Il s’avère , L’IA s’est trompée pendant tout ce temps. Une équipe de chercheurs dirigée par le MIT a découvert qu’un peu plus de 3% des données des systèmes d’apprentissage automatique les plus utilisés ont été étiquetées de manière incorrecte. Les chercheurs ont examiné 10 grands ensembles de données d’apprentissage automatique et ont constaté que 3,4% des données disponibles pour le intelligence artificielle ont été mal étiquetés. Il existe plusieurs types d’erreurs, y compris les avis Amazon et IMDB étiquetés à tort comme positifs alors qu’ils peuvent en fait être négatifs, et le marquage basé sur une image qui peut identifier de manière incorrecte le sujet dans l’image. Il y a également des erreurs liées à la vidéo, comme une vidéo YouTube étant étiquetée comme une cloche d’église.
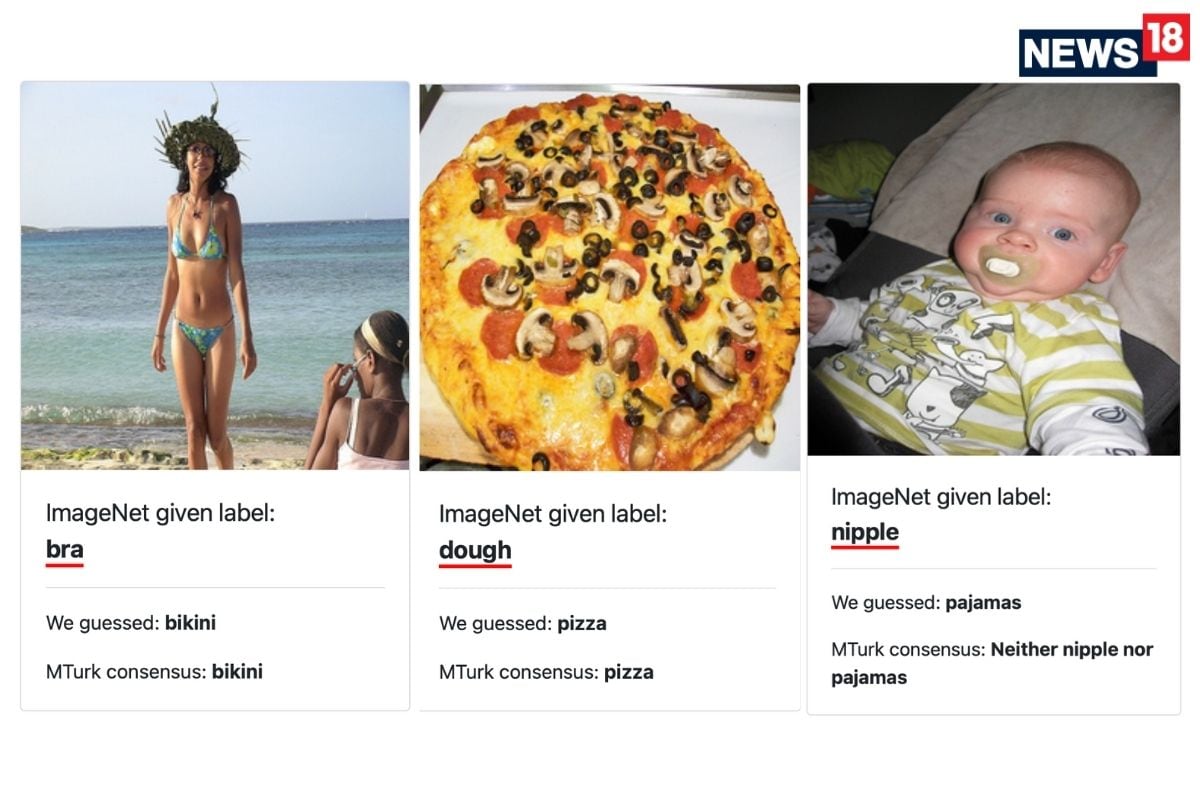
“Nous identifions des erreurs d’étiquette dans les ensembles de test de 10 des la vision par ordinateur, le langage naturel et les ensembles de données audio les plus couramment utilisés, et étudier par la suite le potentiel que ces erreurs d’étiquette affectent les résultats de référence. Les erreurs dans les ensembles de tests sont nombreuses et répandues: nous estimons une moyenne de 3,4% d’erreurs sur les 10 ensembles de données, où, par exemple, 2916 erreurs d’étiquette représentent 6% de l’ensemble de validation ImageNet », affirment les chercheurs dans l’article intitulé« Erreurs d’étiquettes omniprésentes dans Les ensembles de tests déstabilisent les benchmarks de Machine Learning ». Les erreurs qui sont très apparentes comprennent une image d’un bébé identifié comme un mamelon, une photo d’une pizza prête à manger étiquetée comme de la pâte, une baleine étiquetée comme un grand requin blanc et des maillots de bain étant identifiés comme un soutien-gorge.
Le problème avec les ensembles de données mal étiquetés dans les systèmes d’apprentissage automatique est que l’IA apprend alors l’identification et les connaissances incorrectes, ce qui rendra plus difficile pour les systèmes basés sur l’IA de fournir les bons résultats. Ou pour nous, humains, de pouvoir lui faire confiance. L’IA fait désormais partie intégrante de nombreux éléments avec lesquels nous nous connectons au quotidien, tels que les services Web, les smartphones, les haut-parleurs intelligents, etc. Les chercheurs affirment que les modèles de capacité inférieure peuvent être pratiquement plus utiles que les modèles de capacité supérieure dans des ensembles de données du monde réel avec des proportions élevées de données étiquetées à tort. Ils donnent l’exemple d’ImageNet avec des données corrigées, où «ResNet-18 surpasse ResNet50 si la prévalence d’exemples de tests initialement mal étiquetés augmente de seulement 6%. Sur CIFAR-10 avec des étiquettes corrigées: VGG-11 surpasse VGG-19 si la prévalence d’exemples de test mal étiquetés à l’origine augmente de seulement 5%. »