Apache Spark é um mecanismo de análise unificado para processar grandes volumes de dados. Ele pode executar cargas de trabalho 100 vezes mais rápido e oferece mais de 80 operadores de alto nível que facilitam a construção de aplicativos paralelos. O Spark pode ser executado no Hadoop, Apache Mesos, Kubernetes, autônomo ou na nuvem e pode acessar dados de várias fontes.
E este artigo cobre as perguntas mais importantes da entrevista do Apache Spark que você pode enfrentar em uma entrevista do Spark. As perguntas da entrevista do Spark foram segregadas em diferentes seções com base nos vários componentes do Apache Spark e, certamente, depois de ler este artigo, você será capaz de responder à maioria das perguntas feitas em sua próxima entrevista do Spark.
Perguntas da entrevista do Apache Spark
As perguntas da entrevista do Apache Spark foram divididas em duas partes:
- Perguntas da entrevista do Apache Spark para iniciantes
- Perguntas da entrevista do Apache Spark para experientes
Vamos começar com algumas perguntas básicas da entrevista do Apache Spark!
Perguntas da entrevista do Apache Spark para iniciantes
1. Qual é a diferença entre o Apache Spark e o MapReduce?
|
Apache Spark |
<"MapReduce |
|
O Spark processa dados em lotes e também em tempo real |
MapReduce processa dados em lotes apenas |
|
O Spark é executado quase 100 vezes mais rápido do que o Hadoop MapReduce |
Hadoop MapReduce é mais lento quando se trata de processamento de dados em grande escala |
|
O Spark armazena dados na RAM, ou seja, na memória. Portanto, é mais fácil recuperá-lo |
Os dados do Hadoop MapReduce são armazenados no HDFS e, portanto, demoram muito para recuperar os dados |
|
O Spark fornece cache e armazenamento de dados na memória |
O Hadoop é altamente dependente do disco |
2. Quais são os componentes importantes do ecossistema Spark?
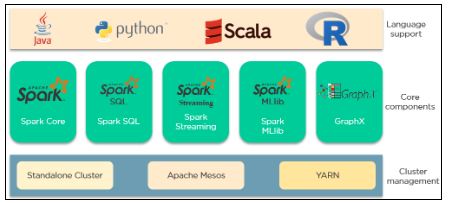
O Apache Spark possui 3 categorias principais que compõem seu ecossistema. São eles:
- Suporte a idiomas : o Spark pode se integrar com diferentes idiomas aos aplicativos e realizar análises. Essas linguagens são Java, Python, Scala e R.
- Componentes principais : o Spark oferece suporte a 5 componentes principais principais. Existem Spark Core, Spark SQL, Spark Streaming, Spark MLlib e GraphX.
- Gerenciamento de cluster : o Spark pode ser executado em 3 ambientes. Esses são o cluster autônomo, Apache Mesos e YARN.
3. Explique como o Spark executa aplicativos com a ajuda de sua arquitetura.
Esta é uma das perguntas mais frequentes da entrevista de início e o entrevistador espera que você dê uma resposta completa a ela.
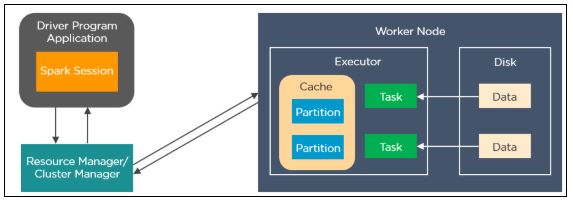
Os aplicativos Spark são executados como processos independentes coordenados pelo objeto SparkSession no programa de driver. O gerenciador de recursos ou gerenciador de cluster atribui tarefas aos nós de trabalho com uma tarefa por partição. Os algoritmos iterativos aplicam operações repetidamente aos dados para que possam se beneficiar do armazenamento de conjuntos de dados em iterações. Uma tarefa aplica sua unidade de trabalho ao conjunto de dados em sua partição e gera um novo conjunto de dados de partição. Finalmente, os resultados são enviados de volta ao aplicativo do driver ou podem ser salvos no disco.
4. Quais são os diferentes gerenciadores de cluster disponíveis no Apache Spark?
- Modo autônomo : por padrão, os aplicativos enviados ao cluster de modo autônomo serão executados em ordem FIFO e cada aplicativo tentará usar todos os nós disponíveis. Você pode iniciar um cluster autônomo manualmente, iniciando um mestre e trabalhadores manualmente, ou usar nossos scripts de inicialização fornecidos. Também é possível executar esses daemons em uma única máquina para teste.
- Apache Mesos : Apache Mesos é um projeto de código aberto para gerenciar clusters de computador e também pode executar aplicativos Hadoop. As vantagens de implantar o Spark com Mesos incluem particionamento dinâmico entre o Spark e outras estruturas, bem como particionamento escalonável entre várias instâncias do Spark.
- Hadoop YARN : Apache YARN é o gerenciador de recursos de cluster do Hadoop 2. Spark também pode ser executado no YARN.
- Kubernetes : Kubernetes é um sistema de código aberto para automatizar a implantação, escalonamento e gerenciamento de aplicativos em contêineres.
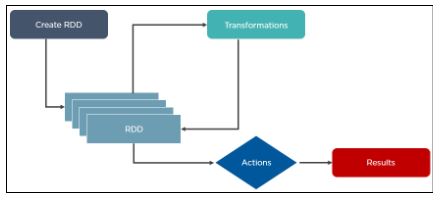
5. Qual é a importância dos conjuntos de dados distribuídos resilientes no Spark?
Conjuntos de dados distribuídos resilientes são a estrutura de dados fundamental do Apache Spark. Ele está embutido no Spark Core. Os RDDs são imutáveis, tolerantes a falhas e coleções de objetos distribuídos que podem ser operados em paralelo. Os RDDs são divididos em partições e podem ser executados em diferentes nós de um cluster.
Os RDDs são criados pela transformação de RDDs existentes ou pelo carregamento de um conjunto de dados externo de armazenamento estável, como HDFS ou HBase.
Esta é a aparência da arquitetura de RDD:
6. O que é uma avaliação preguiçosa no Spark?
Quando o Spark opera em qualquer conjunto de dados, ele se lembra das instruções. Quando uma transformação como map () é chamada em um RDD, a operação não é executada instantaneamente. As transformações no Spark não são avaliadas até que você execute uma ação, que ajuda a otimizar o fluxo de trabalho geral de processamento de dados, conhecido como avaliação lenta.
7. O que torna o Spark bom em cargas de trabalho de baixa latência, como processamento de gráficos e aprendizado de máquina?
O Apache Spark armazena dados na memória para processamento mais rápido e construção de modelos de aprendizado de máquina. Os algoritmos de aprendizado de máquina requerem várias iterações e diferentes etapas conceituais para criar um modelo ideal. Algoritmos de gráfico percorrem todos os nós e arestas para gerar um gráfico. Essas cargas de trabalho de baixa latência que precisam de várias iterações podem levar a um melhor desempenho.
8. Como você pode acionar limpezas automáticas no Spark para lidar com metadados acumulados?
Para acionar as limpezas, você precisa definir o parâmetro spark.cleaner.ttlx .
9. Como você pode conectar o Spark ao Apache Mesos?
Há um total de 4 etapas que podem ajudá-lo a conectar o Spark ao Apache Mesos.
- Configure o programa Spark Driver para se conectar ao Apache Mesos
- Coloque o pacote binário Spark em um local acessível por Mesos
- Instale o Spark no mesmo local do Apache Mesos
- Configure a propriedade spark.mesos.executor.home para apontar para o local onde o Spark está instalado
10. O que é um arquivo Parquet e quais são suas vantagens?
Parquet é um formato colunar compatível com vários sistemas de processamento de dados. Com o arquivo Parquet, o Spark pode executar operações de leitura e gravação.
Algumas das vantagens de ter um arquivo Parquet são:
- Ele permite que você busque colunas específicas para acesso.
- Consome menos espaço
- Segue a codificação específica do tipo
- Suporta operações de E/S limitadas
Aprenda framework de código aberto e linguagens de programação scala com o Curso de treinamento de certificação Apache Spark e Scala .
11. O que é embaralhamento no Spark? Quando isso ocorre?
Embaralhar é o processo de redistribuir dados entre partições que pode levar à movimentação de dados entre os executores. A operação shuffle é implementada de forma diferente no Spark em comparação com o Hadoop.
O embaralhamento tem 2 parâmetros de compressão importantes:
spark.shuffle.compress -verifica se o mecanismo compactaria as saídas aleatórias ou não spark.shuffle.spill.compress -decide se deve compactar arquivos intermediários shuffle spill ou não
Ocorre ao unir duas tabelas ou ao realizar operações byKey , como GroupByKey ou ReduceByKey
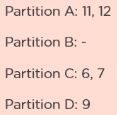
O Spark usa um método de coalescência para reduzir o número de partições em um DataFrame. Suponha que você queira ler dados de um arquivo CSV em um RDD com quatro partições. É assim que uma operação de filtro é realizada para remover todos os múltiplos de 10 dos dados. O RDD tem algumas partições vazias. Faz sentido reduzir o número de partições, o que pode ser obtido usando coalescer. Esta é a aparência do RDD resultante após a aplicação para coalescer. Considere as seguintes informações do cluster: Aqui está o número de identificação do núcleo: Para calcular o número de identificação do executor: Spark Core é o mecanismo para processamento paralelo e distribuído de grandes conjuntos de dados. As várias funcionalidades suportadas pelo Spark Core incluem: Existem 2 maneiras de converter um Spark RDD em um DataFrame: import com.mapr.db.spark.sql._ val df=sc.loadFromMapRDB ( .where (field (“first_name”)===“Peter”) .select (“_ id”, “first_name”). toDF () Você pode converter um RDD [Row] em um DataFrame por chamando createDataFrame em um objeto SparkSession def createDataFrame (RDD, esquema: StructType) RDDs suportam 2 tipos de operação: Transformações : as transformações são operações realizadas em um RDD para criar um novo RDD contendo os resultados (exemplo: mapa, filtro, junção, união) Ações : ações são operações que retornam um valor após a execução de um cálculo em um RDD (exemplo: reduzir, primeiro, contar) Esta é outra pergunta frequente da entrevista do Spark. Um gráfico de linhagem é um gráfico de dependências entre o RDD existente e o novo RDD. Isso significa que todas as dependências entre o RDD serão registradas em um gráfico, ao invés dos dados originais. A necessidade de um gráfico de linhagem RDD ocorre quando queremos calcular um novo RDD ou se queremos recuperar os dados perdidos do RDD persistente perdido. O Spark não oferece suporte à replicação de dados na memória. Portanto, se algum dado for perdido, ele pode ser reconstruído usando a linhagem RDD. Também é chamado de gráfico de operador RDD ou gráfico de dependência de RDD. Discretized Streams é a abstração básica fornecida pelo Spark Streaming. Ele representa um fluxo contínuo de dados que está na forma de uma fonte de entrada ou de um fluxo de dados processado, gerado pela transformação do fluxo de entrada. O armazenamento em cache, também conhecido como persistência, é uma técnica de otimização para cálculos Spark. Semelhante aos RDDs, os DStreams também permitem que os desenvolvedores persistam os dados do stream na memória. Ou seja, usar o método persist () em um DStream irá persistir automaticamente cada RDD daquele DStream na memória. Isso ajuda a salvar resultados parciais provisórios para que possam ser reutilizados em estágios subsequentes. O nível de persistência padrão é definido para replicar os dados em dois nós para tolerância a falhas e para fluxos de entrada que recebem dados pela rede. Variáveis de transmissão permitem que o programador mantenha uma variável somente leitura em cache em cada máquina, em vez de enviar uma cópia dela com as tarefas. Eles podem ser usados para fornecer a cada nó uma cópia de um grande conjunto de dados de entrada de maneira eficiente. O Spark distribui variáveis de transmissão usando algoritmos de transmissão eficientes para reduzir os custos de comunicação. scala> val broadcastVar=sc.broadcast (Matriz (1, 2, 3)) broadcastVar: org.apache.spark.broadcast.Broadcast [Array [Int]]=Broadcast (0) scala> broadcastVar.value res0: Matriz [Int]=Matriz (1, 2, 3) Aprenda os fundamentos do Apache Spark Inscreva-se agora O DataFrame pode ser criado programaticamente com três etapas: 1. map (func) 2. transformar (função) 3. filtro (função) 4. contagem () A resposta correta é c) filtro (função) . Esta é uma das perguntas mais frequentes da entrevista inicial, em que o entrevistador espera uma resposta detalhada (e não apenas um sim ou não!). Dê uma resposta tão detalhada quanto possível aqui. Sim, o Apache Spark fornece uma API para adicionar e gerenciar pontos de verificação. Checkpointing é o processo de tornar os aplicativos de streaming resilientes a falhas. Ele permite que você salve os dados e metadados em um diretório de ponto de verificação. Em caso de falha, a centelha pode recuperar esses dados e começar de onde parou. Existem 2 tipos de dados para os quais podemos usar pontos de verificação no Spark. Ponto de verificação de metadados : metadados significam os dados sobre os dados. Refere-se a salvar os metadados em armazenamento tolerante a falhas, como HDFS. Os metadados incluem configurações, operações DStream e lotes incompletos. Ponto de verificação de dados : aqui, salvamos o RDD em um armazenamento confiável porque sua necessidade surge em algumas das transformações com estado. Nesse caso, o próximo RDD depende dos RDDs dos lotes anteriores. O controle da transmissão de pacotes de dados entre várias redes de computadores é feito pela janela deslizante. A biblioteca Spark Streaming fornece cálculos em janelas em que as transformações em RDDs são aplicadas em uma janela deslizante de dados. DISK_ONLY -Armazena as partições RDD apenas no disco MEMORY_ONLY_SER -Armazena o RDD como objetos Java serializados com uma matriz de um byte por partição MEMORY_ONLY -Armazena o RDD como objetos Java desserializados na JVM. Se o RDD não couber na memória disponível, algumas partições não serão armazenadas em cache OFF_HEAP -Funciona como MEMORY_ONLY_SER, mas armazena os dados na memória off-heap MEMORY_AND_DISK -Armazena RDD como objetos Java desserializados na JVM. Caso o RDD não caiba na memória, partições adicionais são armazenadas no disco MEMORY_AND_DISK_SER -Idêntico a MEMORY_ONLY_SER com exceção de partições de armazenamento que não cabem na memória do disco Uma função de mapa retorna um novo DStream passando cada elemento do DStream de origem por meio de uma função func É semelhante à função de mapa e se aplica a cada elemento de RDD e retorna o resultado como um novo RDD A função Spark Map pega um elemento como um processo de entrada de acordo com o código personalizado (especificado pelo desenvolvedor) e retorna um elemento por vez FlatMap permite retornar 0, 1 ou mais elementos da função de mapa. Na operação FlatMap 1. Carregue o arquivo de texto como RDD: sc.textFile (“hdfs://Hadoop/user/test_file.txt”); 2. Função que divide cada linha em palavras: def toWords (linha): return line.split (); 3. Execute a função toWords em cada elemento de RDD no Spark como transformação flatMap: palavras=line.flatMap (toWords); 4. Converta cada palavra em par (chave, valor): def toTuple (palavra): return (palavra, 1); wordTuple=words.map (toTuple); 5. Execute a ação reduceByKey (): def sum (x, y): retornar x + y: counts=wordsTuple.reduceByKey (sum) 6. Imprimir: counts.collect () lines=sc.textFile (“hdfs://Hadoop/user/test_file.txt”); def isFound (linha): if line.find (“my_keyword”)>-1 retornar 1 retornar 0 foundBits=lines.map (isFound); sum=foundBits.reduce (sum); se a soma> 0: imprimir “Encontrado” outro: imprimir “Não encontrado”; Acumuladores são variáveis usadas para agregar informações entre os executores. Essas informações podem ser sobre os dados ou diagnóstico de API, como quantos registros estão corrompidos ou quantas vezes uma API de biblioteca foi chamada. e Seleção Domine toda a habilidade de Big Data de que você precisa hoje Inscreva-se agora Spark MLlib oferece suporte a vetores e matrizes locais armazenados em uma única máquina, bem como matrizes distribuídas. Vetor local : MLlib oferece suporte a dois tipos de vetores locais- denso e esparso
Exemplo: vetor (1.0, 0.0, 3.0) formato denso: [1.0, 0.0, 3.0] formato esparso: (3, [0, 2]. [1.0, 3.0]) Ponto rotulado : um ponto rotulado é um vetor local, denso ou esparso, associado a um rótulo/resposta. Exemplo : na classificação binária, um rótulo deve ser 0 (negativo) ou 1 (positivo) Matriz local : uma matriz local tem índices de linha e coluna de tipo inteiro e valores de tipo duplo que são armazenados em uma única máquina. Matriz distribuída : uma matriz distribuída tem índices de linha e coluna de tipo longo e valores de tipo duplo e é armazenada de maneira distribuída em um ou mais RDDs. Tipos de matriz distribuída: Um vetor esparso é um tipo de vetor local representado por uma matriz de índice e uma matriz de valor. classe pública SparseVector estende o objeto implementa Vector Exemplo: sparse1=SparseVector (4, [1, 3], [3.0, 4.0]) onde: 4 é o tamanho do vetor [1,3] são os índices ordenados do vetor [3,4] são o valor MLlib tem 2 componentes: Transformer : um transformador lê um DataFrame e retorna um novo DataFrame com uma transformação específica aplicada. Estimador : um estimador é um algoritmo de aprendizado de máquina que usa um DataFrame para treinar um modelo e retorna o modelo como um transformador. Spark MLlib permite combinar várias transformações em um pipeline para aplicar transformações de dados complexas. A imagem a seguir mostra esse pipeline para treinar um modelo: O modelo produzido pode então ser aplicado aos dados ativos: Spark SQL é o módulo do Apache Spark para trabalhar com dados estruturados. O Spark SQL carrega os dados de uma variedade de fontes de dados estruturados. Ele consulta dados usando instruções SQL, tanto dentro de um programa Spark quanto de ferramentas externas que se conectam ao Spark SQL por meio de conectores de banco de dados padrão (JDBC/ODBC). Ele fornece uma integração rica entre SQL e código Python/Java/Scala regular, incluindo a capacidade de juntar RDDs e tabelas SQL e expor funções personalizadas em SQL. Para conectar o Hive ao Spark SQL, coloque o arquivo hive-site.xml no diretório conf do Spark. Usando o objeto Spark Session, você pode construir um DataFrame. result=spark.sql (“select * from O otimizador Catalyst aproveita recursos avançados de linguagem de programação (como correspondência de padrões e quase aspas do Scala) de uma maneira inovadora para construir um otimizador de consulta extensível. Os dados estruturados podem ser manipulados usando uma linguagem específica do domínio da seguinte maneira: Suponha que haja um DataFrame com as seguintes informações: val df=spark.read.json (“examples/src/main/resources/people.json”) //Exibe o conteúdo do DataFrame para stdout df.show () //+—-+——-+ //| idade | nome | //+—-+——-+ //| null | Michael | //| 30 Andy | //| 19 Justin | //+—-+——-+ //Selecione apenas a coluna”nome” df.select (“nome”). show () //+——-+ //| nome | //+——-+ //| Michael | //| Andy | //| Justin | //+——-+ //Selecione todos, mas aumente a idade em 1 df.select ($”name”, $”age”+ 1).show () //+——-+———+ //| nome | (idade + 1) | //+——-+———+ //| Michael | null | //| Andy | 31 | //| Justin | 20 | //+——-+———+ //Selecione pessoas com mais de 21 anos df.filter ($”age”> 21).show () //+—+—-+ //| idade | nome | //+—+—-+ //| 30 | Andy | //+—+—-+ //Contar pessoas por idade df.groupBy (“idade”). count (). show () //+—-+—–+ //| idade | contagem | //+—-+—–+ //| 19 1 | //| null | 1 | //| 30 1 | //+—-+—–+ Nesse tipo de perguntas de entrevista, tente dar uma explicação também (não apenas o nome dos operadores). Operador de propriedade : os operadores de propriedade modificam as propriedades do vértice ou da aresta usando uma função de mapa definida pelo usuário e produzem um novo gráfico. Operador estrutural : os operadores de estrutura operam na estrutura de um gráfico de entrada e produzem um novo gráfico. Operador de junção : operadores de junção adicionam dados a gráficos e geram novos gráficos. GraphX é a API do Apache Spark para gráficos e computação paralela a gráficos. GraphX inclui um conjunto de algoritmos de gráfico para simplificar as tarefas analíticas. Os algoritmos estão contidos no pacote org.apache.spark.graphx.lib e podem ser acessados diretamente como métodos no Graph via GraphOps . PageRank : o PageRank é um cálculo paralelo de gráfico que mede a importância de cada vértice em um gráfico. Exemplo: você pode executar o PageRank para avaliar quais são as páginas mais importantes da Wikipedia. Componentes conectados : o algoritmo de componentes conectados rotula cada componente conectado do gráfico com o ID de seu vértice de menor número. Por exemplo, em uma rede social, os componentes conectados podem aproximar os clusters. Contagem de triângulos : um vértice faz parte de um triângulo quando possui dois vértices adjacentes com uma aresta entre eles. GraphX implementa um algoritmo de contagem de triângulos no objeto TriangleCount que determina o número de triângulos que passam por cada vértice, fornecendo uma medida de agrupamento. É um ponto positivo se você conseguir explicar essa questão da entrevista de faísca minuciosamente, junto com um exemplo! PageRank measures the importance of each vertex in a graph, assuming an edge from u to v represents an endorsement of v’s importance by u. If a Twitter user is followed by many other users, that handle will be ranked high. PageRank algorithm was originally developed by Larry Page and Sergey Brin to rank websites for Google. It can be applied to measure the influence of vertices in any network graph. PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The assumption is that more important websites are likely to receive more links from other websites. A typical example of using Scala’s functional programming with Apache Spark RDDs to iteratively compute Page Ranks is shown below: There you go, this was the collection of some of the most commonly asked, conceptual, and some theoretical Apache Spark interview questions that you might come across while attending an interview for a Spark-related interview. To learn more about Apache Spark interview questions, you can also watch this video: Apache Spark Interview Questions. On the other hand you can also enroll in our Apache Spark and Scala Certification Training, that will help you gain expertise working with the Big Data Hadoop Ecosystem. You will master essential skills of the Apache Spark open-source framework and the Scala programming language, including Spark Streaming, Spark SQL, machine learning programming, GraphX programming, and Shell Scripting Spark among other highly valuable skills that will make answering any Apache Spark interview questions a potential employer throws your way. So start learning now and get a step closer to rocking your next spark interview! 12. Qual é a utilidade de coalescer no Spark?


13. Como você pode calcular a memória do executor?


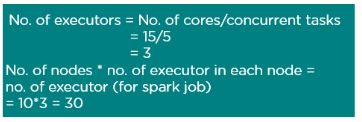
14. Quais são as várias funcionalidades suportadas pelo Spark Core?
15. Como você converte um Spark RDD em um DataFrame?
16. Explique os tipos de operações suportadas por RDDs.
17. O que é um gráfico de linhagem?
18. O que você entende sobre DStreams no Spark?

19. Explique o cache no fluxo do Spark.

20. Qual é a necessidade de variáveis de transmissão no Spark?
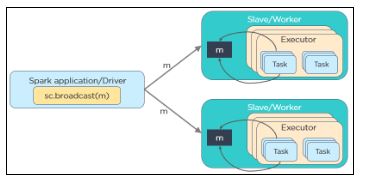
Curso gratuito para iniciantes do Apache Spark
![]()
Perguntas da entrevista do Apache Spark para experientes
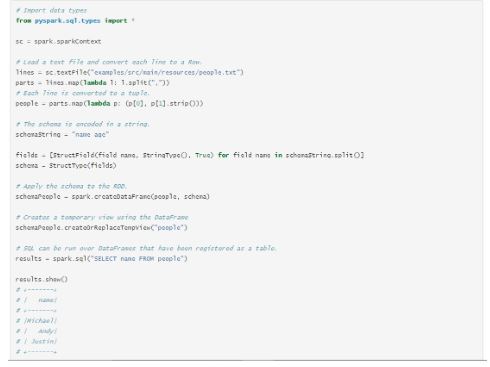
21. Como especificar programaticamente um esquema para DataFrame?
22. Qual transformação retorna um novo DStream selecionando apenas os registros do DStream de origem para os quais a função retorna verdadeiro?
23. O Apache Spark oferece pontos de verificação?
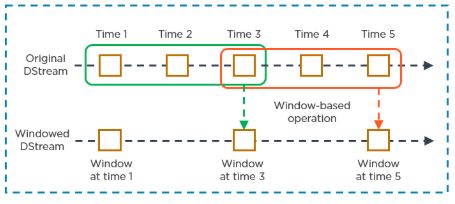
24. O que você quer dizer com operação de janela deslizante?
25. Quais são os diferentes níveis de persistência no Spark?
26. Qual é a diferença entre map e transformação flatMap no Spark Streaming?
27. Como você calcularia a contagem total de palavras únicas no Spark?
28. Suponha que você tenha um arquivo de texto enorme. Como você verificará se existe uma determinada palavra-chave usando o Spark?
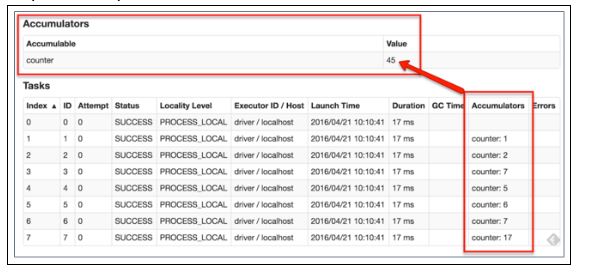
29. Qual é a função dos acumuladores no Spark?
30. Quais são as diferentes ferramentas MLlib disponíveis no Spark?
Programa mestre de engenheiro de Big Data
![]()
31. Quais são os diferentes tipos de dados suportados pelo Spark MLlib?

32. O que é um vetor esparso?
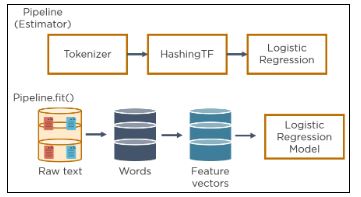
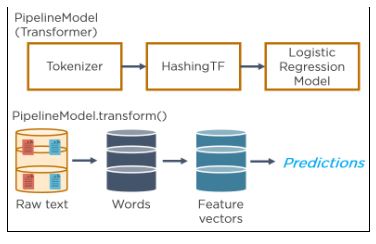
33. Descreva como a criação do modelo funciona com MLlib e como o modelo é aplicado.
34. Quais são as funções do Spark SQL?
35. Como você pode conectar o Hive ao Spark SQL?
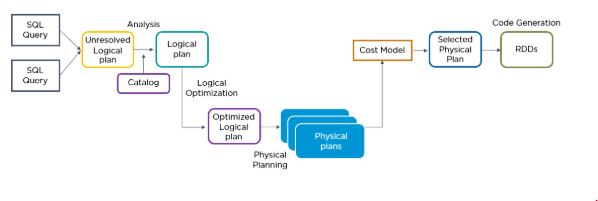
36. Qual é a função do Catalyst Optimizer no Spark SQL?
37. Como você pode manipular dados estruturados usando linguagem específica de domínio no Spark SQL?
38. Quais são os diferentes tipos de operadores fornecidos pela biblioteca Apache GraphX?
39. Quais são os algoritmos analíticos fornecidos no Apache Spark GraphX?
40. Qual é o algoritmo PageRank no Apache Spark GraphX?



Rock Your Spark Interview
