.fb-comments,.fb-comments span,.fb-comments span iframe[style]{min-width:100%!important;width:100%!important} 
Sql vector créé par freepik – www.freepik.com
SQL (Structured Query Language) est un outil très important dans la boîte à outils d’un data scientist. Maîtriser SQL est non seulement essentiel d’un point de vue entretien, mais une bonne compréhension de SQL en étant capable de résoudre des requêtes complexes nous maintiendra au-dessus de tout le monde dans la course.
Dans cet article, je parlerai de 5 questions délicates que j’ai trouvées et mes approches pour les résoudre.
Remarque : Chaque requête peut être rédigée de différentes manières. Essayez de réfléchir à l’approche avant de passer à mes solutions. Vous pouvez également suggérer différentes approches dans la section réponse.
On nous donne un tableau composé de deux colonnes, Nom et Profession. Nous devons interroger tous les noms immédiatement suivis de la première lettre dans la colonne de la profession entre parenthèses.
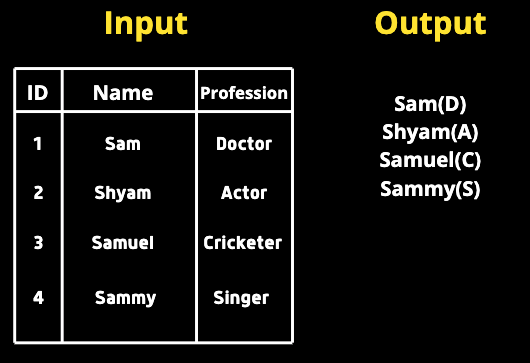
Ma solution
SELECT CONCAT(Nom,'(‘, SUBSTR( Profession, 1, 1),’)’) table FROM ;
Puisque nous devons combiner le nom et la profession, nous pouvons utiliser CONCAT. Nous devons également n’avoir qu’une seule lettre entre les parenthèses. Par conséquent, nous utiliserons SUBSTR et transmettrons le nom de la colonne, l’index de début et l’index de fin. Comme nous n’avons besoin que de la première lettre, nous passerons 1,1 (l’index de début est inclus et l’index de fin n’est pas inclus)
Tina a été invitée à calculer le salaire moyen de tous les employés à partir des EMPLOYÉS tableau qu’elle a créé mais s’est rendu compte que la touche zéro de son clavier ne fonctionnait pas après que le résultat ait montré une moyenne très inférieure. Elle veut notre aide pour trouver la différence entre la moyenne mal calculée et la moyenne réelle.
Nous devons écrire une requête pour trouver l’erreur (AVG réelle-AVG calculée).
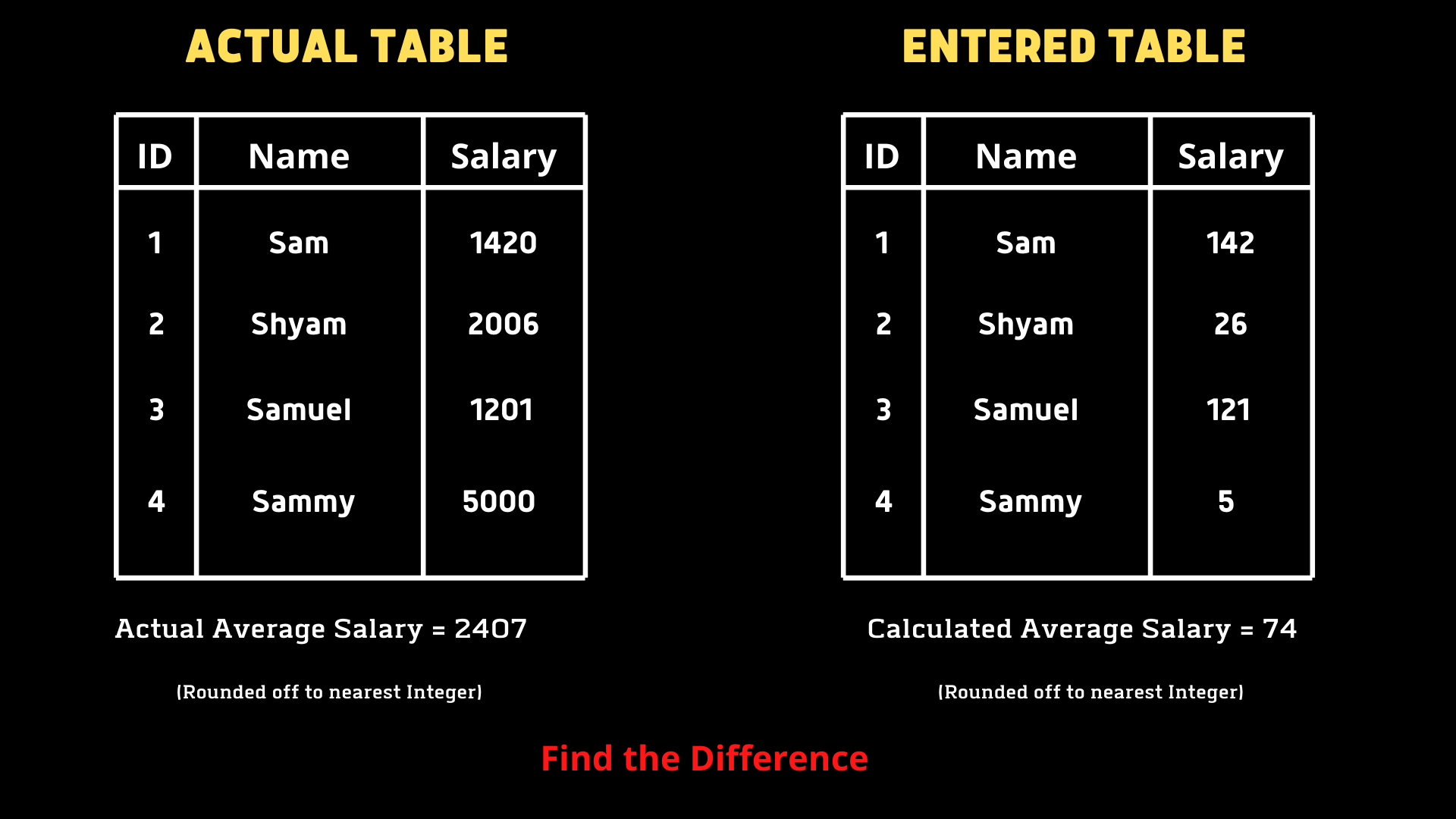
Ma solution
SELECT AVG(Salaire)-AVG(REPLACE(Salaire, 0,”)) DE table;
Un point à noter ici est que nous n’avons qu’un seul tableau qui se compose des valeurs salariales réelles. Pour créer le scénario d’erreur, nous utilisons REPLACE pour remplacer les 0. Nous transmettrons le nom de la colonne, la valeur à remplacer et la valeur par laquelle nous remplacerons la méthode REPLACE. Ensuite, nous trouvons la différence dans les moyennes à l’aide de la fonction d’agrégat AVG.
On nous donne un tableau, qui est un Arbre de recherche binaire composé de deux colonnes Nœud et Parent. Nous devons écrire une requête qui renvoie le type de nœud trié par la valeur des nœuds dans l’ordre croissant. Il existe 3 types.
Root — si le nœud est une racine Leaf — si le nœud est une feuille Inner — si le nœud n’est ni racine ni feuille.
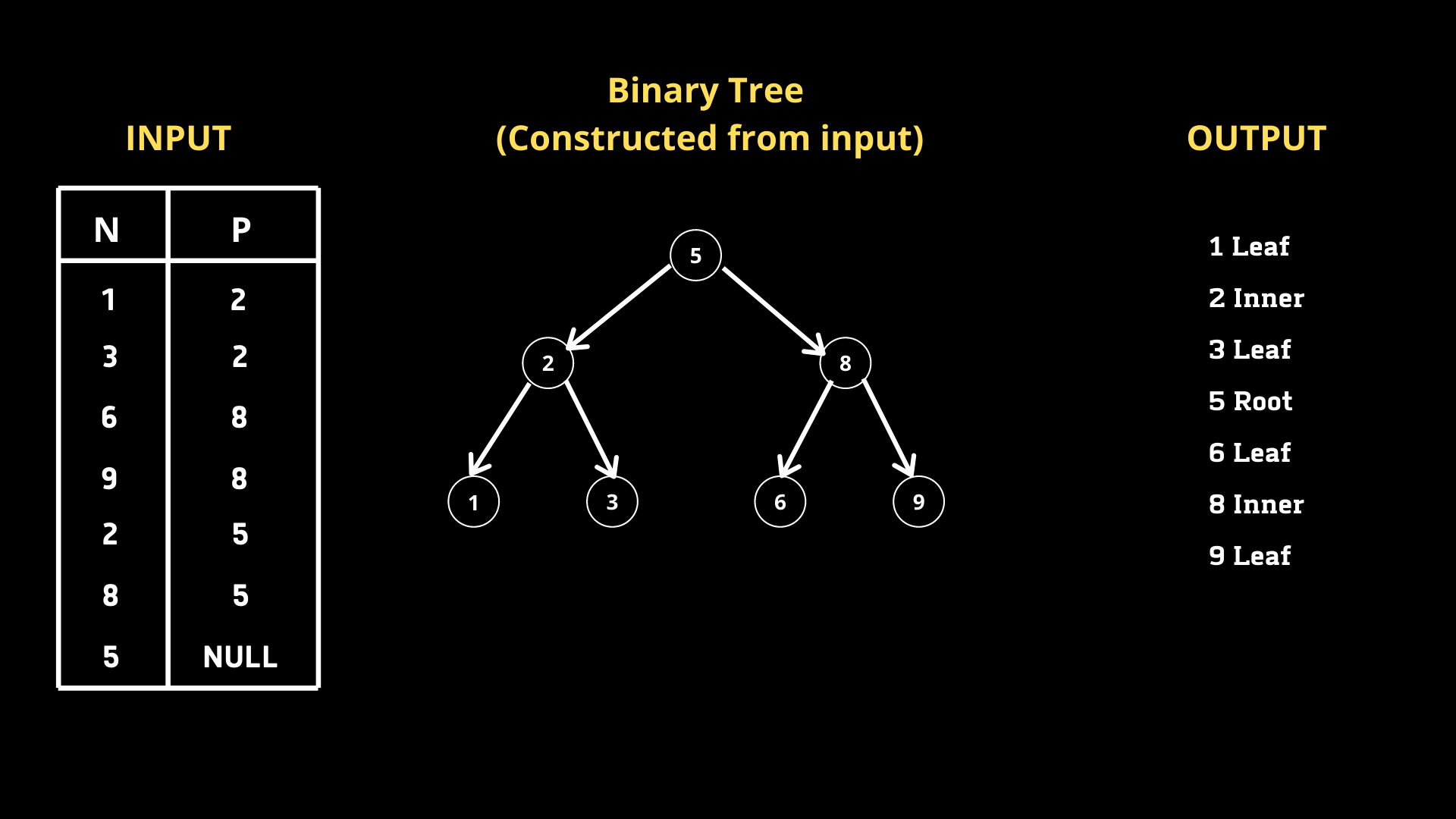
Ma solution
Lors de l’analyse initiale, nous pouvons conclure que si un nœud donné N a sa valeur P correspondante égale à NULL, il s’agit de la racine. Et pour un nœud N donné, s’il existe dans la colonne P, ce n’est pas un nœud interne. Sur la base de cette idée, écrivons une requête.
SELECT CASE WHEN P IS NULL THEN CONCAT(N,’Root’) WHEN N IN (SELECT DISTINCT P from BST) THEN CONCAT(N,’Inner’) ELSE CONCAT(N,’Leaf’) END DE BST ORDER BY N asc ;
Nous pouvons utiliser CASE qui agit comme une fonction de commutation. Comme je l’ai mentionné, si P est nul pour un nœud donné N, alors N est la racine. Par conséquent, nous avons utilisé CONCAT pour combiner la valeur du nœud et l’étiquette. De même, si un nœud donné N est dans la colonne P, il s’agit d’un nœud interne. Pour obtenir tous les nœuds de la colonne P, nous avons écrit une sous-requête qui renvoie tous les nœuds distincts de la colonne P. Puisqu’on nous a demandé de trier la sortie par valeurs de nœud dans l’ordre croissant, nous avons utilisé la clause ORDER BY.
Nous recevons une table de transactions composée de transaction_id, user_id, transaction_date, product_id et quantité. Nous devons interroger le nombre d’utilisateurs qui ont acheté des produits sur plusieurs jours (notez qu’un utilisateur donné peut acheter plusieurs produits sur une seule journée).
Ma solution
Pour résoudre cette requête, nous ne pouvons pas compter directement l’occurrence de user_id et s’il y en a plusieurs, retournez cet user_id car un utilisateur donné peut avoir plus d’une transaction en une seule journée. Par conséquent, si un user_id donné a plus d’une date distincte qui lui est associée, cela signifie qu’il a acheté des produits sur plusieurs jours. Suivant la même approche, j’ai écrit une requête. (Requête interne)
SELECT COUNT(user_id) FROM ( SELECT user_id FROM commandes GROUP BY user_id HAVING COUNT(DISTINCT DATE(date)) > 1 ) t1
Puisque la question demandait le nombre d’user_ids et non les user_ids lui-même, nous utilisons COUNT dans la requête externe.
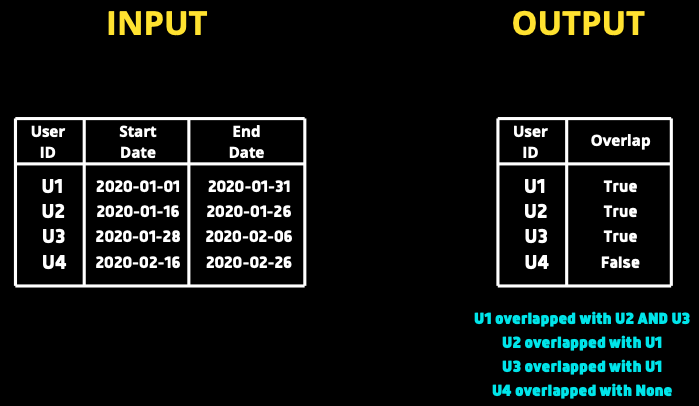
Nous recevons une table d’abonnement qui se compose de la date de début et de fin d’abonnement pour chaque utilisateur. Nous devons écrire une requête qui renvoie vrai/faux pour chaque utilisateur en fonction du chevauchement des dates avec d’autres utilisateurs. Par exemple, si la période d’abonnement de l’utilisateur1 chevauche celle d’un autre utilisateur, la requête doit renvoyer Vrai pour l’utilisateur1.
Ma solution
Lors de l’analyse initiale, nous comprenons que nous devons comparer chaque abonnement entre eux. Considérons les dates de début et de fin de userA comme startA et endA, de même pour userB,startB et endB.
Si startA≤endB et endA≥startB alors nous pouvons dire que les deux plages de dates se chevauchent. Prenons deux exemples. Commençons par comparer U1 ET U3.
startA =2020–01–01
endA =2020–01–31
startB =2020–01–16
endB =2020–01 –26
Ici, nous pouvons voir startA(2020–01–01) est inférieur à endB(2020–01 –26) et de même, endA(2020–01–31) est supérieur à startB(2020–01–16) et peut donc conclure que les dates se chevauchent. De même, si vous comparez U1 et U4, la condition ci-dessus échoue et renverra faux.
Nous devons également nous assurer qu’un utilisateur n’est pas comparé à son propre abonnement. Nous voulons également exécuter une jointure gauche sur elle-même pour faire correspondre un utilisateur avec un autre utilisateur qui satisfait notre condition. Nous allons maintenant créer deux répliques s1 et s2 de la même table.
SELECT * FROM abonnements AS s1 LEFT JOIN abonnements AS s2 ON s1.user_id !=s2.user_id AND s1.start_date <=s2.end_date AND s1.end_date >=s2.start_date
Compte tenu de la jointure conditionnelle, un user_id de s2 doit exister pour chaque user_id dans s1 à condition qu’il existe un chevauchement entre les dates.
Sortie

Nous pouvons voir qu’il existe un autre utilisateur pour chaque utilisateur au cas où les dates se chevauchent. Pour user1, il y a 2 lignes indiquant qu’il correspond à 2 utilisateurs. Pour l’utilisateur 4, l’identifiant correspondant est nul, indiquant qu’il ne correspond à aucun autre utilisateur.
En résumant tout cela maintenant, nous pouvons regrouper par le champ s1.user_id et vérifier simplement si une valeur existe pour un utilisateur où s2.user_id N’EST PAS NULL.
Requête finale
SELECT s1.user_id , (CAS WHEN s2.user_id IS NOT NULL THEN 1 ELSE 0 END) AS chevauchent les abonnements FROM AS s1 LEFT JOIN les abonnements AS s2 ON s1.user_id !=s2.user_id AND s1.start_date <=s2.end_date AND s1.end_date >=s2.start_date GROUP BY s1.user_id
Nous avons utilisé la clause CASE pour étiqueter 1 et 0 en fonction de la valeur s2.user_id pour un utilisateur donné. La sortie finale ressemble à ceci –

Avant de conclure, je voudrais suggérer un bon livre sur SQL que j’ai beaucoup apprécié et trouvé très utile.
SQL Cookbook : Query Solutions and Techniques for Database )
Maîtriser SQL nécessite beaucoup de pratique. Dans cet article, j’ai pris 5 questions délicates et expliqué les approches pour les résoudre. La spécialité de SQL est que chaque requête peut être écrite de différentes manières. N’hésitez pas à partager vos approches dans les réponses. J’espère que vous avez appris quelque chose de nouveau aujourd’hui !
Si vous souhaitez entrer en contact, contactez-moi sur LinkedIn.
Original. Republié avec permission.
Saiteja Kura est sincère, amical et ambitieux, et s’intéresse au développement Web, à la science des données et au TAL.
Notez ce message
Partager, c’est s’engager !

