usado para treinar o modelo. O conjunto de dados de teste é usado para validar o modelo.
Aqui estão algumas coisas para ter em mente ao dividir o conjunto de dados em conjuntos de treinamento e teste:
- O intervalo de divisão é geralmente de 20% a 80% entre os estágios de teste e treinamento
- Você não pode misturar ou reutilizar os mesmos dados para o conjunto de dados de teste e treinamento
- Usar os mesmos dados para ambos os conjuntos de dados pode resultar em um modelo com defeito
Etapa 3: treinamento do modelo
A próxima etapa no fluxo de trabalho do aprendizado de máquina é treinar o modelo. Um algoritmo de aprendizado de máquina é usado em o conjunto de dados de treinamento para treinar o modelo. Este algoritmo aproveita a modelagem matemática para aprender e prever comportamentos. Esses algoritmos podem se enquadrar em três grandes categorias-binário, classificação e regressão.
Etapa 4: Teste do modelo
Depois que o modelo é treinado, precisamos testá-lo e validá-lo para processamento posterior. Usando o conjunto de dados de teste obtido na Etapa 3, podemos verificar a precisão do modelo. Se os resultados não forem satisfatórios, o modelo deve ser melhorado. O modelo é treinado e melhorado continuamente até que os resultados sejam satisfatórios.
Aqui estão algumas coisas que você pode fazer para refinar e melhorar o modelo:
- Revise o modelo com as partes interessadas da empresa e receba suas opiniões
- Reconsidere o algoritmo que você escolheu para treinar o modelo
- Ajuste os parâmetros do algoritmo que você escolheu (mesmo pequenos ajustes podem ter impactos significativos)
Etapa 5: implantação
Assim que o modelo for treinado, implante e canalize-o para produção para consumo do aplicativo.
O processo de aprendizado de máquina que descrevemos aqui é um processo bastante padrão. Conforme você percorre esse processo por conta própria com seus próprios problemas, começará a descobrir mais alguns etapas de aprendizado de máquina que podem funcionar para você. Por exemplo, ao limpar seus dados, você pode encontrar perguntas melhores para fazer ou alimentar o modelo. Conforme você ajusta seu modelo, pode perceber que precisa de mais dados e assim por diante. O importante é continuar iterando até encontrar um modelo que se adapte mais ao seu projeto.
Curso grátis: algoritmos de aprendizado de máquina
Aprenda os fundamentos dos algoritmos de aprendizado de máquina Inscreva-se agora
Abordagens de aprendizado de máquina
O aprendizado de máquina tem dois tipos principais de abordagens-aprendizado supervisionado e aprendizado não supervisionado.
Aprendizagem supervisionada
O aprendizado de máquina supervisionado treina um modelo em dados de entrada e saída conhecidos para que os resultados futuros possam ser previstos. Depois que o modelo é treinado com dados conhecidos, você pode usar dados desconhecidos no futuro e prever as respostas.
Aqui está a lista dos principais algoritmos usados atualmente para aprendizagem supervisionada:
- K-vizinhos mais próximos
- Regressão linear
- Regressão logística
- Naive Bayes
- Regressão polinomial
- Floresta aleatória
- Árvores de decisão
Aprendizagem não supervisionada
Na aprendizagem não supervisionada, os dados usados para treinar o modelo são desconhecidos e não rotulados. Isso significa que os dados nunca foram trabalhados antes. É usado principalmente para encontrar padrões ou estruturas ocultas nos dados.
Aqui está a lista dos principais algoritmos usados atualmente para aprendizagem não supervisionada:
- Apriori
- Análise do componente principal
- Meio difuso
- Mínimos quadrados parciais
- Decomposição de valor singular
- agrupamento K-means
- Apriori
- Clustering hierárquico
Qual algoritmo escolher?
Existem tantos algoritmos por aí e escolher o certo pode parecer complicado às vezes. Não existe um tamanho que sirva para todos e encontrar o melhor algoritmo é, em parte, um método de tentativa e erro. No entanto, a seleção do algoritmo depende do tipo e tamanho dos conjuntos de dados e dos insights que você deseja derivar dos dados.
Aqui estão algumas diretrizes sobre como escolher entre aprendizado de máquina supervisionado e não supervisionado:
- Algoritmos de aprendizado supervisionado podem ser usados se você quiser treinar um modelo para fazer uma previsão ou uma classificação. Por exemplo, identificar carros a partir de filmagens da web, prever preços de ações, etc.
- Algoritmos de aprendizado não supervisionado podem ser usados se você quiser explorar os dados que possui e encontrar uma boa representação interna. Por exemplo, dividir um conjunto de dados em clusters.
Acelere sua carreira em IA e ML com o Programa de Pós-Graduação em IA e aprendizado de máquina com a Purdue University em colaboração com a IBM.
O que você pode fazer a seguir?
O aprendizado de máquina é um processo altamente interativo que aprende com experiências anteriores. O problema com o processo de aprendizado de máquina é que se trata de fazer as perguntas certas. Depois disso, você precisa dos dados corretos para responder às perguntas e, em seguida, começar as iterações de teste até obter o modelo desejado. Para se tornar um especialista em aprendizado de máquina, você precisa ser treinado em todas essas etapas. Se você estiver interessado em saber mais sobre aprendizado de máquina, o O curso de certificação em aprendizado de máquina fornecerá a você todas as habilidades necessárias para se tornar um engenheiro de aprendizado de máquina. Este programa contém 58 horas de aprendizagem aplicada, laboratórios interativos, 4 projetos práticos e mentoria. Comece com este curso hoje para garantir seu sucesso neste campo.
