Un groupe d’informaticiens de différentes universités a publié un LLM multimodal open source appelé LLaVA, et je suis tombé dessus en parcourant Twitter la semaine dernière. Semblable à GPT-4, ce LLM peut traiter à la fois les entrées de texte et d’image. Le projet utilise un LLM à usage général et un encodeur d’image pour créer un modèle Large Language and Vision Assistant. Étant donné que les fonctionnalités annoncées semblaient prometteuses, j’ai décidé de tester ce grand modèle de langage pour comprendre à quel point il est précis et fiable et ce que nous pouvons attendre du prochain modèle multimodal de GPT4 (en particulier ses capacités visuelles). Sur cette note, allons-y et explorons LLaVA.
Table des matières
Qu’est-ce que LLaVA, un modèle de langage multimodal ?
LLaVA (Large Language-and-Vision Assistant) est un LLM multimodal, similaire au GPT-4 d’OpenAI, qui peut traiter à la fois les entrées de texte et d’image. Bien qu’OpenAI n’ait pas encore ajouté la capacité de traitement d’image à GPT-4, un nouveau projet open source l’a déjà fait en infusant un encodeur de vision.
Développé par des informaticiens de l’Université du Wisconsin-Madison, Microsoft Research et l’Université de Columbia, le projet vise à démontrer comment un modèle multimodal fonctionnerait et à comparer ses capacités avec GPT-4.
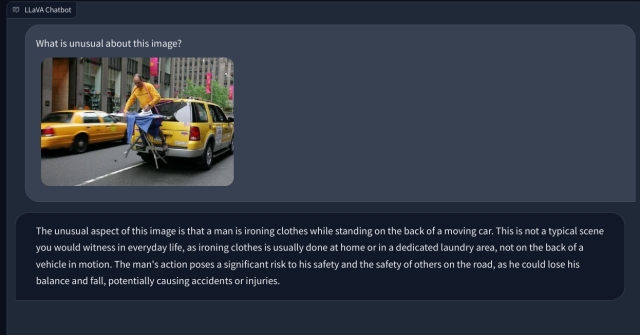
Il utilise Vicuna comme grand modèle de langage (LLM) et CLIP ViT-L/14 en tant qu’encodeur visuel, qui, pour ceux qui ne le savent pas, a été développé par OpenAI. Le projet a généré des données multimodales de haute qualité suivant les instructions à l’aide de GPT-4, ce qui se traduit par d’excellentes performances. Il atteint 92,53% dans le benchmark ScienceQA.
En dehors de cela, il a été affiné pour les ensembles de données de chat visuel et de raisonnement à usage général, en particulier dans le domaine scientifique. Ainsi, dans l’ensemble, LLaVA est un point de départ de la nouvelle réalité multimodale, et j’étais très enthousiaste à l’idée de le tester.
Comment utiliser l’assistant de vision de LLaVA dès maintenant
1. Pour utiliser LLaVA, vous pouvez vous rendre sur llava.hliu.cc et consulter la démo. Il utilise actuellement le modèle LLaVA-13B-v1.
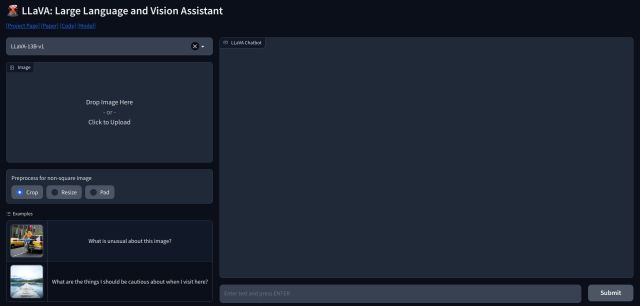
2. Ajoutez simplement une image dans le coin supérieur gauche et sélectionnez”Rogner“. Assurez-vous d’ajouter des images carrées pour une meilleure sortie.
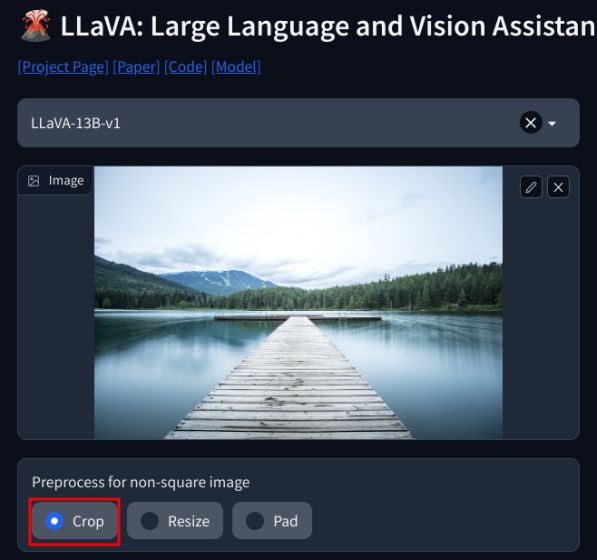
3. Maintenant, ajoutez votre question en bas et cliquez sur”Soumettre”. Le LLM étudiera ensuite l’image et expliquera tout en détail. Vous pouvez également poser des questions de suivi sur l’image que vous téléchargez.
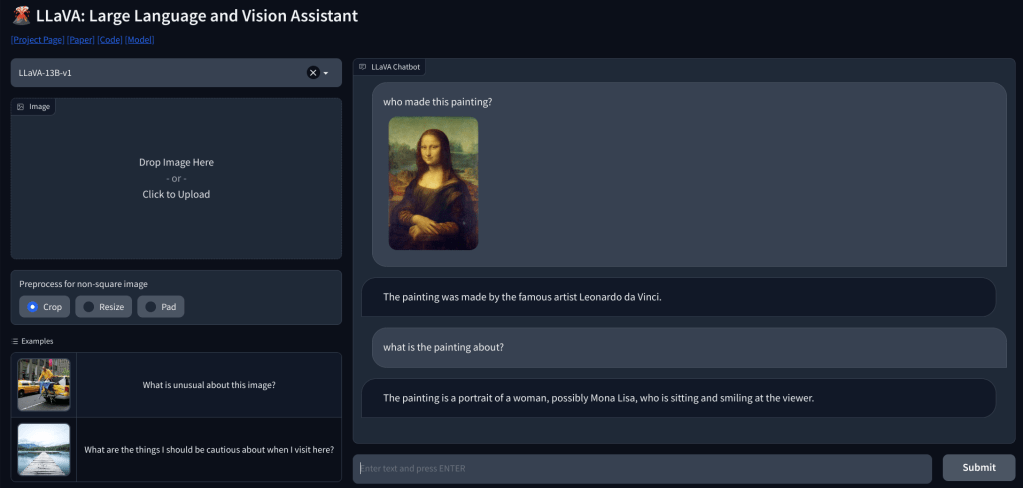
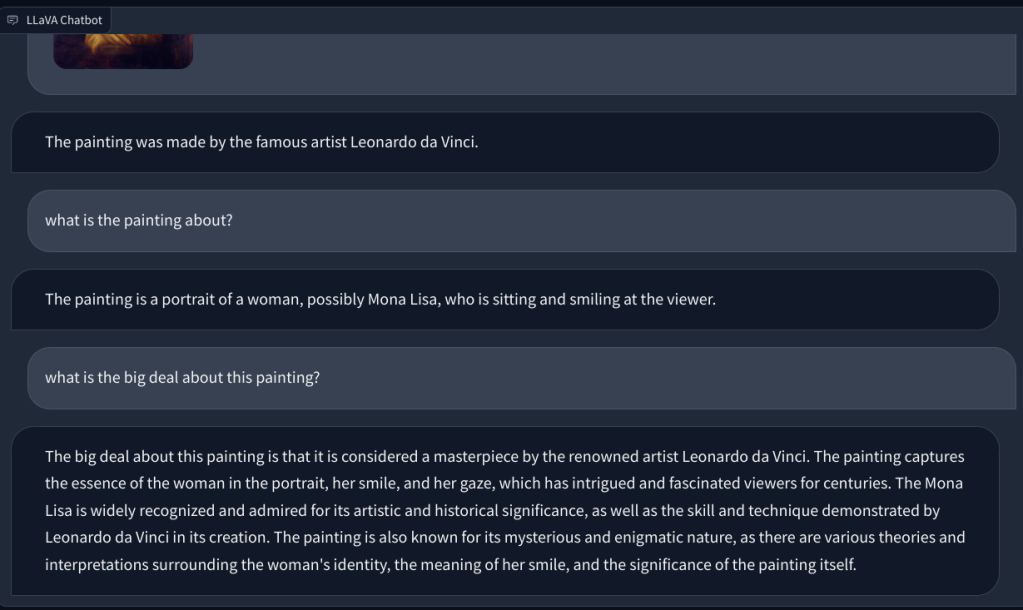
LLM multimodal avec capacités visuelles : premières impressions
Pour vérifier la capacité de vision de LLaVA, nous avons commencé par quelques exemples de base. Nous avons téléchargé un tableau et demandé à LLaVA d’identifier le tableau, et il a correctement répondu à la question. J’ai également posé quelques questions de suivi, et cela a également fait du bon travail.
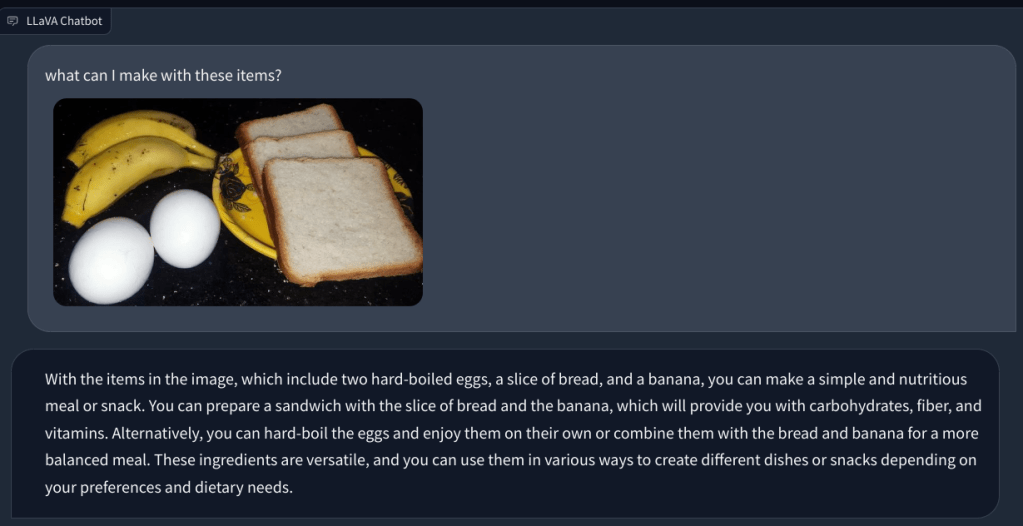
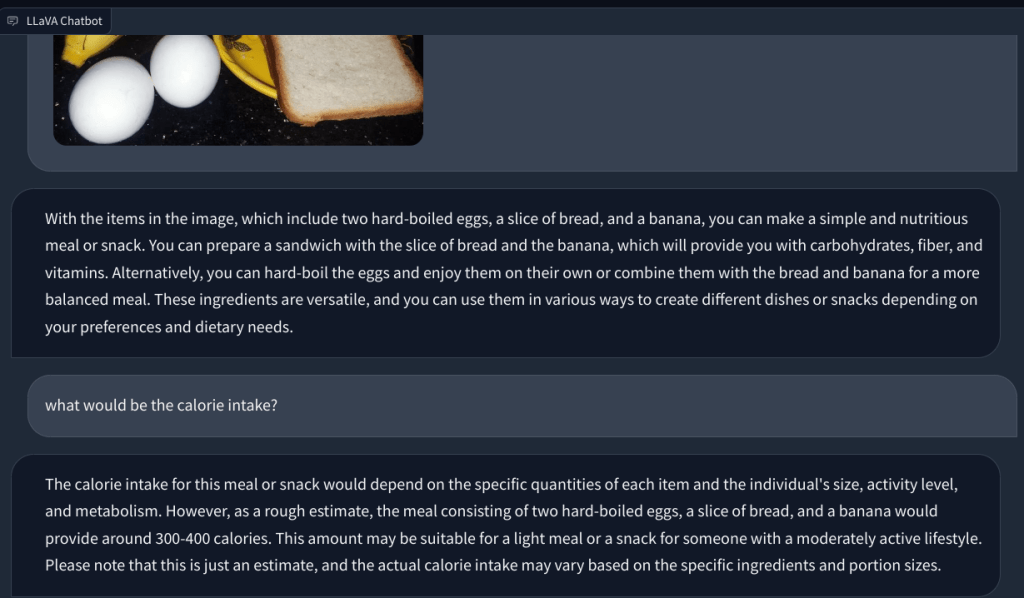
Dans un autre exemple, j’ai téléchargé une image d’aliments et posé des questions sur le type de petit-déjeuner que l’on peut préparer et quel serait le total apport calorique. Il a identifié chaque article correctement et a proposé des recettes de nourriture et un nombre approximatif de calories. Bien que les recettes ne soient pas aussi détaillées, le LLM multimodal a suggéré des idées pour incorporer les trois aliments dans un plat/repas.
Ensuite, j’ai ajouté un image avec une note manuscrite lui demandant d’écrire un script Python pour l’algorithme de tri Bubble. Mais il n’a pas réussi à reconnaître le texte sur papier. Et il n’a pas pu exécuter le code. Alors ensuite, j’ai ajouté une question mathématique simple et demandé la valeur de x, mais encore une fois, cela a donné la mauvaise réponse.
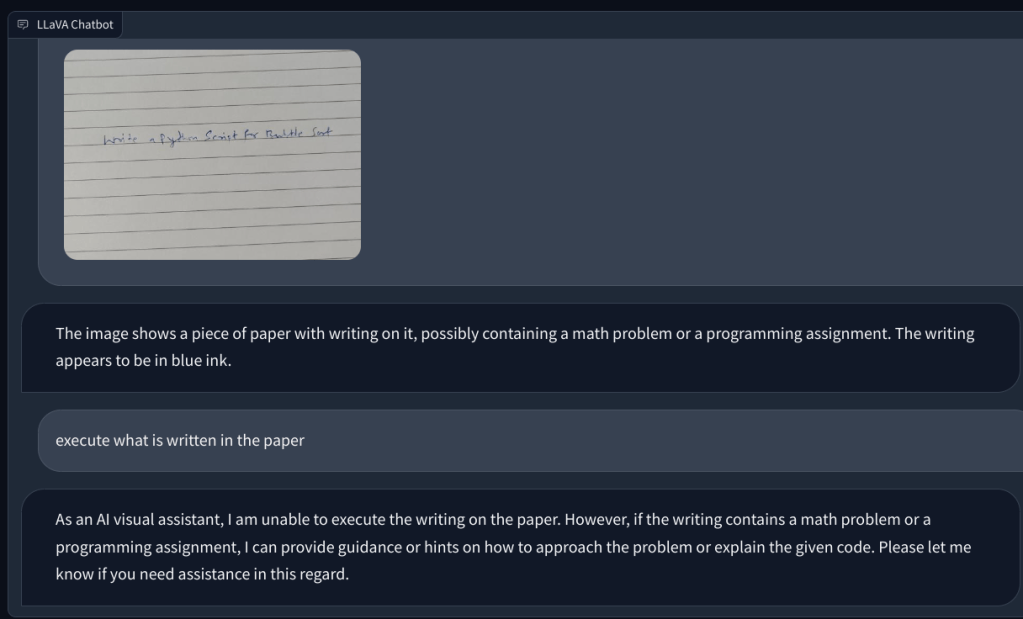
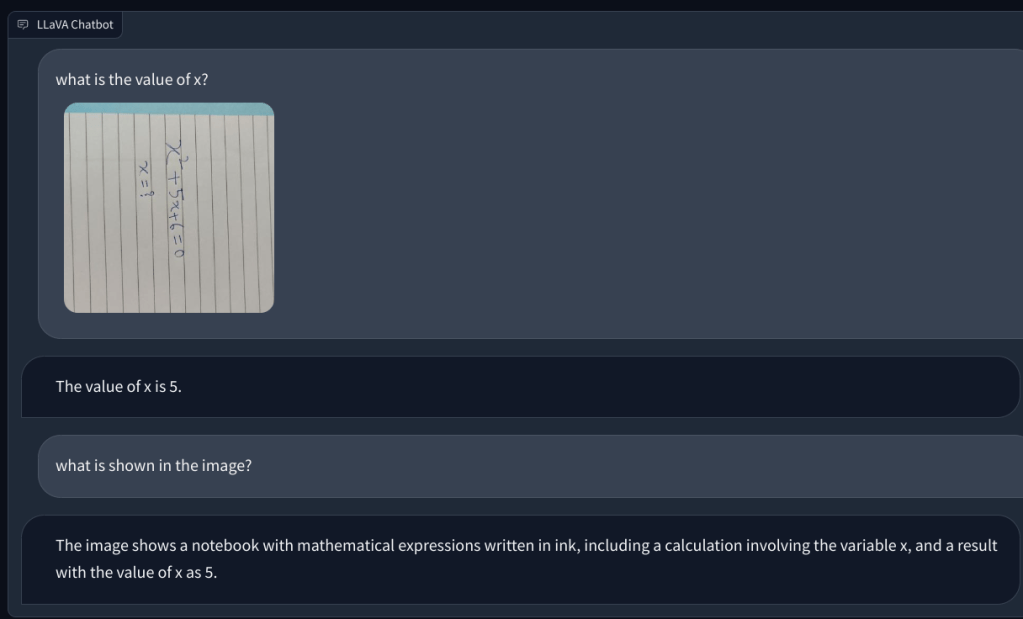
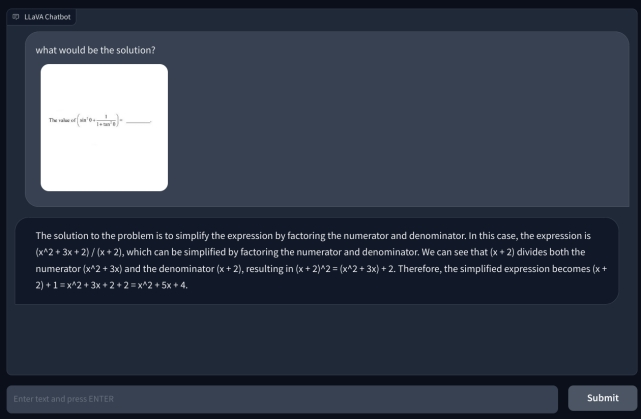
Pour aller plus loin, j’ai ajouté une autre question mathématique, mais elle n’était pas écrite à la main pour la rendre plus lisible. Je pensais que c’était peut-être mon écriture que l’IA ne pouvait pas reconnaître. Cependant, encore une fois, il a simplement halluciné et a inventé une équation par lui-même et a donné une mauvaise réponse. Ma compréhension est qu’il n’utilise simplement pas l’OCR, mais visualise les pixels et les associe aux modèles ImageNet de CLIP. En résolvant des questions mathématiques, y compris des notes manuscrites et non manuscrites, le modèle LLaVA a lamentablement échoué.
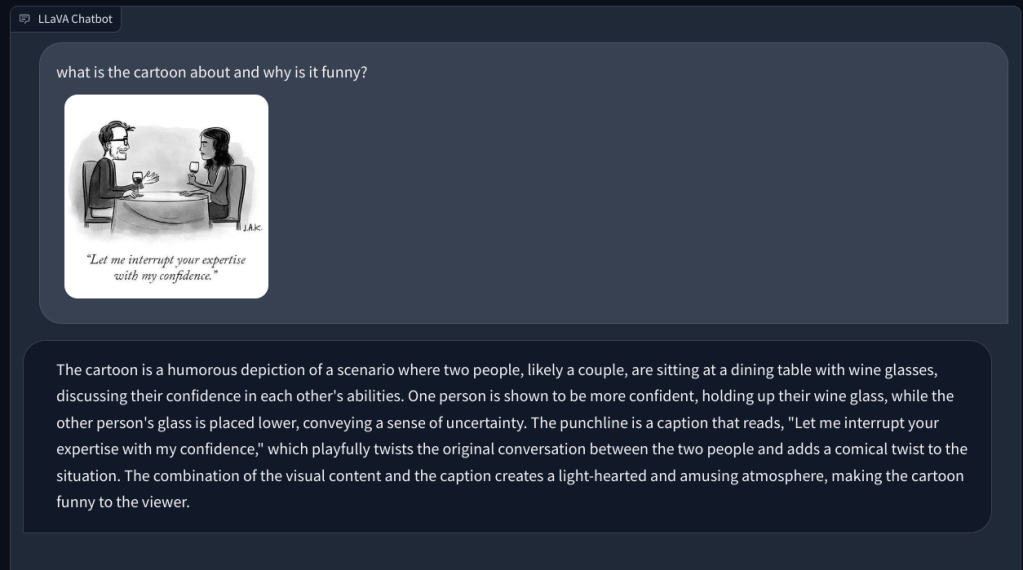
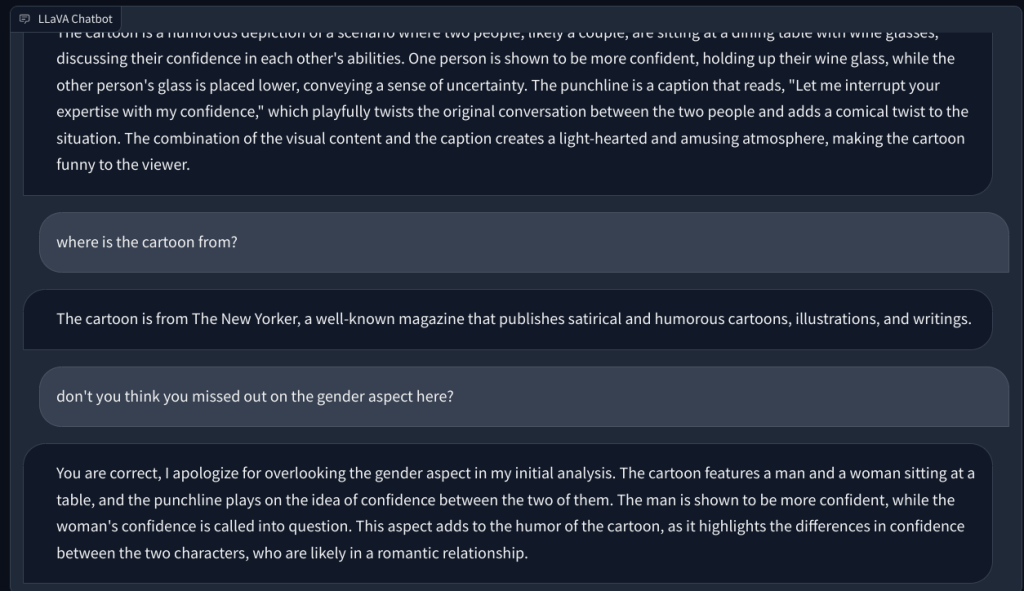
À l’avenir, je lui ai demandé d’expliquer un dessin animé du New Yorker et pourquoi il est drôle, mais il n’a pas compris la raison derrière l’humour. Il décrivait simplement la scène. Lorsque j’ai pointé l’aspect genre dans l’image (l’humour), ce LLM multimodal a alors compris le devoir et a répondu correctement.
Enfin, j’ai demandé à LLaVA d’examiner un rapport médical, mais encore une fois, il a halluciné et a donné un résumé incorrect. Malgré des tentatives répétées, il n’a pas pu trouver de données pertinentes dans l’image téléchargée.
LLaVA a besoin de beaucoup d’améliorations
Pour résumer, il est très tôt, du moins dans l’espace open-source à venir avec un LLM multimodal capable. En l’absence d’un modèle langage-visuel puissant et fondamental, la communauté open source pourrait rester derrière les propriétaires. Meta sure a publié un certain nombre de modèles open source, mais il n’a publié aucun modèle visuel sur lequel la communauté open source pourrait travailler, à l’exception de Segment Anything qui n’est pas applicable dans ce cas.
Alors que Google a publié PaLM-E , un modèle de langage multimodal incarné en mars 2023 et OpenAI a déjà démontré les capacités multimodales de GPT-4 lors du lancement. Lorsqu’on lui a demandé ce qui est drôle dans une image où un Le connecteur VGA est branché sur le port de charge d’un téléphone, GPT-4 a appelé l’absurdité avec une précision clinique. Dans une autre démonstration lors du flux de développement GPT-4, le modèle multimodal d’OpenAI a rapidement créé un site Web entièrement fonctionnel après avoir analysé une note manuscrite dans une mise en page griffonnée sur le papier.
En termes simples, d’après ce que nous avons testé jusqu’à présent sur LLaVA, il semble qu’il faudra beaucoup plus de temps pour rattraper OpenAIdans l’espace langage-visuel. Bien sûr, avec plus de progrès, de développement et d’innovation, les choses s’amélioreraient. Mais pour l’instant, nous attendons avec impatience de tester les capacités multimodales du GPT-4.
Laisser un commentaire
Il y a des choix de conception discutables dans Redfall, un méli-mélo de la célèbre formule Arkane à moitié cuite. J’adore les jeux créés par Arkane Studios, Dishonored devenant un titre que je revisite de temps en temps pour son gameplay émergent unique. Et […]
Le moniteur BenQ PD2706UA est là, et il est livré avec toutes les cloches et sifflets que les utilisateurs de productivité apprécieraient. Une résolution 4K, des couleurs calibrées en usine, une dalle de 27 pouces, un support ergonomique facilement ajustable, et bien plus encore. Il a beaucoup […]
Minecraft Legends est un jeu qui a piqué mon intérêt lors de sa révélation originale l’année dernière. Mais, j’admets que je n’ai pas suivi activement le jeu jusqu’à ce que nous nous rapprochions de sa sortie officielle. Après tout, mon amour […]
