!important;width:100%!important}
Un artículo de análisis reciente encontró una relación entre la acción dopaminérgica y el algoritmo de estudio TD (cambio temporal), brindando información fundamental sobre cómo el cerebro vincula indicadores y beneficios separados en el tiempo. ”
La dopamina es un neurotransmisor común, y el término “dopaminérgico” implica “conectado a la dopamina” (prácticamente, “que actúa sobre la dopamina”). La acción relacionada con la dopamina del cerebro es amplificada por los medicamentos o comportamientos dopaminérgicos recetados. El movimiento asociado con la dopamina es facilitado por los circuitos cerebrales dopaminérgicos.
La investigación en neurociencia y psicología ha demostrado continuamente cuán vitales son los incentivos para ayudar a hombres, mujeres y otros animales a dominar el comportamiento que los ayudará a resistir. Es bien sabido que las neuronas dopaminérgicas, las neuronas en el sistema nervioso central de los mamíferos que liberan dopamina, principalmente requieren una comprensión basada en la recompensa en los mamíferos. Cuando un mamífero obtiene una recompensa inesperada, estas neuronas reaccionan rápidamente mediante un procedimiento conocido como excitación fásica.
Para establecer productos de control de equipos poderosos que puedan encargarse de responsabilidades difíciles, los expertos en computadoras portátiles o computadoras no hace mucho tiempo lo han hecho. comenzó a intentar reproducir artificialmente las bases neurológicas del descubrimiento de recompensas en los mamíferos. The so-referred to as temporal variation (TD) learning algorithm is a very well-acknowledged machine understanding strategy that mimics the operation of dopaminergic neurons.
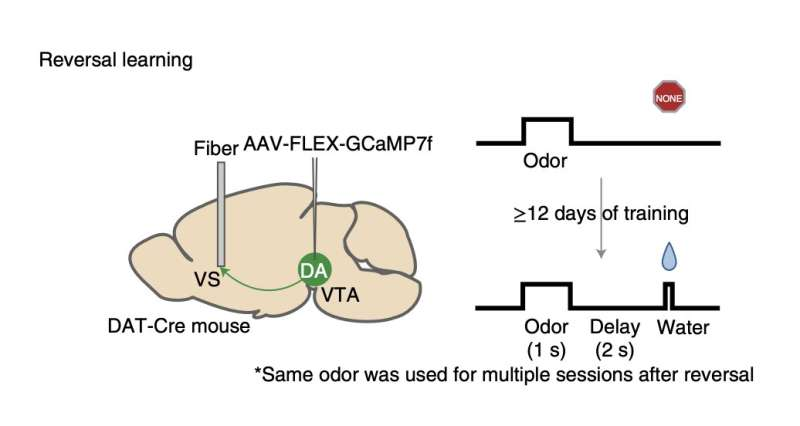 Calificación crediticia: Amo et al. | Fuente: https://www.nature.com/articles/s41593-022-01109-2
Calificación crediticia: Amo et al. | Fuente: https://www.nature.com/articles/s41593-022-01109-2
El investigador exploró una posible relación entre el enfoque de dominio de TD computacional y el aprendizaje humano centrado en incentivos. Su estudio, publicado en la revista Nature Neuroscience, tal vez pueda brindar una nueva perspectiva sobre cómo la mente establece vínculos unidireccionales entre estímulos y beneficios espaciados en el tiempo.
Un familiar de los enfoques de comprensión de refuerzo conocidos como”Los algoritmos de masterización de TD” pueden aprender a generar predicciones basadas principalmente en cambios ambientales más que en el tiempo en lugar de usar un diseño. Los enfoques de TD pueden cambiar sus estimaciones más que otros procedimientos de control de dispositivos antes de revelar su pronóstico final.
Los paralelismos entre los algoritmos de aprendizaje de TD y las neuronas de dopamina de aprendizaje de recompensas en el cerebro se han dado cuenta recientemente. en bastantes investigaciones. Sin embargo, un componente particular del procedimiento del algoritmo solo se ha considerado ocasionalmente en experimentos de neurociencia.
El tiempo de las señales de dopamina debería cambiar constantemente hacia atrás desde el momento de la recompensa hasta el momento de la señal. bastantes intentos cuando un agente asocia una señal y una recompensa que están separadas en el tiempo, de acuerdo con estudios anteriores que no lograron observar la predicción crucial de este algoritmo.
El investigador analizó las conclusiones de sus estudios en ratones no entrenados y estableció la capacidad de vincular señales olfativas con recompensas de agua potable en su publicación. Las ratas mostraron una acción de lamido que sugería que esperaban tener agua inmediatamente después de haber percibido el olor correspondiente cuando comenzaron a relacionar fragancias específicas con recibirlo.
Los ratones habían estado expuestos al olor previo a la recompensa. y la recompensa en distintos momentos a través de los experimentos. Para decirlo de otra manera, alteraron el intervalo entre la exposición de los ratones al olor y la recepción de la recompensa de agua.
Identificaron que las neuronas de dopamina habían sido originalmente mucho menos energéticas cuando la recompensa se retrasó, pero en algún momento se volvió más activo. Esto demostró que el momento de las respuestas de dopamina en la mente podría ajustarse a medida que los ratones dominan las conexiones entre los olores y las recompensas por primera vez, como se demostró en las técnicas de estudio de TD.
Los investigadores realizaron más pruebas científicas para determinar si este cambio también ocurriera en ratas que habían sido previamente entrenadas para generar vínculos idénticos de olor-recompensa durante los trabajos de reversión. Durante la etapa de espera, observaron una alteración temporal en las señales de dopamina del animal similar a cuando los animales estaban descubriendo conexiones por primera vez, pero sucedió mucho más rápido.
En general, los hechos demuestran que varias pruebas de aprendizaje asociativo dieron como resultado un cambio hacia atrás en el momento de la acción de la dopamina en el cerebro del ratón. Este cambio temporal encontrado es muy similar a la mecánica que guía los enfoques de aprendizaje de TD.
Los estudios científicos a largo plazo sobre los posibles paralelos que involucran la comprensión de recompensas en la mente de los mamíferos y las tácticas de aprendizaje de refuerzo de TD pueden ser ayudados por la información. recibida por esta fuerza de trabajo de expertos. Esto podría aumentar nuestra comprensión de cómo el cerebro aprende los beneficios y posiblemente también sirva como compromiso para los nuevos algoritmos de aprendizaje de TD.
Este informe se crea como un resumen escrito por los empleados de Marktechpost basado en el documento de análisis’Un cambio temporal gradual de las respuestas de dopamina refleja el desarrollo del error de variación temporal en el estudio de máquinas‘. Toda la calificación crediticia de esta exploración va para los científicos en este desafío. Consulte el documento y artículo de referencia. No debe olvidarse de ser parte de Nuestro Subreddit de ML 
Soy pasante de consultoría en MarktechPost. Me estoy especializando en Ingeniería Mecánica en IIT Kanpur. Mi deseo radica en la industria del mecanizado y la Robótica. Además, tengo un gran interés en AI, ML, DL y áreas relacionadas. Soy un entusiasta de la tecnología y un apasionado de los nuevos sistemas y sus usos reales.
Califica esta publicación
¡Compartir es solidario!
