Os dados de rastreamento do mecanismo de pesquisa encontrados nos arquivos de log são uma fonte fantástica de informações para qualquer profissional de SEO.
Por analisando arquivos de registro , você pode entender exatamente como funcionam os mecanismos de pesquisa rastreando e interpretando seu site-clareza que você simplesmente não consegue obter ao confiar em ferramentas de terceiros.
Isso permitirá que você:
Validar suas teorias fornecendo evidências incontestáveis de como os mecanismos de pesquisa estão se comportando. Priorize suas descobertas ajudando-o a compreender a escala de um problema e o provável impacto de corrigi-lo. Descubra problemas adicionais que não são visíveis ao usar outras fontes de dados.
Mas, apesar da infinidade de benefícios, os dados do arquivo de registro não são t usado tão freqüentemente quanto deveria ser. Os motivos são compreensíveis:
acessar os dados geralmente envolve passar por uma equipe de desenvolvimento, o que pode levar tempo . Os arquivos brutos podem ser enormes e fornecidos em um formato hostil, portanto, a análise dos dados leva esforço .Ferramentas projetadas para tornar o processo mais fácil podem precisar ser integradas antes que os dados possam ser canalizados para ele, e os custos podem ser proibitivos.
Publicidade
Continue lendo abaixo
Todos esses problemas são barreiras perfeitamente válidas para entrar, mas eles não precisam ser intransponíveis.
Com um pouco de conhecimento básico de codificação , você pode automatizar todo o processo. Isso é exatamente o que faremos nesta lição passo a passo sobre como usar Python para analisar os logs do servidor para SEO.
Você encontrará um script para começar também.
Considerações iniciais
Um dos maiores desafios na análise dos dados do arquivo de log é o grande número de formatos potenciais. Apache , Nginx e IIS oferece uma gama de opções diferentes e permite que os usuários personalizem os pontos de dados retornados.
Para complicar ainda mais, muitos sites agora usam fornecedores CDN como Cloudflare, Cloudfront, e a Akamai para fornecer conteúdo do ponto de presença mais próximo a um usuário. Cada um deles também tem seus próprios formatos.
Vamos nos concentrar no destino Formato de registro combinado para esta postagem, já que este é o padrão para Nginx e uma escolha comum em servidores Apache.
Anúncio
Continue lendo abaixo
Se você não tiver certeza de que tipo de formato está lidando, serviços como Builtwith e Wappalyzer fornecem informações excelentes sobre a pilha de tecnologia de um site. Eles podem ajudá-lo a determinar isso se você não tiver acesso direto a um interessado técnico.
Ainda não sabe? Tente abrir um dos arquivos brutos.
Freqüentemente, os comentários são fornecidos com informações sobre os campos específicos, que podem ser referenciados.
#Fields: time c-ip cs-metodo cs-uri-stem sc-status cs-version 17:42:15 172.16.255.255 GET/default.htm 200 HTTP/1.0
Outra consideração é quais mecanismos de pesquisa queremos incluir, já que este precisará ser fatorado em nossa filtragem e validação iniciais.
Para simplificar as coisas, vamos nos concentrar no Google, dado seu dominante 88% do mercado dos EUA.
Vamos começar.
1. Identificar arquivos e determinar formatos
Para realizar uma análise de SEO significativa, queremos um mínimo de aproximadamente 100 mil solicitações e 2 a 4 semanas de dados para um site comum.
Devido ao tamanhos de arquivo envolvidos, os logs geralmente são divididos em dias individuais. É praticamente garantido que você receberá vários arquivos para processar.
Como não sabemos com quantos arquivos lidaremos, a menos que os combinemos antes de executar o script, uma primeira etapa importante é gere uma lista de todos os arquivos em nossa pasta usando o módulo glob .
Isso nos permite retornar qualquer arquivo que corresponda a um padrão que especificamos. Por exemplo, o código a seguir corresponderia a qualquer arquivo TXT.
import glob files=glob.glob (‘*. Txt’)
Arquivos de log podem ser fornecidos em uma variedade de formatos de arquivo, no entanto, não apenas TXT.
Na verdade, às vezes a extensão do arquivo pode não ser reconhecida. Aqui está um arquivo de log bruto do Log Delivery Service da Akamai, que ilustra isso perfeitamente:
bot_log_100011.esw3c_waf_S.202160250000-2000-41
Além disso, é possível que os arquivos recebidos sejam divididos entre várias subpastas, e não queremos perder tempo copiando-as em um único local.
Felizmente, o glob suporta pesquisas recursivas e operadores curinga. Isso significa que podemos gerar uma lista de todos os arquivos dentro de uma subpasta ou subpastas filhas.
Anúncio
Continue lendo abaixo
files=glob.glob (‘**/*.*’, recursive=True)
A seguir, queremos identificar quais tipos de arquivos estão em nossa lista. Para fazer isso, o tipo MIME do arquivo específico pode ser detectado. Isso nos dirá exatamente com que tipo de arquivo estamos lidando, independentemente da extensão.
Isso pode ser feito usando python-magic, um wrapper em torno da biblioteca C libmagic e criando uma função simples.
pip install python-magic pip install libmagicimport magic def file_type (file_path): mime=magic.from_file (file_path, mime=True) return mime
Compreensão de lista pode então ser usada para percorrer nossos arquivos e aplicar a função, criando um dicionário para armazenar os nomes e tipos.
file_types=[ file_type (file) for file in files] file_dict=dict (zip (files, file_types))
Finalmente, uma função e um loop while para extrair uma lista de arquivos que retornam um tipo MIME de texto/simples e exclui qualquer outra coisa.
descompactado=[] def file_identifier (file): para chave, valor em file_dict.items (): se o arquivo em valor: descompactado.append (chave) enquanto file_identifier (‘text/plain’): file_identifier (‘text/plain’) em file_dict

2. Extrair solicitações do mecanismo de pesquisa
Depois de filtrar os arquivos em nossas pastas, a próxima etapa é filtrar os próprios arquivos, extraindo apenas as solicitações que nos interessam.
Anúncio
Continue lendo abaixo
Isso elimina a necessidade de combinar os arquivos usando utilitários de linha de comando como GREP ou FINDSTR , salvando uma pesquisa inevitável de 5 a 10 minutos por meio de guias e marcadores abertos do notebook para encontrar o comando correto.
Neste caso, como queremos apenas Solicitações do Googlebot, pesquisar por’Googlebot’corresponderá a todos os usuários relevantes agentes .
Podemos usar a função aberta do Python para ler e escrever nosso arquivo e o módulo regex do Python, RE, para realizar o search.
import re pattern=’Googlebot’new_file=open (‘./googlebot.txt’,’w’, encoding=’utf8′) para txt_files em descompactado: com open (txt_files,’r’, codificação=’utf8′) as text_file: for line in text_file: if re.search (pattern, line): new_file.write (line)
O Regex torna isso facilmente escalonável usando um operador OR.
pattern=’Googlebot | bingbot’
3. Solicitações de análise
Em um postagem anterior , Hamlet Batista forneceu orientação sobre como usar regex para analisar solicitações.
Como uma abordagem alternativa, usaremos Pandas ‘poderoso analisador CSV embutido e algumas funções básicas de processamento de dados para:
Eliminar colunas desnecessárias.Formatar o carimbo de data/hora.Criar uma coluna com URLs completos. Renomeie e reordene as colunas restantes.
Em vez de codificar um nome de domínio, a entrada pode ser usada para solicitar ao usuário e salvá-la como uma variável.
Anúncio
Continue lendo abaixo
whole_url=input (‘Ple ase insira o domínio completo com protocolo:’) # get domain from user input df=pd.read_csv (‘./googlebot.txt’, sep=’\ s +’, error_bad_lines=False, header=None, low_memory=False) # import logs df.drop ([1, 2, 4], axis=1, inplace=True) # eliminar colunas/caracteres indesejados df [3]=df [3].str.replace (‘[‘,”) # divisão carimbo de data/hora em dois df [[‘Date’,’Time’]]=df [3].str.split (‘:’, 1, expand=True) df [[‘Tipo de solicitação’,’URI’,’Protocolo’]]=df [5].str.split (”, 2, expand=True) # divide a solicitação de uri em colunas df.drop ([3, 5], axis=1, inplace=True) df.rename ( colunas={0:’IP’, 6:’Código de status’, 7:’Bytes’, 8:’URL do referenciador’, 9:’Agente do usuário’}, inplace=True) # renomear colunas df [‘URL completo’]=whole_url + df [‘URI’] # concatenar nome de domínio df [‘Date’]=pd.to_datetime (df [‘Date’]) # declara tipos de dados df [[‘Código de status’,’Bytes’]]=df [[‘Código de status’,’Bytes’]]. apply (pd.to_numeric) df=df [[‘Data’,’Hora’,’Tipo de solicitação’,’URL completo’,’URI’,’Código de status’,’Protocolo’,’URL de referência’,’Bytes’,’Agente do usuário’,’IP’]] # reordenar colunas
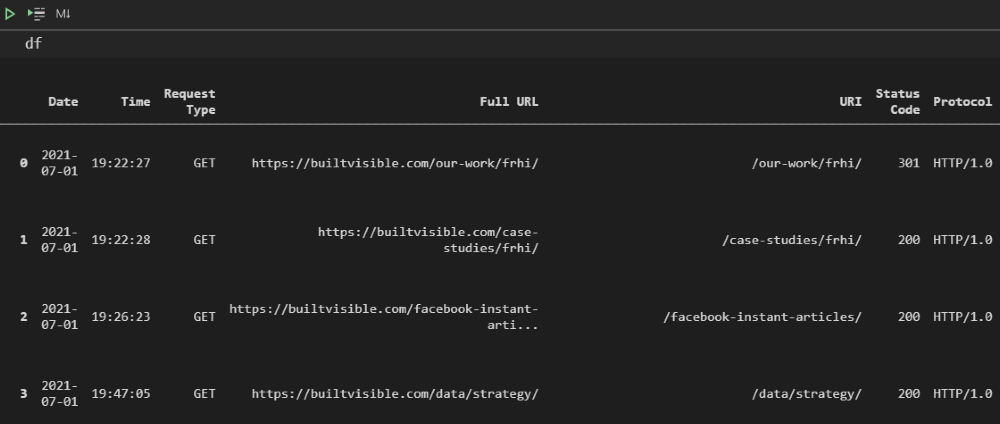
4. Validar solicitações
É incrivelmente fácil falsificar os agentes do usuário do mecanismo de pesquisa, tornando a validação da solicitação uma parte vital do processo, para que não acabemos tirando conclusões falsas ao analisar nossos próprios rastreamentos de terceiros.
Para fazer isso, vamos instalar uma biblioteca chamada dnspython e executar um DNS reverso.
Pandas podem ser usados para descartar IPs duplicados e executar pesquisas neste DataFrame menor, antes de reaplicar os resultados e filtrar quaisquer solicitações inválidas.
Anúncio
Continue lendo Abaixo
do resolvedor de importação de dns, reversename def reverseDns (ip): try: return str (resolver.query (reversename.from_address (ip),’PTR’) [0]) exceto: return’N/A’logs_filtered=df.drop_duplicates ([‘IP’]). copy () # criar DF com duplicado ips filtrado para verificar logs_filtered [‘DNS’]=logs_filtered [‘IP’]. apply (reverseDns) # criar coluna DNS com o IP reverso Logs de resultados de DNS_filtered=df.me rge (logs_filtered [[‘IP’,’DNS’]], how=’left’, on=[‘IP’]) # mesclar coluna DNS para registros completos correspondentes IP logs_filtered=logs_filtered [logs_filtered [‘DNS’]. str.contains (‘googlebot.com’)] # filtro para verificar o Googlebot logs_filtered.drop ([‘IP’,’DNS’], axis=1, inplace=True) # drop dns/ip columns
Essa abordagem irá acelera drasticamente as pesquisas, validando milhões de solicitações em minutos.
No exemplo abaixo, cerca de 4 milhões de linhas de solicitações foram processadas em 26 segundos.

5. Dinamizar os dados
Após a validação, ficamos com um conjunto de dados limpo e bem formatado e podemos começar a dinamizar esses dados para analisar mais facilmente os pontos de dados de interesse.
Em primeiro lugar , vamos começar com alguma agregação simples usando Pandas’ groupby e agg funções para realizar uma contagem do número de solicitações para códigos de status diferentes.
Anúncio
Continue lendo abaixo
status_code=logs_filtered.groupby (‘Código de status’). agg (‘tamanho’)
Para replicar o tipo de contagem com o qual você está acostumado no Excel, é importante notar que precisamos especificar uma função agregada de’tamanho’, não’count’.
O uso de count invocará a função em todas as colunas do DataFrame e os valores nulos serão tratados d ifferently.
Redefinir o índice irá restaurar os cabeçalhos de ambas as colunas, e a última coluna pode ser renomeada para algo mais significativo.
status_code=logs_filtered.groupby (‘Código de status’). agg (‘size’). sort_values (ascending=False).reset_index () status_code.rename (columns={0:’# Requests’}, inplace=True)

Para manipulação de dados mais avançada, Pandas’ tabelas dinâmicas integradas oferecem funcionalidade comparável ao Excel, tornando possíveis agregações complexas com uma única linha de código.

Em seu nível mais básico, a função requer um DataFrame e índice especificados-ou índices se for um índice múltiplo é obrigatório-e retorna os valores correspondentes.
Anúncio
Continue lendo abaixo
pd.pivot_table (logs_filtered, index [‘URL completo’])
Para maior especificidade, os valores necessários podem ser declarados e agregações-soma, média, etc-aplicadas usando o parâmetro aggfunc.
Também vale a pena mencionar o parâmetro colunas, que nos permite exibir valores horizontalmente para uma saída mais clara.
status_code_url=pd.pivot_table (logs_filtered, index=[‘URL completo’], colunas=[‘Código de status’], aggfunc=’tamanho’, fill_value=0)

Aqui está um um pouco mais complexo exemplo, que fornece uma contagem dos URLs exclusivos rastreados por agente de usuário por dia, em vez de apenas uma contagem do número de solicitações.
user_agent_url=pd.piv ot_table (logs_filtered, index=[‘User Agent’], values =[‘Full URL’], columns=[‘Date’], aggfunc=pd.Series.nunique, fill_value=0)
Se você ainda lutando com a sintaxe, verifique Mito . Ele permite que você interaja com uma interface visual dentro do Jupyter ao usar o JupyterLab, mas ainda produz o código relevante.
Anúncio
Continue lendo abaixo
Incorporando intervalos
Para pontos de dados como bytes, que provavelmente têm muitos valores numéricos diferentes, faz sentido agrupar os dados.
Para fazer isso, podemos definir nossos intervalos dentro de uma lista e, em seguida, use o cortar função para classificar os valores em compartimentos, especificando np.inf para capturar qualquer coisa acima do valor máximo declarado.
byte_range=[0, 50000, 100000, 200000, 500000, 1000000, np.inf] bytes_grouped_ranges=(logs_filtered. groupby (pd.cut (logs_filtered [‘Bytes’], bins=byte_range, precisão=0)).agg (‘size’).reset_index ()) bytes_grouped_ranges.rename (colunas={0:’# Requests’}, no local=Verdadeiro)
A notação de intervalo é usada na saída para definir intervalos exatos, por exemplo
(50000 100000]
Os colchetes indicam quando um número não está incluído e um colchete quando ele é incluído. Portanto, no exemplo acima, o intervalo contém pontos de dados com um valor entre 50.001 e 100.000.
6. Exportar
A etapa final em nosso processo é exportar nossos dados de registro e pivôs.
Para facilitar a análise, faz sentido exportar para um arquivo Excel (XLSX) em vez de um CSV. Os arquivos XLSX suportam várias planilhas, o que significa que todos os DataFrames podem ser combinados no mesmo arquivo.
Isso pode ser feito usando para excel . Nesse caso, um objeto ExcelWriter também precisa ser especificado porque mais de uma planilha está sendo adicionada à mesma pasta de trabalho.
Anúncio
Continue lendo abaixo
writer=pd.ExcelWriter (‘logs_export.xlsx’, engine=’xlsxwriter’, datetime_format=’dd/mm/aaaa’, options={‘strings_to_urls’: False}) logs_filtered.to_excel (writer, sheet_name=’Master’, index=False) pivot1.to_excel (writer, sheet_name=’My pivot’) writer.save ()
Ao exportar um grande número de pivôs, ajuda a simplificar as coisas armazenando DataFrames e nomes de planilhas em um dicionário e usando um loop for.
sheet_names={‘Solicitar códigos de status por dia’: status_code_date,’URL Status Codes’: status_code_url,’User Agent Requests Per Day’: user_agent_date,’User Agent Solicita URLs exclusivos’: user_agent_url,} para planilha, nome em sheet_names.items (): name.to_excel (escritor, sheet_name=sheet)
Uma última complicação é que o Excel tem um limite de linhas de 1.048.576. Estamos exportando todas as solicitações, então isso pode causar problemas ao lidar com grandes amostras.
Como os arquivos CSV não têm limite, uma instrução if pode ser empregada para adicionar uma exportação CSV como fallback.
Se o comprimento do arquivo de log DataFrame for maior que 1.048.576, ele será exportado como um CSV, evitando que o script falhe enquanto ainda combina os pivôs em uma exportação singular.
se len (logs_filtered ) <=1048576: logs_filtered.to_excel (writer, sheet_name='Master', index=False) else: logs_filtered.to_csv ('./logs_export.csv', index=False)
Considerações finais
Vale a pena investir algum tempo nas percepções adicionais que podem ser obtidas a partir dos dados do arquivo de log.
Se você tem evitado aproveitar esses dados devido às complexidades envolvidas, espero que esta postagem convença você que isso pode ser superado.
Para aqueles que já têm acesso a ferramentas e estão interessados em codificação, espero que quebrar esse processo de ponta a ponta tenha dado a você uma compreenda melhor as considerações envolvidas ao criar um script maior para automatizar tarefas repetitivas e demoradas.
Anúncio
Continue lendo abaixo
O script completo que criei pode ser encontrado aqui no Github.
Isso inclui mais extras como integração GSC API, mais pivôs e suporte para mais dois formatos de log: Amazon ELB e W3C (usado pelo IIS).
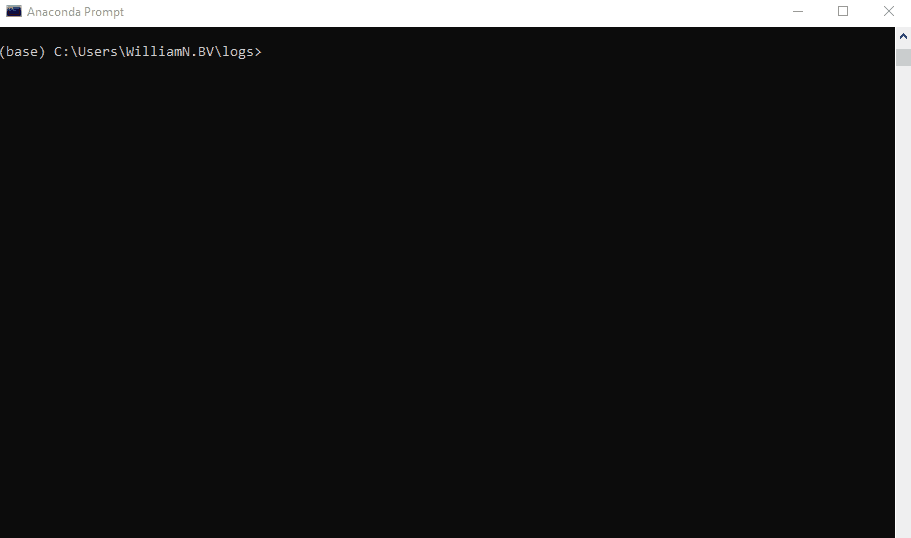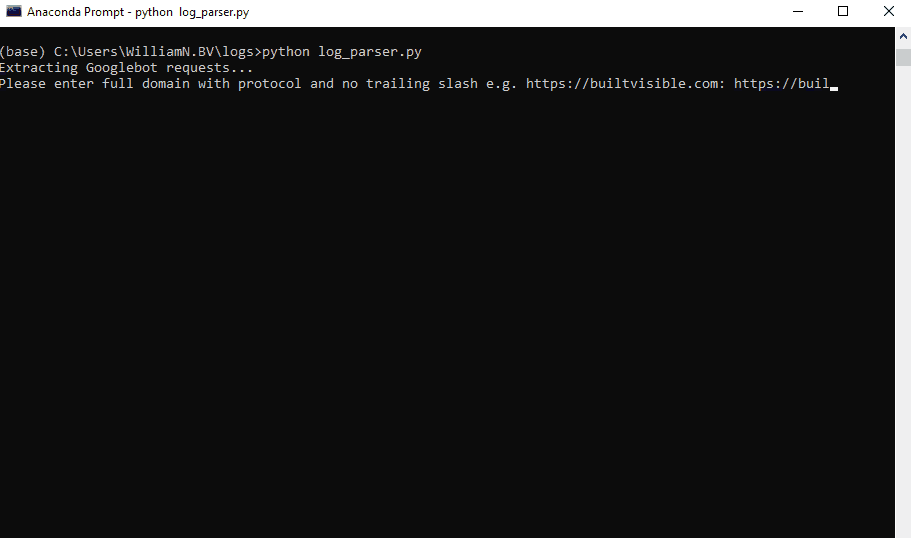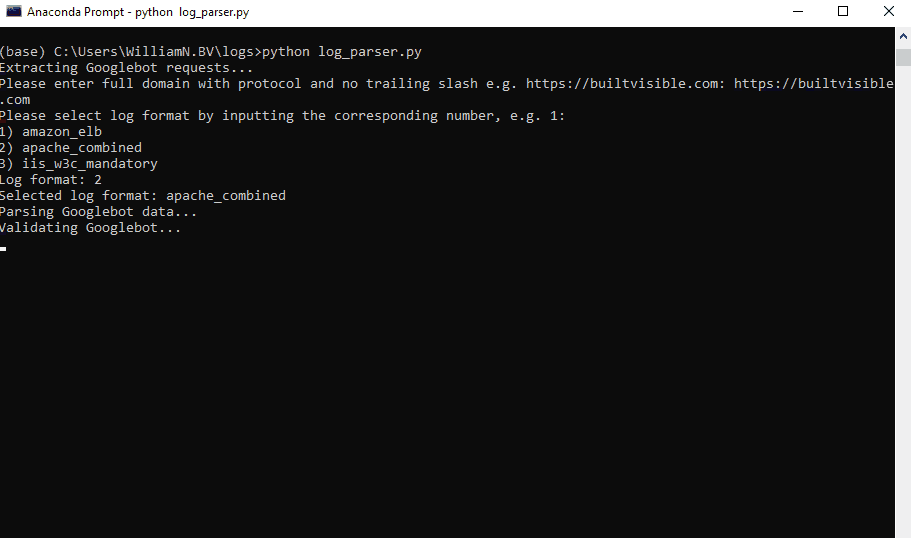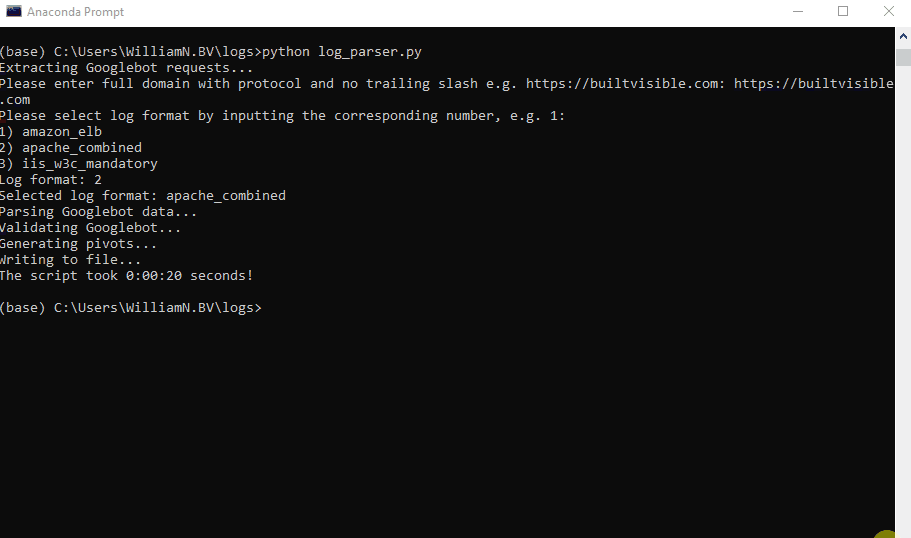
Para adicionar outro formato, inclua o nome na lista log_fomats na linha 17 e adicione uma declaração elif adicional na linha 193 (ou edite um dos existentes).
Há, é claro, um escopo enorme para expandir isso ainda mais. Fique ligado na segunda parte do post que cobrirá a incorporação de dados de rastreadores de terceiros, pivôs mais avançados e visualização de dados.
Publicidade
Continue lendo abaixo
Mais recursos:
Créditos de imagem
Todas as capturas de tela feitas pelo autor, julho de 2021
