O Node.js ganhou muita popularidade nos últimos anos. É usado por grandes nomes como LinkedIn, eBay e Netflix, o que prova que foi bem testado em batalhas. Neste tutorial, aprenderemos como usar clustering em Node.js para obter grandes benefícios de desempenho usando todas as CPUs disponíveis. Vamos começar.
A necessidade de clustering no Node.js
Uma instância do Node.js é executada em um único thread. A página “sobre” oficial do Node.js afirma: “O Node.js sendo projetado sem threads não significa que você não pode tirar proveito de vários núcleos em seu ambiente.” É onde ele aponta para o módulo de cluster.
O documento do módulo de cluster adiciona: “Para tirar proveito de sistemas multi-core, o usuário às vezes vai querer lançar um cluster de processos Node.js para lidar com a carga. ” Portanto, para aproveitar as vantagens dos vários processadores no sistema executando Node.js, devemos usar o módulo de cluster.
Explorar os núcleos disponíveis para distribuir a carga entre eles dá ao nosso aplicativo Node.js um aumento de desempenho. Como a maioria dos sistemas modernos tem vários núcleos, devemos usar o módulo de cluster em Node.js para obter o máximo de desempenho dessas máquinas mais novas.
Como funciona o módulo de cluster Node.js?
Em poucas palavras, o módulo Node.js cluster atua como um balanceador de carga para distribuir a carga para os processos filho em execução simultaneamente em uma porta compartilhada. O Node.js não é muito bom com código de bloqueio, ou seja, se houver apenas um processador e ele for bloqueado por uma operação pesada e com uso intensivo de CPU, outras solicitações estarão apenas esperando na fila pela conclusão dessa operação.
Com vários processos, se um processo está ocupado com uma operação relativamente intensiva da CPU, outros processos podem assumir as outras solicitações que chegam, utilizando as outras CPUs/núcleos disponíveis. Este é o poder do módulo de cluster em que os trabalhadores compartilham a carga e o aplicativo não para devido à alta carga.
O processo mestre pode distribuir a carga para o processo filho de duas maneiras. O primeiro (e padrão) é um método round-robin. A segunda forma é que o processo mestre escuta um soquete e envia o trabalho para os trabalhadores interessados. Os trabalhadores então processam as solicitações recebidas.
No entanto, o segundo método não é muito claro e fácil de compreender como a abordagem round-robin básica.
Chega de teoria, vamos ter dê uma olhada em alguns pré-requisitos antes de mergulhar no código.
Pré-requisitos
Para seguir este guia sobre clustering em Node.js, você deve ter o seguinte:
Nó. js rodando em sua máquina Conhecimento prático de Node.js e Express Conhecimento básico sobre como processos e threads funcionam Conhecimento prático de Git e GitHub
Agora, vamos passar para o código deste tutorial.
Construindo um simples Servidor Express sem clustering
Começaremos criando um servidor Express simples. Este servidor fará uma tarefa computacional relativamente pesada que bloqueará deliberadamente o evento loop . Nosso primeiro exemplo será sem qualquer cluster.
Para configurar o Express em um novo projeto, podemos executar o seguinte na CLI:
mkdir nodejs-cluster cd nodejs-cluster npm init-y npm install–save express
Em seguida, criaremos um arquivo chamado no-cluster.js na raiz do projeto como abaixo:
O conteúdo do no-cluster. O arquivo js será o seguinte:
js const express=require (‘express’); porta const=3001; const app=express (); console.log (`Worker $ {process.pid} started`); app.get (‘/’, (req, res)=> {res.send (‘Hello World!’);}) app.get (‘/api/slow’, function (req, res) {console.time (‘slowApi’); const baseNumber=7; let result=0; for (let i=Math.pow (baseNumber, 7); i>=0; i–) {result +=Math.atan (i) * Math.tan (i);}; console.timeEnd (‘slowApi’); console.log (`O número do resultado é $ {result}-no processo $ {process.pid}`); res.send (`O número do resultado é $ {resultado} `);}); app.listen (port, ()=> {console.log (`App ouvindo na porta $ {port}`);});
Vejamos o que o código está fazendo. Começamos com um servidor Express simples que será executado na porta 3001. Ele tem dois URIs (/) que mostram Hello World! e outro caminho/api/lento.
O método lento da API GET tem um longo loop que faz um loop 77, que é 823.543 vezes. Em cada loop, ele faz um math.atan (), ou um arco-tangente (em radianos) de um número, e um math.tan (), a tangente de um número. Ele adiciona esses números à variável de resultado. Depois disso, ele registra e retorna esse número como a resposta.
Sim, tornou-se deliberadamente demorado e intensivo para ver seus efeitos com um cluster mais tarde. Podemos testá-lo rapidamente com o node no-cluser.js e clicar em http://localhost: 3001/api/slow que irá forneça o seguinte resultado:
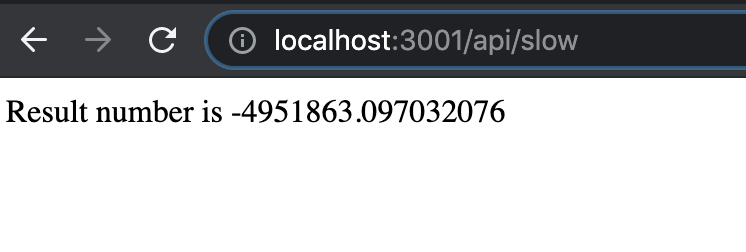
A CLI onde o processo Node.js está sendo executado se parece com a imagem abaixo:

Como visto acima, a API demorou 37,432 milissegundos para 823.543 loops terminarem de acordo com nosso perfil adicionado com chamadas console.time e console.timeEnd.
O código até este ponto está acessível como solicitação de pull para sua referência. Em seguida, criaremos outro servidor semelhante, mas com o módulo de cluster.
Adicionando clustering Node.js a um servidor Express
Adicionaremos um arquivo index.js que se parece com o arquivo no-cluster.js acima, mas usará o módulo de cluster neste exemplo. O código para o arquivo index.js se parece com o seguinte:
const express=require (‘express’); porta const=3000; const cluster=require (‘cluster’); const totalCPUs=require (‘os’). cpus (). length; if (cluster.isMaster) {console.log (`Número de CPUs é $ {totalCPUs}`); console.log (`Master $ {process.pid} está em execução`);//Trabalhadores da bifurcação. para (seja i=0; i
Vejamos o que este código está fazendo. Primeiro, exigimos o módulo expresso e, em seguida, exigimos o módulo cluster. Depois disso, obtemos o número de CPUs disponíveis com require (‘os’). Cpus (). Length. Foram oito no meu caso em um Macbook Pro com Node.js 14 em execução.
Conseqüentemente, verificamos se o cluster é mestre. Depois de alguns console.logs, bifurcamos os workers a mesma quantidade de vezes que o número de CPUs disponíveis. Nós apenas pegamos a saída de um trabalhador, registramos e bifurcamos outro.
Se não for o processo mestre, é o processo filho, e aí chamamos a função startExpress. Esta função é a mesma do servidor Express no exemplo anterior sem clustering.
Quando executamos o arquivo index.js acima com o nó index.js, vemos a seguinte saída:
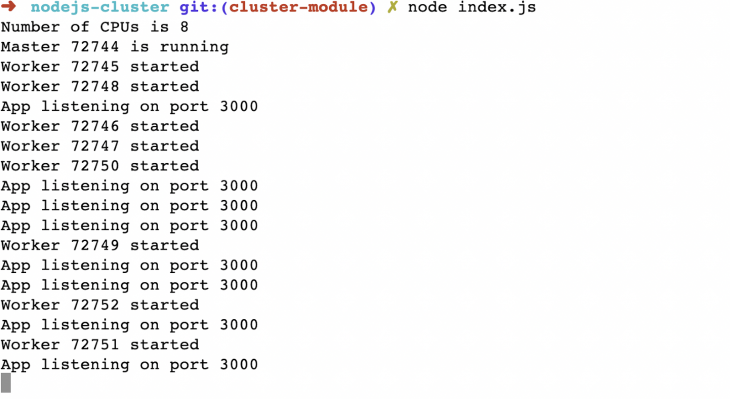
Como podemos ver, todas as oito CPUs têm oito workers relevantes em execução, prontos para aceitar qualquer solicitação que chegue. Se atingirmos http://localhost: 3000/api/slow veremos a seguinte saída:
O código para o servidor com o módulo de cluster está neste solicitação pull . Em seguida, faremos o teste de carga de um servidor Express com e sem cluster para avaliar a diferença nos tempos de resposta e o número de solicitações por segundo que ele pode manipular.
Carregar servidores de teste com e sem cluster
Para testar a carga de nossos servidores Node.js com e sem cluster, usaremos o Ferramenta de teste de carga Vegeta . Outras opções podem ser o pacote NPM teste de carga ou o ferramenta de benchmark Apache também. Acho o Vegeta mais fácil de instalar e usar, pois é um binário Go, e os executáveis pré-compilados são fáceis de instalar e começar.
Depois de ter o Vegeta em execução em nossa máquina, podemos executar o seguinte comando para inicie o servidor Node.js sem nenhum cluster ativado:
node no-cluster.js
Em outra guia CLI, podemos executar o seguinte comando para enviar 50 solicitações por segundo por 30 segundos com Vegeta:
echo”OBTER http://localhost: 3001/api/slow”| ataque vegeta-duração=30s-taxa=50 | vegeta report–type=text
Irá resultar em uma saída como abaixo após cerca de 30 segundos. Se você verificar a outra guia com Node.js em execução, verá muitos logs fluindo:
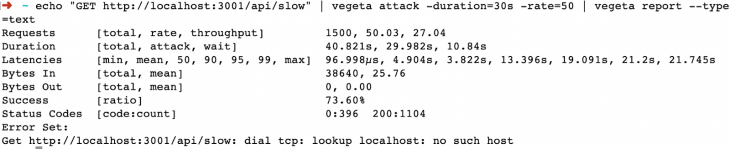
Algumas dicas rápidas do teste de carga acima. Um total de 1.500 (50 * 30) solicitações foram enviadas e o servidor teve uma boa resposta máxima de 27,04 solicitações por segundo. O tempo de resposta mais rápido foi de 96,998 microssegundos e o mais lento de 21,745 segundos. Da mesma forma, apenas 1.104 solicitações retornaram com 200 códigos de resposta, o que significa uma taxa de sucesso de 73,60% sem o módulo de cluster.
Vamos parar esse servidor e executar o outro servidor com módulo de cluster com:
índice de nó.js
Se rodarmos o mesmo teste de 50 RPS por 30 segundos, neste segundo servidor podemos ver a diferença. Podemos executar o teste de carga executando:
echo”GET http://localhost: 3000/api/slow”| ataque vegeta-duração=30s-taxa=50 | vegeta report–type=text
Após 30 segundos, a saída será semelhante a esta:
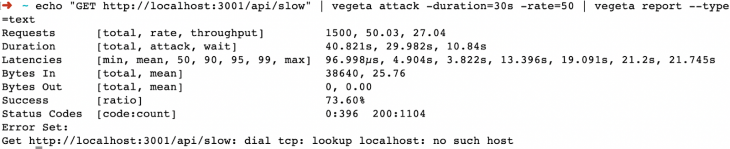
Podemos ver claramente uma grande diferença aqui, pois o servidor pode explorar todos as CPUs disponíveis, não apenas uma. Todas as 1.500 solicitações foram bem-sucedidas, voltando com um código de resposta 200. A resposta mais rápida foi de 31,608 milissegundos e a mais lenta de apenas 42,883 milissegundos em comparação com 27 segundos sem o módulo de cluster.
A taxa de transferência também foi de 50, portanto, desta vez, o servidor não teve problemas para lidar com 50 solicitações por segundo ( RPS) por 30 segundos. Com todos os oito núcleos disponíveis para processar, ele pode facilmente lidar com uma carga maior do que os 27 RPS anteriores.
Se você olhar para a guia CLI com o servidor Node.js com cluster, deve mostrar algo assim:
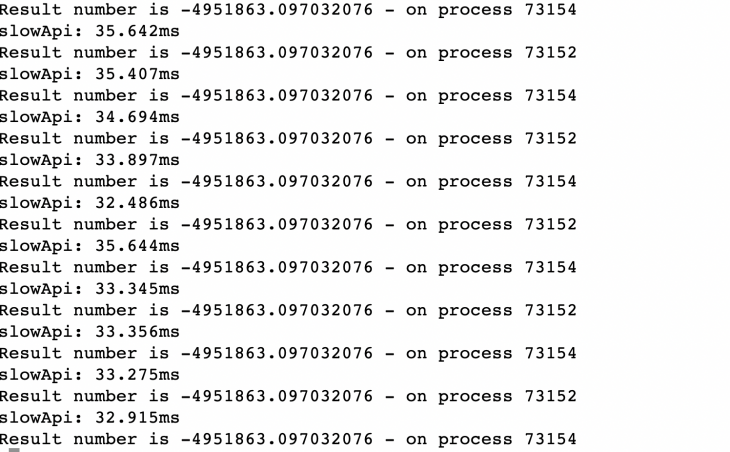
Isso nos diz que pelo menos dois dos processadores foram usados para atender às solicitações. Se tivéssemos tentado com, digamos, 100 solicitações por segundo, isso usaria mais CPUs e processos conforme a necessidade. Você certamente pode fazer uma tentativa com 100 RPS por 30 segundos e ver como ele se sai. Ele atingiu o máximo em cerca de 102 RPS em minha máquina.
De 27 RPS sem cluster a 102 RPS com cluster, o módulo de cluster tem uma taxa de sucesso de resposta quase quatro vezes melhor. Esta é a vantagem de usar um módulo de cluster para usar todos os recursos de CPU disponíveis.
Próximas etapas
Usar clustering sozinho é benéfico para o desempenho, conforme visto acima. Para um sistema de nível de produção, seria melhor usar um software testado em batalha, como PM2 . Ele tem o modo de cluster integrado e inclui outros excelentes recursos, como gerenciamento de processos e registros.
Da mesma forma, para um aplicativo Node.js de nível de produção em execução em contêineres no Kubernetes, a parte de gerenciamento de recursos pode ser melhor tratada por Kubernetes.
Essas são as decisões e compensações que você e sua equipe de engenharia de software precisarão tomar para ter um aplicativo Node.js mais escalonável, eficiente e resiliente em execução em um ambiente de produção.
Conclusão
Neste artigo, aprendemos como explorar os módulos de cluster Node.js para utilizar totalmente os núcleos de CPU disponíveis para extrair melhor desempenho de nosso aplicativo Node.js. Entre outras coisas, o clustering pode ser mais uma ferramenta útil no arsenal do Node.js para obter melhor rendimento.