Un gruppo di informatici di diverse università ha rilasciato un LLM multimodale open source chiamato LLaVA, e la scorsa settimana mi sono imbattuto in esso mentre scorrevo Twitter. Simile a GPT-4, questo LLM può elaborare sia input di testo che di immagini. Il progetto utilizza un LLM generico e un codificatore di immagini per creare un modello Large Language and Vision Assistant. Dato che le funzionalità propagandate sembravano promettenti, ho deciso di testare questo modello di linguaggio di grandi dimensioni per capire quanto sia accurato e affidabile e cosa possiamo aspettarci dal prossimo modello multimodale di GPT4 (in particolare le sue capacità visive). Su quella nota, andiamo avanti ed esploriamo LLaVA.
Sommario
Che cos’è LLaVA, un modello linguistico multimodale?
LLaVA (Large Language-and-Vision Assistant) è un LLM multimodale, simile al GPT-4 di OpenAI, che può gestire sia gli input di testo che di immagini. Sebbene OpenAI non abbia ancora aggiunto la capacità di elaborazione delle immagini a GPT-4, un nuovo progetto open source lo ha già fatto infondendo un codificatore di visione.
Sviluppato da scienziati informatici dell’Università del Wisconsin-Madison, Microsoft Research e Columbia University, il progetto mira a dimostrare come funzionerebbe un modello multimodale e confrontare le sue capacità con GPT-4.
È utilizza Vigogna come modello linguistico di grandi dimensioni (LLM) e CLIP ViT-L/14 come codificatore visivo, che, per chi non lo sapesse, è stato sviluppato da OpenAI. Il progetto ha generato dati multimodali di alta qualità che seguono le istruzioni utilizzando GPT-4 e ciò si traduce in prestazioni eccellenti. Raggiunge il 92,53% nel benchmark ScienceQA.
A parte questo, è stato messo a punto per set di dati di ragionamento e chat visivi generici, in particolare dal dominio scientifico. Pertanto, nel complesso, LLaVA è un punto di partenza della nuova realtà multimodale ed ero piuttosto entusiasta di provarlo.
Come utilizzare l’Assistente visivo di LLaVA in questo momento
1. Per utilizzare LLaVA, puoi andare su llava.hliu.cc e dare un’occhiata alla demo. Al momento utilizza il modello LLaVA-13B-v1.
2. Aggiungi semplicemente un’immagine nell’angolo in alto a sinistra e seleziona”Ritaglia“. Assicurati di aggiungere immagini quadrate per il miglior risultato.
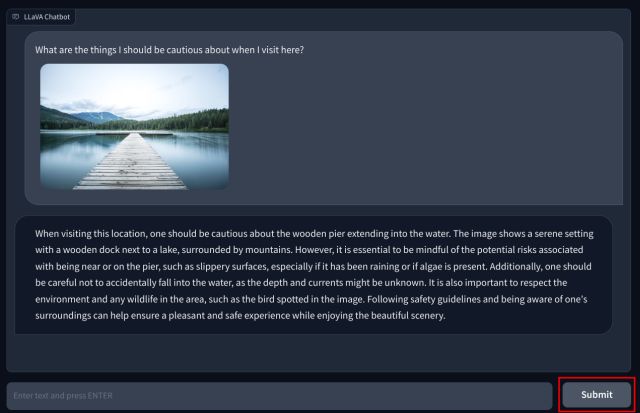
3. Ora, aggiungi la tua domanda in fondo e premi”Invia”. L’LLM studierà quindi l’immagine e spiegherà tutto in dettaglio. Puoi anche porre domande di follow-up sull’immagine che carichi.
LLM multimodale con capacità visive: prime impressioni
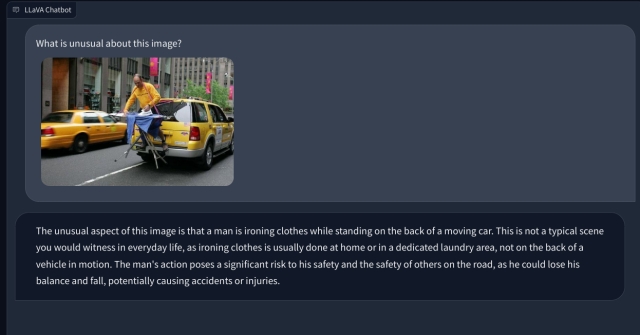
Per verificare le capacità visive di LLaVA, abbiamo iniziato con alcuni esempi di base. Abbiamo caricato un dipinto e chiesto a LLaVA di identificare il dipinto, e ha risposto correttamente alla domanda. Ho anche posto alcune domande di follow-up, e anche in questo ha fatto un buon lavoro.
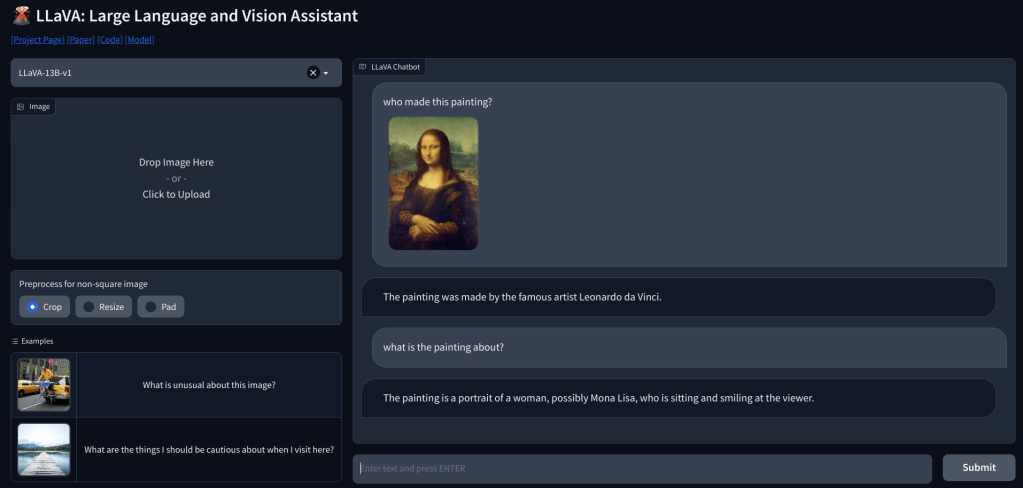
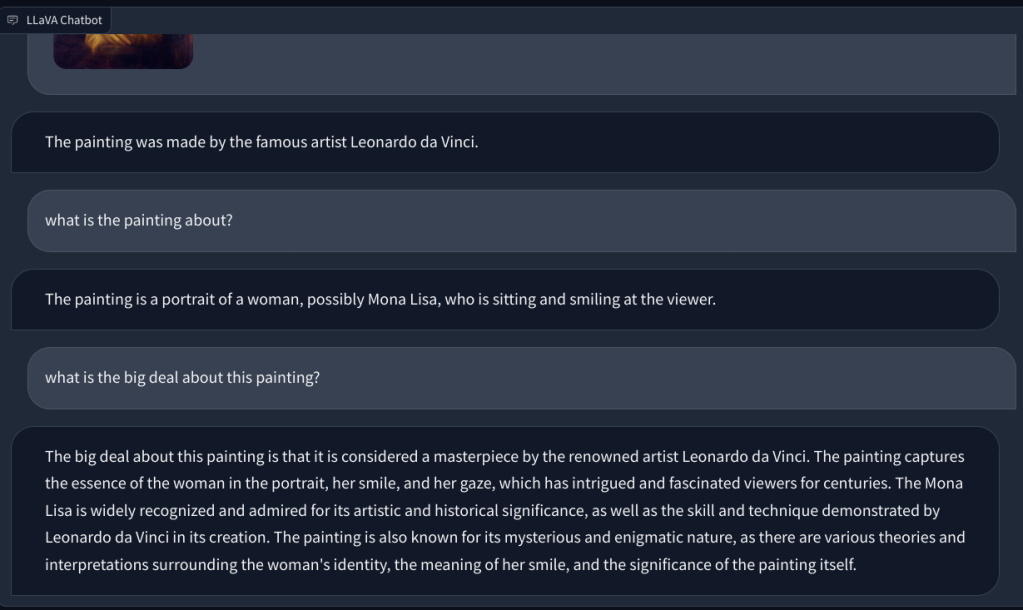
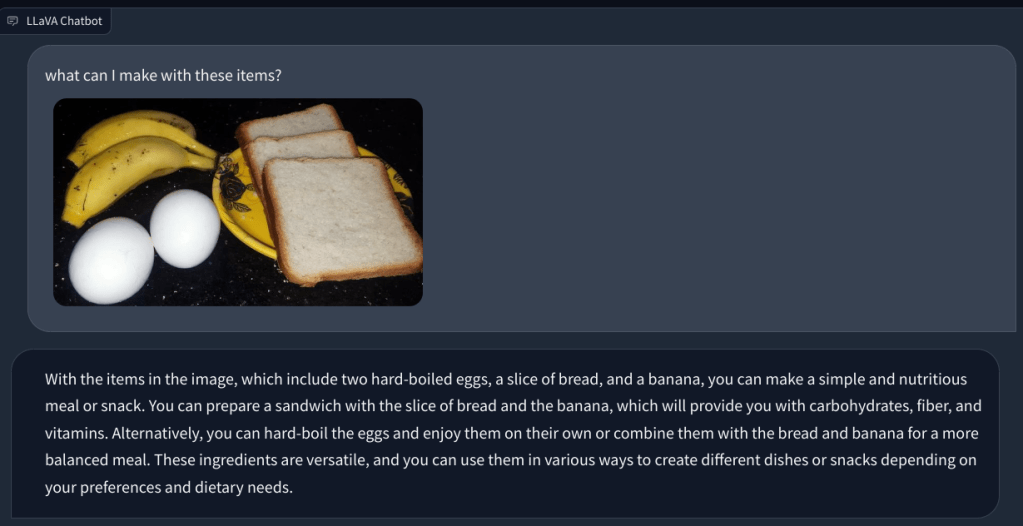
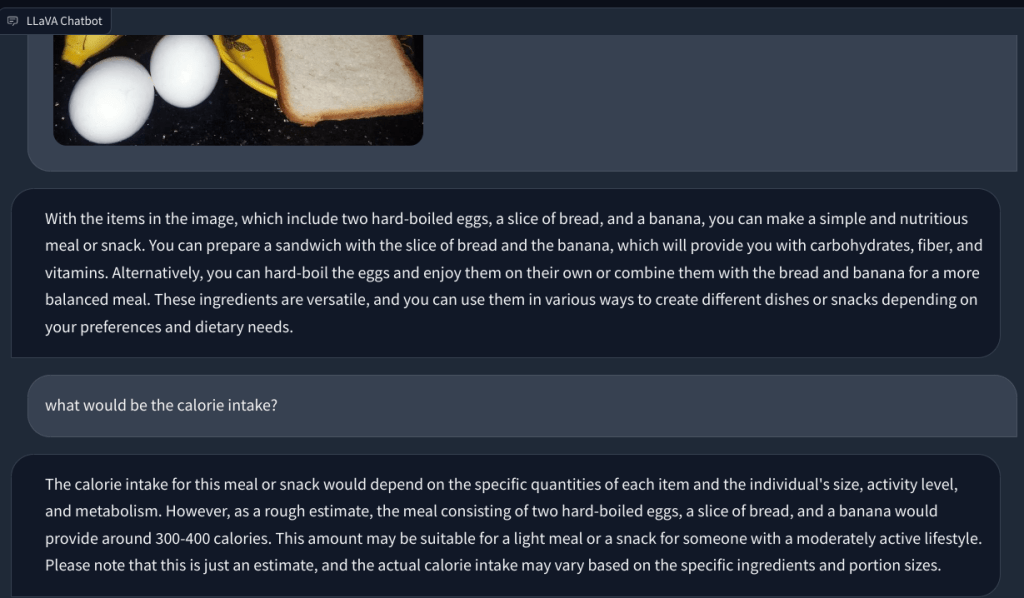
In un altro esempio, ho caricato un’immagine di prodotti alimentari e ho posto domande sul tipo di colazione che si può preparare e quale sarebbe il totale apporto calorico. Ha identificato correttamente ogni elemento e ha fornito ricette alimentari e un conteggio approssimativo delle calorie. Sebbene le ricette non fossero così dettagliate, il LLM multimodale ha suggerito idee per incorporare i tre alimenti in un piatto/pasto.
Poi, ho aggiunto un image con una nota scritta a mano che gli chiede di scrivere uno script Python per l’algoritmo Bubble sort. Ma non è riuscito a riconoscere il testo sulla carta. E non poteva eseguire il codice. Poi, ho aggiunto una semplice domanda matematica e ho chiesto il valore di x, ma ancora una volta ha dato la risposta sbagliata.
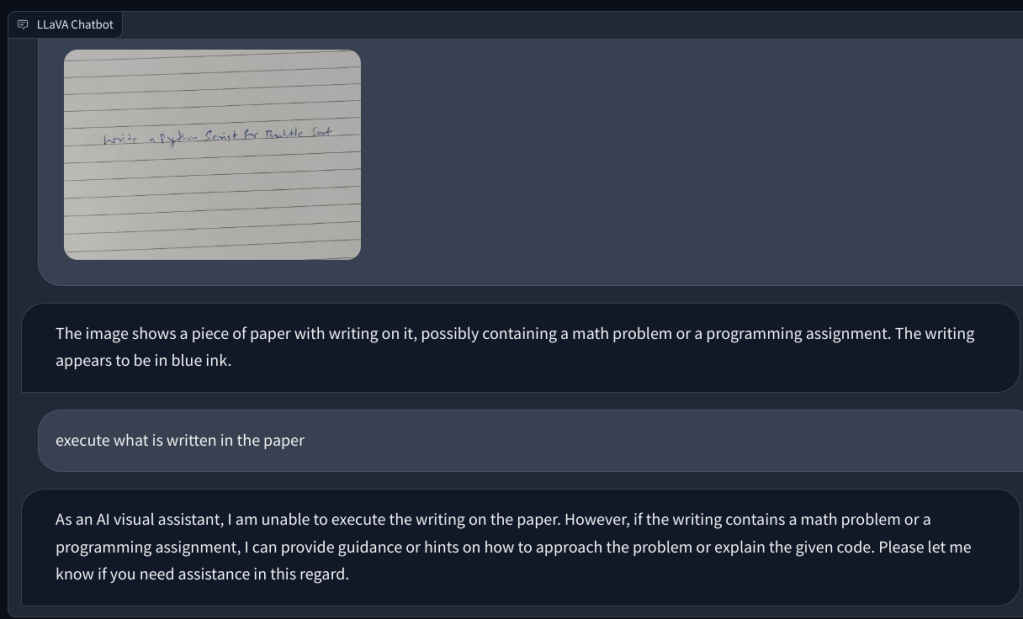
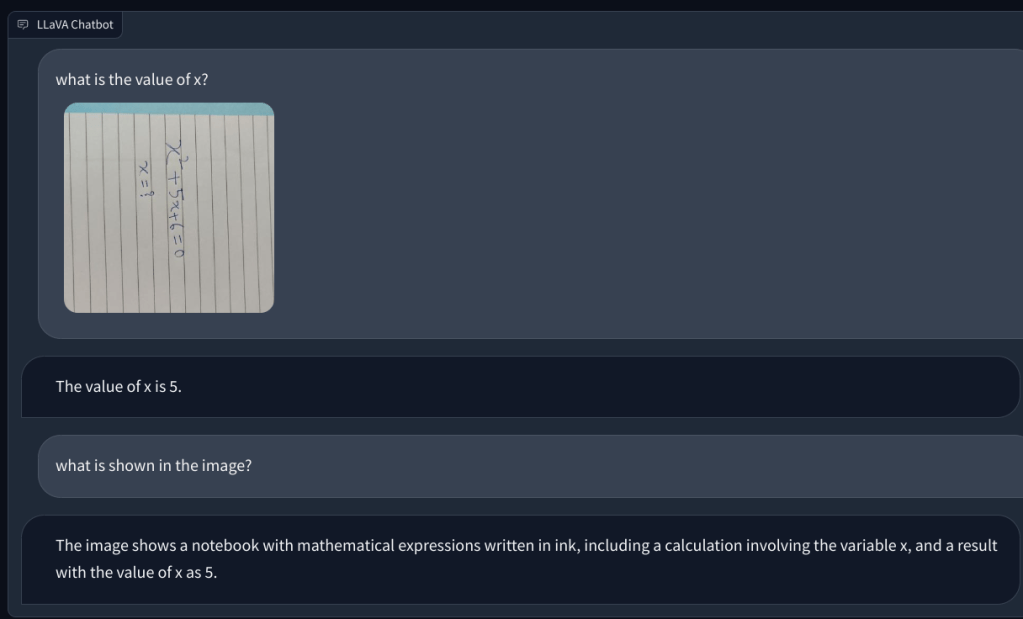
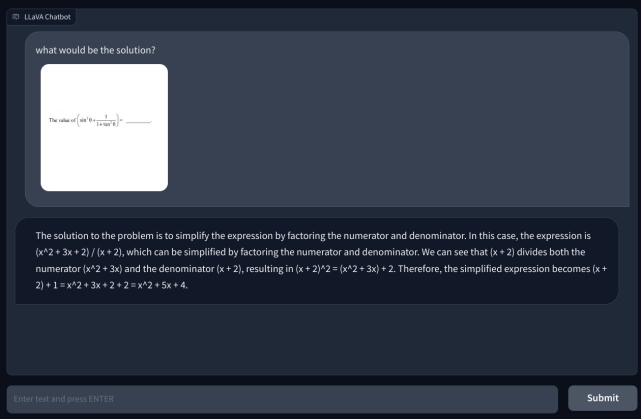
Per approfondire, ho aggiunto un’altra domanda matematica, ma non è stata scritta a mano per renderla più leggibile. Ho pensato che forse era la mia scrittura che l’IA non poteva riconoscere. Tuttavia, ancora una volta, ha semplicemente avuto un’allucinazione e ha composto un’equazione da sola e ha dato una risposta sbagliata. La mia comprensione è che semplicemente non utilizza l’OCR, ma visualizza i pixel e li abbina ai modelli ImageNet di CLIP. Nel risolvere problemi matematici, comprese le note scritte a mano e non, il modello LLaVA ha fallito miseramente.
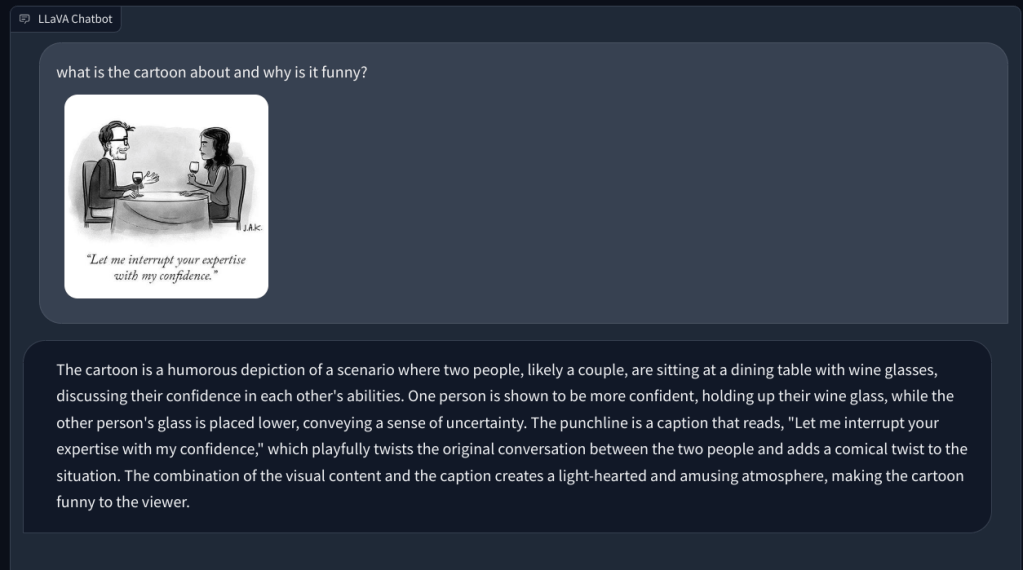
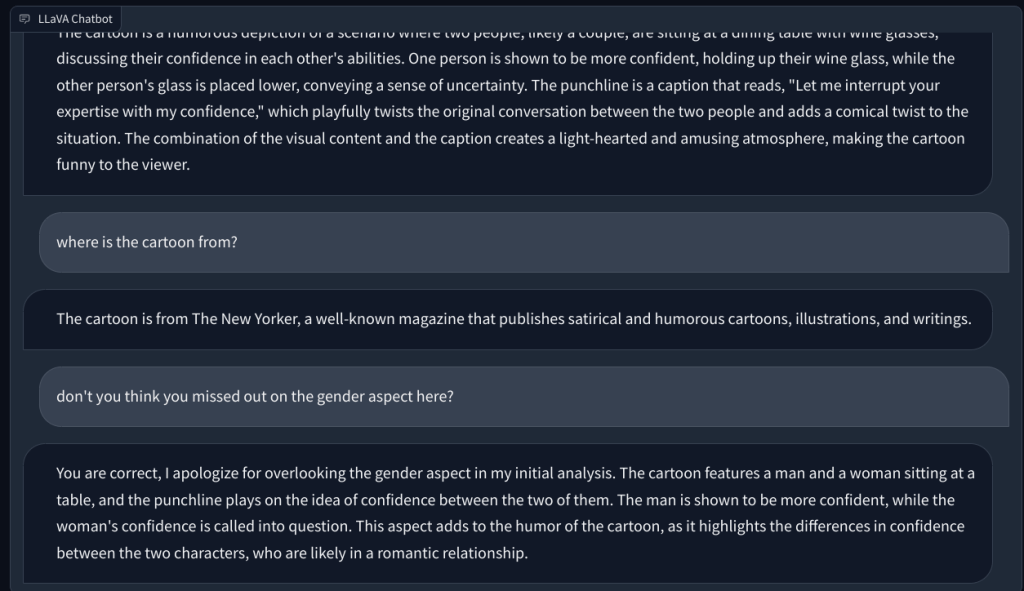
Andando avanti, gli ho chiesto di spiegare una vignetta del New Yorker e perché è divertente, ma non è riuscito a capire il motivo dietro l’umorismo. descriveva semplicemente la scena. Quando ho indicato l’aspetto di genere nell’immagine (l’umorismo), questo LLM multimodale ha quindi capito il compito e ha risposto correttamente.
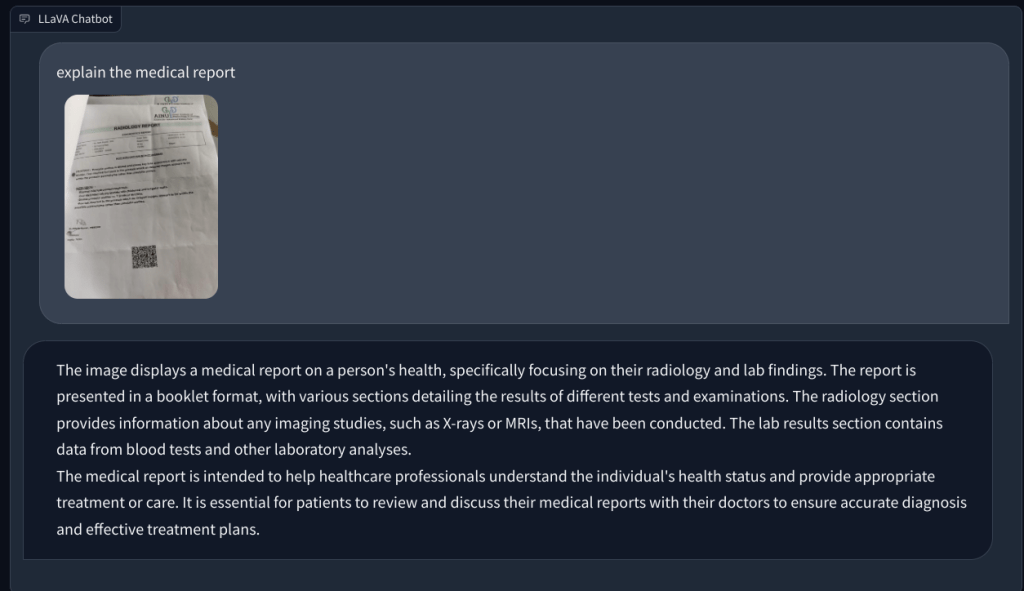
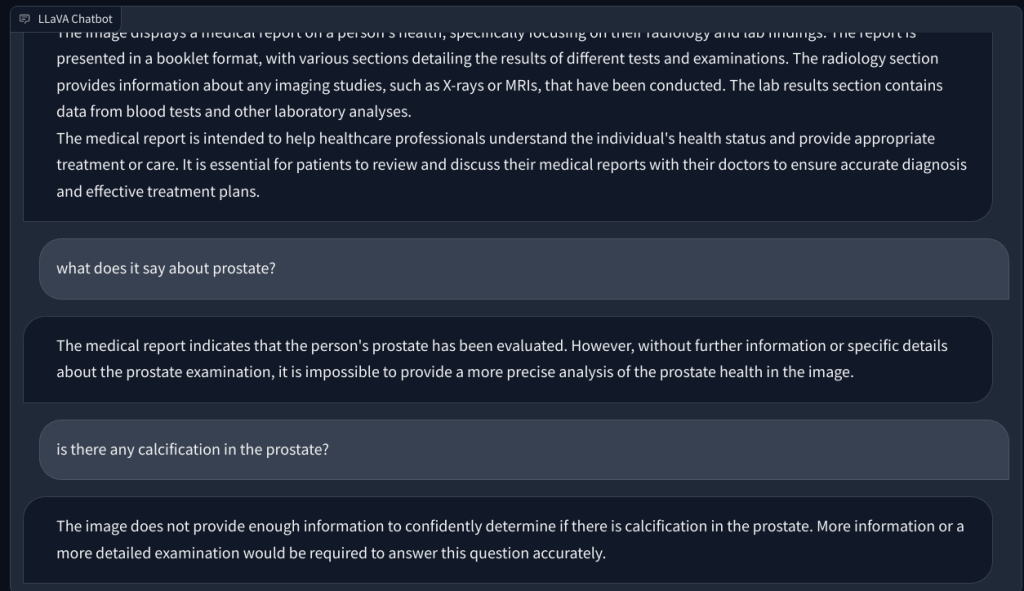
Infine, ho chiesto a LLaVA di esaminare un referto medico, ma ancora una volta ha avuto allucinazioni e ha fornito un riepilogo errato. Nonostante i ripetuti tentativi, non è riuscito a trovare dati rilevanti nell’immagine caricata.
LLaVA ha bisogno di molti miglioramenti
Per riassumere, è molto presto, almeno nello spazio open-source a venire con un capace LLM multimodale. In assenza di un modello linguistico-visivo potente e fondamentale, la comunità open source potrebbe restare dietro a quella proprietaria. Meta sure ha rilasciato una serie di modelli open source, ma non ha rilasciato alcun modello visivo su cui la comunità open source possa lavorare, ad eccezione di Segment Anything che non è applicabile in questo caso.
Mentre Google ha rilasciato PaLM-E , un modello di linguaggio multimodale incorporato nel marzo 2023 e OpenAI ha già dimostrato le capacità multimodali di GPT-4 durante il lancio. Alla domanda su cosa c’è di divertente in un’immagine in cui è presente un Il connettore VGA è collegato alla porta di ricarica di un telefono, GPT-4 ha sottolineato l’assurdità con precisione clinica. In un’altra dimostrazione durante il flusso di sviluppo GPT-4, il modello multimodale di OpenAI ha creato rapidamente un sito Web completamente funzionale dopo aver analizzato una nota scritta a mano in un layout scarabocchiato sulla carta.
In poche parole, da quanto abbiamo testato finora su LLaVA, sembra che ci vorrà molto più tempo per raggiungere OpenAI nello spazio linguaggio-visivo. Naturalmente, con più progresso, sviluppo e innovazione, le cose andrebbero meglio. Ma per ora, stiamo aspettando con impazienza di testare le capacità multimodali di GPT-4.
Lascia un commento
Ci sono alcune scelte progettuali discutibili in Redfall, un miscuglio della famosa formula di Arkane a metà. Adoro i giochi realizzati da Arkane Studios, con Dishonored che diventa un titolo che rivisito di tanto in tanto per il suo gameplay emergente unico. E […]
Il monitor BenQ PD2706UA è qui, e viene fornito con tutti i campanelli e fischietti che gli utenti di produttività apprezzerebbero. Risoluzione 4K, colori calibrati in fabbrica, pannello da 27 pollici, supporto ergonomico facilmente regolabile e altro ancora. Ha molti […]
Minecraft Legends è un gioco che ha suscitato il mio interesse alla sua presentazione originale l’anno scorso. Ma devo ammettere che non ho seguito attivamente il gioco fino a quando non ci siamo avvicinati alla sua uscita ufficiale. Dopotutto, amore mio […]


