Introdução
A importância de otimizar o desempenho do aplicativo não pode ser exagerada. Como desenvolvedores da Web, queremos que nossos aplicativos forneçam uma ótima experiência do usuário, então precisamos empregar uma variedade de técnicas para otimizar sua velocidade e desempenho.
A primeira etapa do processo é identificar como e onde surgem os gargalos de desempenho no aplicativo. A suspeita usual aqui é como lidamos e gerenciamos nossos dados de aplicativo. Quando se trata de aplicativos Node.js-e sistemas de back-end/aplicativos em geral-quase sempre há necessidade de armazenar dados ou informações do usuário em um banco de dados dedicado para recuperação posterior.
Em grande medida, a maneira como lidamos com os dados em nosso aplicativo determina o quão bem ele terá um desempenho em escala, especialmente considerando que os próprios bancos de dados podem ampliar o gargalo de desempenho geral de nossos aplicativos da web. Qualquer técnica que possamos aplicar para reduzir o tempo necessário para realizar operações de leitura/gravação nesses bancos de dados será benéfica.
O cache é uma técnica que podemos empregar para resolver esses desafios de desempenho. Neste tutorial, exploraremos maneiras de melhorar o desempenho geral de um aplicativo, empregando estratégias de armazenamento em cache de dados em Node.js. Vamos começar!
Em primeiro lugar, por que armazenar os dados em cache?
O armazenamento em cache geralmente é recomendado para casos em que o estado dos dados em um ponto específico do aplicativo raramente muda. Pense em listas de produtos, códigos de chamada de países ou localizações de lojas. A título de exemplo, para um recurso recente, precisei buscar uma lista de bancos de uma API externa. O método mais eficiente era fazer essa chamada de API uma vez e armazenar a resposta em um cache.
Isso significa que, subsequentemente, não precisaremos fazer a mesma chamada de API pela Internet; em vez disso, podemos apenas recuperar os dados de nosso cache, já que não esperaríamos que mudassem repentinamente. Armazenar os dados em cache ou a resposta da API nessa camada melhora o desempenho do nosso aplicativo em um grau significativo.
Com os sistemas de cache, os processos de recuperação de dados já são otimizados, pois os dados são armazenados na memória. Isso contrasta com os mecanismos de armazenamento em disco encontrados na maioria dos bancos de dados tradicionais, em que leituras e gravações (em termos de consultas) não são tão rápidas quando comparadas aos sistemas de armazenamento em memória.
Os bancos de dados in-memory geralmente são usados por aplicativos que gerenciam uma grande quantidade de dados e dependem de um tempo de resposta rápido. Com isso em mente, podemos resumir os dois principais benefícios dos bancos de dados in-memory:
- Menos viagens/processos de CPU, levando a transações mais rápidas
- Leituras/gravações mais rápidas, garantindo simultaneidade multiusuário
Por outro lado, os bancos de dados in-memory são mais voláteis do que os bancos de dados tradicionais, pois podemos perder dados facilmente se, por exemplo, a RAM travar. Os bancos de dados tradicionais têm um ótimo desempenho a esse respeito porque os dados ainda podem ser restaurados dos discos em caso de problemas.
Desempenho do Node.js em escala: empregando técnicas de cache
A velocidade com que nosso aplicativo pode processar dados é uma consideração importante de desempenho ao projetar nossa arquitetura de aplicativo. Como engenheiros, precisamos determinar explicitamente quais partes de nosso ciclo de processamento/manipulação de dados devem ser armazenadas em cache.
Os sistemas de cache não são usados isoladamente. O cache é basicamente uma camada de abstração que envolve um mecanismo de armazenamento intermediário em conjunto com um sistema de back-end (em nosso caso, Node.js) e, normalmente, um banco de dados tradicional. O objetivo é permitir um processo de recuperação de dados eficiente, e os sistemas de cache são otimizados para esse propósito específico.
Para aplicativos Node.js em particular, as estratégias de cache devem abordar as seguintes questões:
- Atualizar ou invalidar dados desatualizados de a cache : um problema muito comum no desenvolvimento da web é lidar com a lógica de expiração de cache para manter um up-cache atualizado
- Dados de cache que são acessados com frequência : o cache faz muito sentido aqui, pois podemos processar os dados uma vez, armazená-los em um cache e, em seguida, recuperá-los diretamente mais tarde, sem custos ou operações demoradas. Em seguida, precisaríamos atualizar o cache periodicamente para que os usuários pudessem ver as informações mais recentes
Problemas que vêm com escalabilidade
Grandes aplicativos precisam processar, transformar e armazenar grandes conjuntos de dados. Uma vez que os dados são absolutamente fundamentais para a funcionalidade desses aplicativos, a maneira como lidamos com os dados determina como nosso aplicativo funcionará em estado selvagem.
Os aplicativos da web eventualmente crescem para fornecer uma grande quantidade de dados. Normalmente, precisamos armazenar esses dados em sistemas de armazenamento, por exemplo, bancos de dados. Quando se trata de recuperação de dados, às vezes seria mais rápido para nós buscarmos esses dados de um mecanismo de armazenamento intermediário em vez de realizar várias consultas de banco de dados.
Quando temos muitos usuários, é necessário encontrar soluções alternativas para recuperar os dados em vez de sempre ler do disco. Os sistemas de armazenamento de aplicativos têm limites quando se trata de E/S e, portanto, faria sentido que entendêssemos cuidadosamente o melhor mecanismo para armazenar e recuperar nossos dados da maneira mais rápida possível. Bem-vindo ao mundo do armazenamento em cache com Redis.
Cache com Redis: como o Redis influencia o desempenho do aplicativo
Redis é a solução de cache preferida porque todo o banco de dados é armazenado na memória , e usa um banco de dados de disco para persistência de dados. Como o Redis é um banco de dados na memória, suas operações de acesso a dados são mais rápidas do que qualquer outro banco de dados baseado em disco, o que torna o Redis a escolha perfeita para armazenamento em cache.
Seu sistema de armazenamento de dados de valor-chave é outra vantagem porque torna o armazenamento e a recuperação muito mais simples. Usando o Redis, podemos armazenar e recuperar dados no cache usando os métodos SET e GET , respectivamente. Além disso, o Redis também funciona com tipos de dados complexos, como listas, conjuntos, strings, hashes, bitmaps e assim por diante.
O processo de armazenamento em cache com Redis é bastante simples. Quando recebemos uma solicitação do usuário para uma rota com cache habilitado, primeiro verificamos se os dados solicitados já estão armazenados no cache. Se for, podemos recuperar rapidamente os dados do cache do Redis e enviar a resposta de volta.
Se os dados não são armazenados no cache, no entanto-o que chamamos de “perda de cache”-primeiro temos que recuperar os dados do banco de dados ou de uma chamada de API externa e enviá-los ao cliente. Também nos certificamos de armazenar os dados recuperados no cache para que, da próxima vez que a mesma solicitação for feita, possamos simplesmente enviar os dados em cache de volta para o usuário.
Agora que temos uma ideia clara do que faremos, vamos começar a implementação.
Criação de um serviço de cache personalizado em Node.js
Às vezes, as consultas exigem várias operações, como recuperar dados de um banco de dados, realizar cálculos, recuperar dados adicionais de serviços de terceiros e assim por diante. Tudo isso pode afetar o desempenho geral do aplicativo. O objetivo do armazenamento em cache é melhorar a eficiência dessas operações de acesso a dados.
Nesta seção, veremos como usar o Redis para criar um cache simples para um aplicativo Node.js e, em seguida, inspecionaremos como isso afeta seu desempenho. As etapas são destacadas abaixo:
- Crie um aplicativo Node.js simples
- Escreva um serviço de implementação/cache personalizado reutilizável do Redis
- Mostre como usar o Redis para armazenar dados em cache de uma chamada de API externa pode ajudar a melhorar o desempenho de nosso aplicativo
A criação de um serviço de cache personalizado simples nos permitirá:
- Crie um serviço reutilizável que possamos empregar em várias partes de nosso aplicativo
- Normalize a API de cache e adicione mais métodos de que nosso aplicativo precisará à medida que cresce
- Substitua facilmente o módulo de cache que escolhemos por outro (se necessário)
Agora vamos! Você pode usar o repositório GitHub para acompanhar conforme prosseguimos.
Primeiro, inicializaremos rapidamente um aplicativo Node.js. simples. Podemos fazer isso executando npm init , que cria um arquivo package.json para nós:
{ "name":"performance_at_scale_node.js", "versão":"1.0.0", "descrição":"Um aplicativo de amostra para mostrar o cache do Redis e como ele afeta um benchmark de desempenho geral do aplicativo", "main":"app.js", "scripts": { "start":"node app.js" }, "palavras-chave": [ "Node.js", "Redis", "Desempenho", "Cache", "Cache", "JavaScript", "Processo interno", "LogRocket", "Frontend_Monitoring" ], "autor":"Alexander Nnakwue", "licença":"MIT", "dependências": { "@ hapi/joi":"^ 15.0.1", "axios":"^ 0.21.1", "body-parser":"^ 1.19.0", "dotenv":"^ 8.2.0", "expresso":"^ 4.17.1", "global":"^ 4.4.0", "redis":"^ 3.0.2", "util":"^ 0.12.3" }
}
No arquivo acima, instalamos algumas dependências de que precisamos para nosso aplicativo. Instalamos Redis para cache, Axios para solicitações HTTP, @ hapi/joi para esquema/ (req.body) validação, global para exigir variáveis globais, Express para nosso básico Servidor expresso e alguns outros.
A seguir, vamos configurar um servidor Express simples na raiz do diretório do nosso projeto; podemos nomear isso como quisermos. Veja o servidor expresso no arquivo app.js abaixo:
require ('dotenv'). config ()
const express=require ('express')
const bodyParser=require ('body-parser')
const config=require ('./config')
const routes=require ('./app/routes') const app=express ()
require ("./cacheManager"); app.use (bodyParser.json ())
//analisa o aplicativo/x-www-form-urlencoded
app.use (bodyParser.urlencoded ({extended: true})) //parse application/json
app.use (bodyParser.json ())
app.get ('/', (req, res)=> { //eslint-disable-next-line no-tabs res.status (200).send ('Bem-vindo ao aplicativo de cache e desempenho Node.js')
})
//adicione rotas aqui
rotas (app) //captura 404 e encaminha para o manipulador de erros
app.use ((req, res, next)=> { const err=new Error ('Não encontrado') err.status=404 res.send ('Rota não encontrada') próximo (err)
})
app.listen (process.env.PORT || config.port, ()=> { console.log (`$ {config.name} ouvindo na porta $ {config.port}!`)
}) module.exports=app
No arquivo do servidor acima, podemos ver que estamos importando um arquivo cacheManager , que basicamente lida com tudo o que tem a ver com cache assíncrono no Redis usando o util módulo. Vamos ver o conteúdo desse arquivo:
"usar estrito"; const redis=require ("redis");
const {promisify}=require ("util");
const config=require ('./config')
const redisClient=redis.createClient ( { host: config.redis_host, porta: config.redis_port }
);
const password=config.redis_password || nulo;
if (senha && senha!="nulo") { redisClient.auth (senha, (err, res)=> { console.log ("res", res); console.log ("errar", errar); });
}
experimentar{ redisClient.getAsync=promisify (redisClient.get).bind (redisClient); redisClient.setAsync=promisify (redisClient.set).bind (redisClient); redisClient.lpushAsync=promisify (redisClient.lpush).bind (redisClient); redisClient.lrangeAsync=promisify (redisClient.lrange).bind (redisClient); redisClient.llenAsync=promisify (redisClient.llen).bind (redisClient); redisClient.lremAsync=promisify (redisClient.lrem).bind (redisClient); redisClient.lsetAsync=promisify (redisClient.lset).bind (redisClient); redisClient.hmsetAsync=promisify (redisClient.hmset).bind (redisClient); redisClient.hmgetAsync=promisify (redisClient.hmget).bind (redisClient); redisClient.clear=promisify (redisClient.del).bind (redisClient);
} catch (e) { console.log ("erro de redis", e);
} redisClient.on ("conectado", function () { console.log ("Redis está conectado");
});
redisClient.on ("erro", função (err) { console.log ("Erro do Redis.", err);
});
setInterval (function () { console.log ("Mantendo-se vivo-Teste de desempenho do Node.js com Redis"); redisClient.set ('ping','pong');
}, 1000 * 60 * 4); global.cache=redisClient;
module.exports=redisClient;
Podemos ver no arquivo acima que criamos um cliente Redis e nos conectamos a um cluster Redis com o config disponível em nossa variável env . Além disso, estamos definindo um script keep-alive que é executado a cada quatro minutos:
09:02:42 web.1 | Mantendo-se vivo-Teste de desempenho do Node.js com Redis 09:06:42 web.1 | Mantendo-se vivo-Teste de desempenho do Node.js com Redis 09:10:42 web.1 | Mantendo-se vivo-Teste de desempenho do Node.js com Redis 09:14:42 web.1 | Mantendo-se vivo-Teste de desempenho do Node.js com Redis 09:18:42 web.1 | Mantendo-se vivo-Teste de desempenho do Node.js com Redis 09:22:42 web.1 | Mantendo-se vivo-Teste de desempenho do Node.js com Redis 09:26:42 web.1 | Mantendo-se vivo-Teste de desempenho do Node.js com Redis 09:30:42 web.1 | Mantendo-se vivo-Teste de desempenho do Node.js com Redis 09:34:42 web.1 | Mantendo-se vivo-Teste de desempenho do Node.js com Redis 09:38:42 web.1 | Mantendo-se vivo-Teste de desempenho do Node.js com Redis 09:42:42 web.1 | Mantendo-se vivo-Teste de desempenho do Node.js com Redis 09:46:42 web.1 | Mantendo-se vivo-Teste de desempenho do Node.js com Redis
O arquivo config que contém todas as nossas variáveis env é mostrado abaixo:
require ('dotenv'). config ()
const {env}=processo
module.exports={ nome: env.APP_NAME, baseUrl: env.APP_BASE_URL, porta: env.PORT, redis_host: env.REDIS_HOST, redis_port: env.REDIS_PORT, redis_password: env.REDIS_PASSWORD, paystack_secret_key: env.PAYSTACK_SECRET_KEY
}
Agora que concluímos toda a configuração, podemos prosseguir para a parte mais importante deste exercício: a lógica de negócios real que nos permite aplicar estratégias de cache do Redis. Veja a estrutura de pastas de nosso aplicativo abaixo:
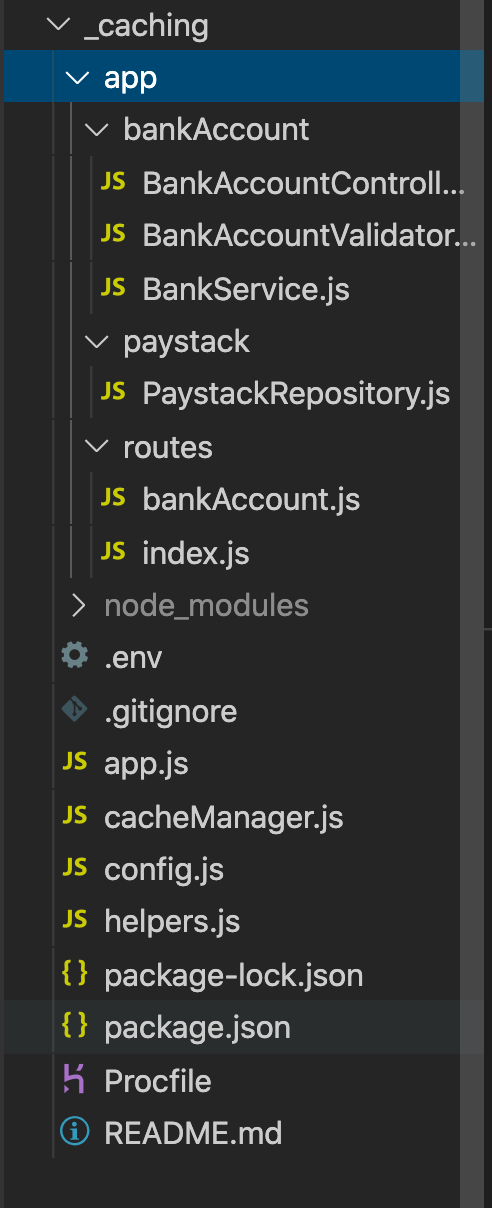
Dentro da pasta app , podemos ver um arquivo chamado paystackRepository.js dentro da pasta paystack . Este arquivo chama a API Paystack, que busca uma lista de bancos e resolve números de contas bancárias. Um link para a documentação deste recurso API Paystack pode ser encontrado aqui .
O conteúdo do arquivo paystackRepository.js está abaixo:
const axios=require ("axios");
const config=require ('../../config')
const {handleAxiosError}=require ("../../helpers");
const _axios=axios.create ({ baseURL:"https://api.paystack.co", cabeçalhos: { Autorização: `Bearer $ {config.paystack_secret_key}` }
}); exportações.bancos=assíncronos ()=> { experimentar { Retorna { dados: (aguarda _axios .get (`banco`)). data.data }; } catch (erro) { console.log ('Ocorreu um erro', erro, handleAxiosError (erro)); return {error: error.message}; }
}; exportações.resolveAccountNumber=async (bankCode, accountNumber)=> { experimentar { Retorna { dados: (aguarda _axios .get (`bank/resolve`, { params: { bank_code: bankCode, account_number: accountNumber } })). data.data }; } catch (erro) { console.log ('Ocorreu um erro', erro, handleAxiosError (erro)); return {error: error.message}; }
};
Pelo arquivo acima, podemos ver que estamos usando Axios com o cabeçalho PAYSTACK_SECRET_KEY armazenado em nossa variável env para fazer solicitações HTTP para a API do Paystack.
Dentro da pasta bankAccount , vamos dar uma olhada no arquivo BankService.js . Ele chama o arquivo paystackRepository.js para obter uma lista de bancos e resolver os números das contas bancárias, conforme analisamos acima. Também estamos armazenando os resultados em cache depois de fazer a primeira chamada de API para eliminar a necessidade de chamadas subsequentes.
"usar estrito"; const paystackRepository=require ("../paystack/PaystackRepository"); exportações.fetchAllBanks=async ()=> { //caso estejamos chamando este endpoint uma segunda vez, não precisamos fazer uma nova solicitação de API let banks=await cache.getAsync ("bank-list"); console.log ("Dados do cache", bancos); if (bancos) retornar {dados: JSON.parse (bancos)}; const {erro, dados}=espera paystackRepository.banks (); se (erro) retornar {erro}; //Armazena a lista de bancos em um cache, uma vez que raramente muda deixe cacheResponse=await cache.setAsync ("bank-list", JSON.stringify (data)); console.log ("Cache", cacheResponse); Retorna { dados }
}; export.resolveAccount=async (bankName, accountNumber)=> { //Confiar nos dados em cache é mais rápido, pois raramente muda
let banks=JSON.parse (await cache.getAsync ("bank-list")); console.log (bancos,'bancos') //Caso os dados ainda não estejam armazenados no cache (mas esperamos que estejam), faça uma chamada de API para obter listas de bancos if (! bancos) { const {erro, dados}=espera paystackRepository.banks (); se (erro) retornar {erro}; bancos=dados; } const bank=banks.find (bank=> { return bank.name==bankName }) if (! banco) retornar {erro:"Banco não encontrado"}; console.log (bank.code) const {erro, dados}=espera paystackRepository.resolveAccountNumber (bank.code, accountNumber); se (erro) retornar {erro}; Retorna { dados: { número da conta, nome do banco, accountName: data.account_name } }
}; exportações.resolveAccountPerfTest=async (bankName, accountNumber)=> { //se não houvesse nenhum mecanismo de cache, precisávamos buscar as listas de bancos compulsoriamente em cada chamada de API deixar bancos; if (bankName && accountNumber) { const {erro, dados}=espera paystackRepository.banks (); se (erro) retornar {erro}; bancos=dados; } const bank=banks.find (bank=> { return bank.name==bankName }) if (! banco) retornar {erro:"Banco não encontrado"}; const {erro, dados}=espera paystackRepository.resolveAccountNumber (bank.code, accountNumber); se (erro) retornar {erro}; Retorna { dados: { número da conta, nome do banco, accountName: data.account_name } }
};
Para o serviço fetchAllBanks , estamos obtendo a lista de bancos do Redis, mas não sem primeiro salvar os resultados no cache do Redis ao fazer a solicitação inicial da API. Além disso, podemos ver que duplicamos o método resolveAccount e removemos a implementação do Redis no segundo método chamado resolveAccountPerfTest .
Em seguida, podemos navegar até o arquivo do controlador, no qual realmente usamos estes métodos:
"usar estrito";
const bankService=require ("./BankService");
const { sendErrorResponse, sendResponse }=requer ("../../ajudantes"); exportações.fetchAllBanks=async (req, res, next)=> { const {erro, dados}=espera bankService.fetchAllBanks (); if (erro) retornar sendErrorResponse ({res, mensagem: erro}); retornar sendResponse ({res, responseBody: data});
}; exportações.resolveAccountNumber=async (req, res)=> { const {nome do banco, número da conta}=req.body; const {erro, dados}=espera bankService.resolveAccount (bankName, accountNumber); if (erro) retornar sendErrorResponse ({res, mensagem: erro}); retornar sendResponse ({res, responseBody: data});
}; exportações.resolveAccountPerfTest=async (req, res)=> { const {nome do banco, número da conta}=req.body; const {erro, dados}=esperar bankService.resolveAccountPerfTest (bankName, accountNumber); if (erro) retornar sendErrorResponse ({res, mensagem: erro}); retornar sendResponse ({res, responseBody: data});
};
Finalmente, antes de testarmos nossa implementação, podemos dar uma olhada no arquivo de rotas, localizado na pasta routes :
"usar estrito"; roteador const=requer ("expresso"). Roteador ();
const accountValidator=require ("../bankAccount/BankAccountValidator");
const accountController=require ("../bankAccount/BankAccountController"); router.get ("/banks", accountController.fetchAllBanks);
router.post ("/resolve", accountValidator.resolveAccount, accountController.resolveAccountNumber);
//ROTA DE TESTE PARA SIMULAR MÉTRICAS DE DESEMPENHO COM BASE EM CACHING NOSSAS ROTAS
router.post ("/resolve/perf/test", accountValidator.resolveAccount, accountController.resolveAccountPerfTest); módulo.exportações=roteador;
Para entender os detalhes de implementação de outros arquivos importados, consulte o código-fonte no GitHub . Além disso, observe que implantamos nosso aplicativo no Heroku para testar nossa implementação em um ambiente simulado ao vivo. O URL base é https://node-perf-with-caching-app. herokuapp.com . Embora não seja estritamente necessário, sinta-se à vontade para ler como implantar seu próprio Node. js app para Heroku também.
Agora é hora de testar nossos endpoints de API para testemunhar os benefícios de desempenho do armazenamento em cache em primeira mão. Antes de começarmos, quando testei a API pela primeira vez, demorou 9,22 segundos para retornar uma resposta. Estou assumindo que foi devido às partidas a frio habituais no Heroku. Veja a imagem abaixo:

Como esta foi nossa primeira solicitação e devido ao fato de que só executamos um script keep-alive na conexão/cluster do Redis, nosso dinamômetro pode estar inativo no momento em que fiz a solicitação. Após a primeira solicitação, excluí as listas de bancos do cache e fiz outra nova solicitação. Este é o resultado:
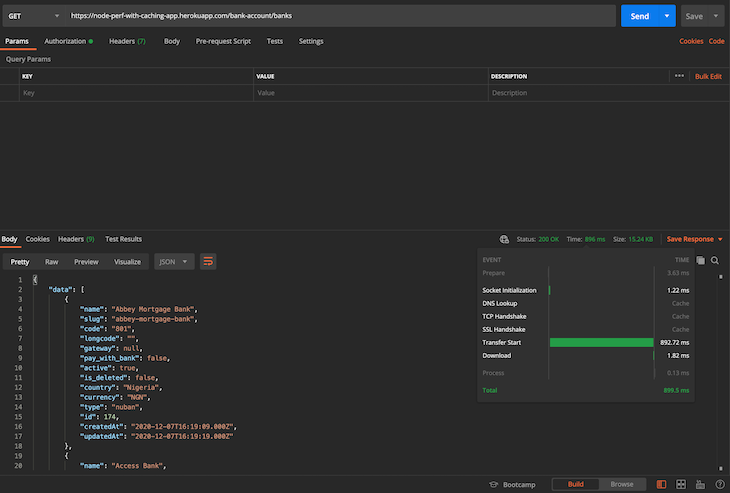
Como podemos ver na captura de tela acima, obtivemos um ciclo de resposta mais rápido na segunda solicitação, que veio em cerca de 896 ms. Muito mais rápido, certo? Observe que, após essa solicitação inicial, agora temos nossas listas de bancos em nosso cache Redis.
Fazer a solicitação uma segunda vez não é suficiente para consultar a API do Paystack externa; ele simplesmente busca os dados de nosso cache, o que é muito mais eficiente. Veja abaixo:

Como podemos ver, depois de armazenar em cache a lista de bancos, obtivemos uma resposta muito mais rápida de nossa API: cerca de 271ms.
Em resumo, a ideia é comparar o desempenho de fazer uma chamada de API externa para um serviço de terceiros com o armazenamento em cache dos resultados, em vez de fazer a mesma chamada de API novamente. Agora vimos os resultados por nós mesmos.
NB , A coleção POSTMAN usada para testar outras rotas e avaliar sua velocidade/métrica de desempenho pode ser encontrada aqui .
Como outro exemplo, usei o Redis para armazenar um token de senha descartável (OTP) gerado em um aplicativo de back-end. Este método oferece uma pesquisa mais rápida do que salvar esse token em um banco de dados e consultar o registro quando um usuário insere um valor no aplicativo cliente. Aqui está um snippet de amostra:
exports.verifyOTP=async (req, res)=> {
const {otp}=req.body
//obtenha o OTP armazenado no cache mais cedo
const getOTPDetails=await cache.getAsync ('otpKey');
const otpCode=JSON.parse (getDetails).code;
if (Número (otp)==Número (otpCode)) { return sendResponse (res,"OTP Verified Successfully", 201)
}
return sendErrorResponse (res,"Não foi possível verificar OTP. Verifique o código enviado para o seu email gain", 400)
}
Além disso, não se esqueça de que o OTP deve ter sido definido no cache no ponto de geração ou solicitação do OTP.
Conclusão
O armazenamento em cache é uma operação quase obrigatória para qualquer aplicativo com muitos dados. Ele melhora o tempo de resposta do aplicativo e ainda reduz os custos associados à largura de banda e aos volumes de dados. Ajuda a minimizar operações caras de banco de dados, chamadas de API de terceiros e solicitações de servidor para servidor, salvando uma cópia dos resultados da solicitação anterior localmente no servidor.
Em alguns casos, podemos precisar delegar o armazenamento em cache a outro aplicativo ou sistema de armazenamento de valor-chave para nos permitir armazenar e usar os dados conforme precisamos. Redis é uma opção que também podemos usar para armazenamento em cache. Ele oferece suporte a alguns recursos interessantes, incluindo estruturas de dados como strings, hashes, listas, conjuntos, conjuntos classificados com consultas de intervalo, bitmaps, HyperLogLogs e outros.
Neste tutorial, revisamos uma introdução rápida às estratégias de cache para melhorar o desempenho do nosso aplicativo Node.js. Embora existam outras ferramentas para essa finalidade, escolhemos o Redis por ser um software livre e muito popular na indústria. Agora podemos usar o Redis para armazenar em cache os dados consultados com frequência em nossos aplicativos e obter uma melhoria de desempenho considerável. Até a próxima vez! 
A postagem Cache em Node.js: Otimizando o desempenho do aplicativo com Redis apareceu primeiro no LogRocket Blog .