Se você está discutindo tecnologia em 2023, simplesmente não pode ignorar tópicos de tendência, como IA generativa e modelos de linguagem grande (LLMs) que alimentam os chatbots de IA. Após o lançamento do ChatGPT pela OpenAI, a corrida para construir o melhor LLM cresceu muito. Grandes corporações, pequenas startups e a comunidade de código aberto estão trabalhando para desenvolver os modelos de linguagem grande mais avançados. Até agora, mais de centenas de LLMs foram lançados, mas quais são os mais capazes? Para descobrir, siga nossa lista dos melhores modelos de linguagem grande (proprietária e de código aberto) em 2023.
Índice
1. GPT-4
O modelo GPT-4 da OpenAI é o melhor modelo AI de linguagem ampla (LLM) disponível em 2023. Lançado em março de 2023, o modelo GPT-4 apresentou recursos tremendos com compreensão de raciocínio complexo, capacidade de codificação avançada, proficiência em vários exames acadêmicos, habilidades que exibem desempenho de nível humano e muito mais
Na verdade, é o primeiro modelo multimodal que pode aceitar textos e imagens como entrada. Embora a capacidade multimodal ainda não tenha sido adicionada ao ChatGPT, alguns usuários têm acesso via Bing Chat, que é alimentado pelo modelo GPT-4.
Grande coisa nova de IA: o Microsoft Bing (que usa GPT-4 no Modo Criativo), aceita imagens como entrada.
Os resultados são impressionantes. Eu o alimentei com um meme, ele poderia entender o contexto e ler o texto! Uma nova dimensão de uso de IA acaba de se abrir. Portanto, espere uma enxurrada de tópicos de influenciadores do AI no Twitter… pic.twitter.com/pshP6J44tK— Ethan Mollick (@emollick) 21 de junho de 2023
Aparte a partir disso, o GPT-4 é um dos poucos LLMs que abordou a alucinação e melhorou a factualidade em uma milha. Em comparação com o ChatGPT-3.5, o modelo GPT-4 pontua perto de 80% em avaliações factuais em várias categorias. A OpenAI também trabalhou muito para tornar o modelo GPT-4 mais alinhado com os valores humanos usando Aprendizagem por Reforço de Feedback Humano (RLHF) e testes adversários por meio de especialistas de domínio.
O modelo GPT-4 foi treinado em mais de 1 trilhão de parâmetros e suporta um comprimento máximo de contexto de 32.768 tokens. Até agora, não tínhamos muitas informações sobre a arquitetura interna do GPT-4, mas recentemente George Hotz da The Tiny Corp revelou que o GPT-4 é um modelo de mistura com 8 modelos distintos com 220 bilhões de parâmetros cada. Basicamente, não é um modelo grande e denso, como entendido anteriormente.
GPT-4
Finalmente, você pode usar plug-ins ChatGPT e navegar na web com o Bing usando o modelo GPT-4. Os únicos contras são que ele é lento para responder e o tempo de inferência é muito maior, o que força os desenvolvedores a usar o modelo GPT-3.5 mais antigo. No geral, o modelo OpenAI GPT-4 é de longe o melhor LLM que você pode usar em 2023, e eu recomendo fortemente a assinatura do ChatGPT Plus se você pretende usá-lo para um trabalho sério. Custa $ 20, mas se você não quiser pagar, pode usar o ChatGPT 4 gratuitamente em portais de terceiros.
2. GPT-3.5
Depois do GPT 4, OpenAI ocupa o segundo lugar novamente com GPT-3.5. É um LLM de uso geral semelhante ao GPT-4, mas carece de experiência em domínios específicos. Falando primeiro sobre os profissionais, é um modelo incrivelmente rápido e gera uma resposta completa em segundos.
Se você lançar tarefas criativas como escrever um ensaio com ChatGPT ou elaborar um plano de negócios para ganhar dinheiro usando ChatGPT, o modelo GPT-3.5 faz um trabalho esplêndido. Além disso, a empresa lançou recentemente um comprimento de contexto maior de 16K para o modelo GPT-3.5-turbo. Para não esquecer, também é gratuito e não há restrições horárias ou diárias.
 GPT-3.5
GPT-3.5
Dito isso, sua maior desvantagem é que o GPT-3.5 alucina muito e vomita informações falsas com frequência. Portanto, para um trabalho de pesquisa sério, não sugiro usá-lo. No entanto, para questões básicas de codificação, tradução, compreensão de conceitos científicos e tarefas criativas, o GPT-3.5 é um modelo bom o suficiente.
No benchmark HumanEval, o modelo GPT-3.5 obteve 48,1%, enquanto o GPT-4 obteve 67%, o que é o mais alto para qualquer modelo de idioma grande de uso geral. Lembre-se de que o GPT-3.5 foi treinado em 175 bilhões de parâmetros, enquanto o GPT-4 é treinado em mais de 1 trilhão de parâmetros.
3. PaLM 2 (Bison-001)
Em seguida, temos o modelo PaLM 2 AI do Google, que está classificado entre os melhores modelos de linguagem grande de 2023. O Google se concentrou no raciocínio de senso comum, lógica formal, matemática, e codificação avançada em mais de 20 idiomas no modelo PaLM 2. Dizem que o maior modelo PaLM 2 foi treinado em 540 bilhões de parâmetros e tem um comprimento máximo de contexto de 4.096 tokens.
O Google anunciou quatro modelos baseados em PaLM 2 em tamanhos diferentes (Gecko, Otter, Bison e Unicorn). Dos quais, o Bison está disponível atualmente e obteve 6,40 pontos no teste MT-Bench, enquanto o GPT-4 obteve impressionantes 8,99 pontos.
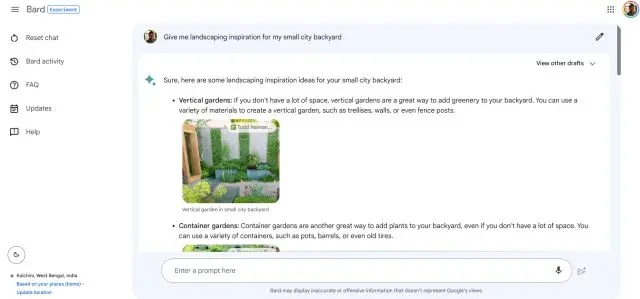 Google Bard rodando em PaLM 2
Google Bard rodando em PaLM 2
Dito isso, em avaliações de raciocínio como WinoGrande, StrategyQA, XCOPA e outras testes, o PaLM 2 faz um trabalho notável e supera o GPT-4. Também é um modelo multilíngue e pode entender expressões idiomáticas, enigmas e textos diferenciados de diferentes idiomas. Isso é algo com o qual outros LLMs lutam.
Mais uma vantagem do PaLM 2 é que ele é muito rápido para responder e oferece três respostas ao mesmo tempo. Você pode acompanhar nosso artigo e testar o modelo PaLM 2 (Bison-001) na plataforma Vertex AI do Google. Quanto aos consumidores, você pode usar o Google Bard que está rodando em PaLM 2.
4. Claude v1
Caso você não saiba, Claude é um poderoso LLM desenvolvido pela Anthropic, que tem o apoio do Google. Foi co-fundado por ex-funcionários da OpenAI e sua abordagem é construir assistentes de IA que sejam úteis, honestos e inofensivos. Em vários testes de benchmark, os modelos Claude v1 e Claude Instant da Anthropic se mostraram muito promissores. Na verdade, o Claude v1 tem um desempenho melhor do que o PaLM 2 nos testes MMLU e MT-Bench.
 Claude via Slack
Claude via Slack
É próximo ao GPT-4 e pontua 7,94 no teste MT-Bench, enquanto o GPT-4 pontua 8,99. Também no benchmark MMLU, Claude v1 garante 75,6 pontos e o GPT-4 pontua 86,4. A Anthropic também se tornou a primeira empresa a oferecer 100k tokens como a maior janela de contexto em seu modelo Claude-instant-100k. Basicamente, você pode carregar cerca de 75.000 palavras em uma única janela. Isso é absolutamente louco, certo? Se você estiver interessado, pode conferir nosso tutorial sobre como usar o Anthropic Claude agora mesmo.
5. Cohere
Cohere é uma startup de IA fundada por ex-funcionários do Google que trabalharam na equipe do Google Brain. Um de seus cofundadores, Aidan Gomez fez parte do artigo “Atenção é tudo o que você precisa” que apresentou a arquitetura do Transformer. Ao contrário de outras empresas de IA, a Cohere está aqui para empresas e resolve casos de uso de IA generativa para corporações. O Cohere tem vários modelos de pequeno a grande — tendo apenas 6B de parâmetros a modelos grandes treinados em parâmetros de 52B.
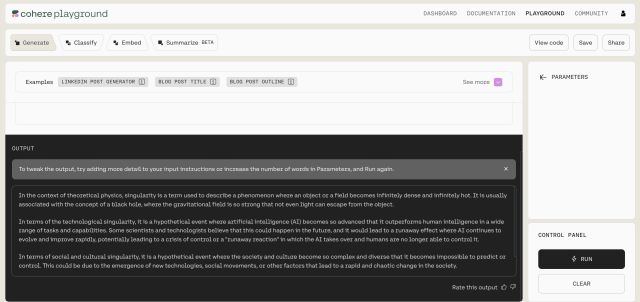
O recente modelo Cohere Command está ganhando elogios por sua precisão e robustez. De acordo com Standford HELM, o modelo Cohere Command tem a pontuação mais alta para precisão entre seus pares. Além disso, empresas como Spotify, Jasper, HyperWrite, etc. estão usando o modelo Cohere para oferecer uma experiência de IA.
Em termos de preços, o Cohere cobra US$ 15 para gerar 1 milhão de tokens, enquanto o modelo turbo da OpenAI cobra US$ 4 pela mesma quantidade de tokens. No entanto, em termos de precisão, é melhor do que outros LLMs. Portanto, se você administra um negócio e procura o melhor LLM para incorporar ao seu produto, pode dar uma olhada nos modelos da Cohere.
6. Falcon
Falcon é o primeiro modelo de linguagem grande de código aberto nesta lista e superou todos os modelos de código aberto lançados até agora, incluindo LLaMA, StableLM, MPT e muito mais. Foi desenvolvido pelo Technology Innovation Institute (TII), Emirados Árabes Unidos. A melhor coisa sobre o Falcon é que ele tem código aberto com licença Apache 2.0, o que significa que você pode usar o modelo para fins comerciais. Também não há royalties ou restrições.

Até agora, o TII lançou dois modelos Falcon, que são treinados nos parâmetros 40B e 7B. O desenvolvedor sugere que esses são modelos brutos, mas se você quiser usá-los para conversar, deve optar pelo modelo Falcon-40B-Instruct, ajustado para a maioria dos casos de uso.
O modelo Falcon foi treinado principalmente em inglês, alemão, espanhol e francês, mas também pode funcionar nos idiomas italiano, português, polonês, holandês, romeno, tcheco e sueco. Portanto, se você estiver interessado em modelos de IA de código aberto, primeiro dê uma olhada no Falcon.
7. LLaMA
Desde que os modelos LLaMA vazaram online, a Meta foi all-in em código aberto. Ela lançou oficialmente modelos LLaMA em vários tamanhos, de 7 bilhões de parâmetros a 65 bilhões de parâmetros. De acordo com a Meta, seu modelo LLaMA-13B supera o modelo GPT-3 da OpenAI, que foi treinado em 175 bilhões de parâmetros. Muitos desenvolvedores estão usando o LLaMA para ajustar e criar alguns dos melhores modelos de código aberto existentes. Dito isso, lembre-se de que o LLaMA foi lançado apenas para pesquisa e não pode ser usado comercialmente, ao contrário do modelo Falcon do TII.

Falando sobre o modelo LLaMA 65B, é mostrou uma capacidade incrível na maioria dos casos de uso. Ele está entre os 10 melhores modelos no Open LLM Leaderboard em Hugging Face. A Meta diz que não usou nenhum material proprietário para treinar o modelo. Em vez disso, a empresa usou dados disponíveis publicamente de CommonCrawl, C4, GitHub, ArXiv, Wikipedia, StackExchange e muito mais.
Simplificando, após o lançamento do modelo LLaMA pela Meta, a comunidade de código aberto viu uma rápida inovação e surgiu com novas técnicas para fazer modelos menores e mais eficientes.
8. Guanaco-65B
Entre os vários modelos derivados do LLaMA, o Guanaco-65B revelou-se o melhor LLM de código aberto, logo após o modelo Falcon. No teste MMLU, obteve 52,7, enquanto o modelo Falcon obteve 54,1. Da mesma forma, na avaliação do TruthfulQA, o Guanaco obteve uma pontuação de 51,3 e o Falcon foi um pouco mais alto, com 52,5. Existem quatro sabores de Guanaco: modelos 7B, 13B, 33B e 65B. Todos os modelos foram ajustados no conjunto de dados OASST1 por Tim Dettmers e outros pesquisadores.
Quanto a como o Guanaco foi ajustado, os pesquisadores criaram uma nova técnica chamada QLoRA que reduz eficientemente o uso de memória enquanto preserva o desempenho total da tarefa de 16 bits. No benchmark Vicuna, o modelo Guanaco-65B supera até mesmo ChatGPT (modelo GPT-3.5) com um tamanho de parâmetro muito menor.
A melhor parte é que o modelo 65B foi treinado em uma única GPU com 48 GB de VRAM em apenas 24 horas. Isso mostra até que ponto os modelos de código aberto chegaram na redução de custos e na manutenção da qualidade. Resumindo, se você quiser experimentar um LLM local offline, pode definitivamente tentar os modelos Guanaco.
9. Vicuna 33B
Vicuna é outro poderoso LLM de código aberto desenvolvido pela LMSYS. Foi derivado do LLaMA como muitos outros modelos de código aberto. Ele foi ajustado usando instrução supervisionada e os dados de treinamento foram coletados de sharegpt.com, um portal onde os usuários compartilham suas incríveis conversas ChatGPT. É um modelo de linguagem grande auto-regressivo e é treinado em 33 bilhões de parâmetros.
No teste MT-Bench da própria LMSYS, ele marcou 7,12, enquanto o melhor modelo proprietário, o GPT-4, garantiu 8,99 pontos. Também no teste MMLU obteve 59,2 pontos e o GPT-4 obteve 86,4 pontos. Apesar de ser um modelo bem menor, o desempenho da Vicunha é notável. Você pode conferir a demonstração e interagir com o chatbot clicando no link abaixo.
10. MPT-30B
O MPT-30B é outro LLM de código aberto que compete com os modelos derivados do LLaMA. Ele foi desenvolvido pela Mosaic ML e aperfeiçoado em um grande corpus de dados de diferentes fontes. Ele usa conjuntos de dados de ShareGPT-Vicuna, Camel-AI, GPTeacher, Guanaco, Baize e outras fontes. A melhor parte desse modelo de código aberto é que ele tem um comprimento de contexto de 8 mil tokens.
Além disso, supera o modelo GPT-3 da OpenAI e pontua 6,39 no teste MT-Bench da LMSYS. Se você está procurando um pequeno LLM para rodar localmente, o modelo MPT-30B é uma ótima escolha.
11. 30B-Lazarus
O modelo 30B-Lazarus foi desenvolvido pela CalderaAI e usa o LLaMA como seu modelo fundamental. O desenvolvedor usou conjuntos de dados ajustados para LoRA de vários modelos, incluindo Manticore, SuperCOT-LoRA, SuperHOT, GPT-4 Alpaca-LoRA e muito mais. Como resultado, o modelo tem um desempenho muito melhor em muitos benchmarks LLM. Marcou 81,7 no HellaSwag e 45,2 no MMLU, atrás apenas de Falcon e Guanaco. Se o seu caso de uso for principalmente geração de texto e não bate-papo, o modelo 30B Lazarus pode ser uma boa escolha.
12. WizardLM
WizardLM é nosso próximo modelo de linguagem grande de código aberto que é construído para seguir instruções complexas. Uma equipe de pesquisadores de IA criou uma abordagem Evol-instruct para reescrever o conjunto inicial de instruções em instruções mais complexas. E os dados de instrução gerados são usados para ajustar o modelo LLaMA.
Devido a essa abordagem, o modelo WizardLM tem um desempenho muito melhor em benchmarks e os usuários preferem a saída do WizardLM do que as respostas do ChatGPT. No teste MT-Bench, o WizardLM obteve 6,35 pontos e 52,3 no teste MMLU. No geral, para apenas 13B de parâmetros, o WizardLM faz um bom trabalho e abre as portas para modelos menores.
Bônus: GPT4All
GPT4ALL é um projeto executado pela Nomic AI. Eu o recomendo não apenas por seu modelo interno, mas para executar LLMs locais em seu computador sem nenhuma GPU dedicada ou conectividade com a Internet. Ela desenvolveu um modelo 13B Snoozy que funciona muito bem. Eu testei no meu computador várias vezes e ele gera respostas muito rápidas, visto que tenho um PC básico. Também usei o PrivateGPT no GPT4All e ele realmente respondeu a partir do conjunto de dados personalizado.
Além disso, abriga 12 modelos de código aberto de diferentes organizações. A maioria deles é construída em parâmetros 7B e 13B e pesa cerca de 3 GB a 8 GB. O melhor de tudo é que você obtém um instalador de GUI onde pode selecionar um modelo e começar a usá-lo imediatamente. Sem mexer no Terminal. Simplificando, se você deseja executar um LLM local em seu computador de maneira amigável, o GPT4All é a melhor maneira de fazer isso.
Deixe um comentário
O RTX 4060 Ti finalmente chegou, chegando com o RTX 4060 básico em um ponto de preço atraente o suficiente para fazer os jogadores considerarem atualizar sua placa gráfica. Mas você deveria? Iremos nos aprofundar e comparar o RTX 4060 […]
Há muito debate na internet sobre AR (realidade aumentada) vs VR (realidade virtual), então não adicionarei mais combustível para o fogo, mas uma das coisas que notamos ao usar o Nreal Air é que o VR […]
Existem algumas opções de design questionáveis em Redfall, uma mistura da famosa fórmula incompleta de Arkane. Adoro jogos feitos pela Arkane Studios, com Dishonored se tornando um título que revisito de vez em quando por sua jogabilidade emergente única. E […]